Top Spark Ecosystem Projects
Apache Spark has developed a rich ecosystem, including both official and third party tools. We have a look at 5 third party projects which complement Spark in 5 different ways.
Apache Spark is now the largest open source data processing project, with more than 750 contributors from over 200 organizations.
Developed at AMPLab at UC Berkeley, Spark is now a top-level Apache project, and is overseen by Databricks, the company founded by Spark's creators. These 2 organizations work together to move Spark development forward. Matei Zaharia, VP of Apache Spark and Founder & CTO of Databricks, says this of the development relationship:
At Databricks, we’re working hard to make Spark easier to use and run than ever, through our efforts on both the Spark codebase and support materials around it. All of our work on Spark is open source and goes directly to Apache.
Sometimes seen as competition to Hadoop (but not at all necessarily so), Spark has managed to benefit indirectly from lessons learned from the development growing pains of Hadoop, given that Hadoop is nearly a decade older. Spark has, thus, built a tight ecosystem of official tools which work well to provide a variety of processing capabilities.
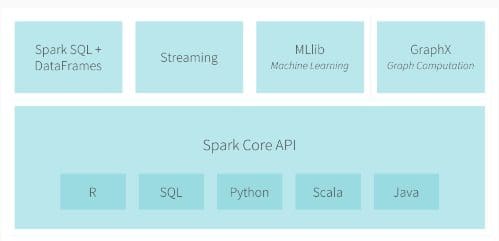
Spark's official ecosystem consists of the following major components (descriptions taken from the official Spark documentation):
- Spark DataFrames - a distributed collection of data organized into named columns, similar to a relational table
- Spark SQL - execute SQL queries written using either a basic SQL syntax or HiveQL, and read data from an existing Hive installation
- Spark Streaming - an extension of the core Spark API that enables scalable, high-throughput, fault-tolerant stream processing of live data streams
- MLlib - Spark's machine learning library, consisting of common learning algorithms and utilities, including classification, regression, clustering, collaborative filtering, dimensionality reduction, and more
- GraphX - a new component in Spark for graphs and graph-parallel computation
- Spark Core API - provides APIs for a variety of commonly-used languages: R, SQL, Python, Scala, Java
There are a number of additional projects which are not part of the official ecosystem, however, and which have become (or are becoming) innovative in their own right or must-have additions under certain circumstances. It is these projects which we will give treatment today. There are no qualitative metrics used here; this is simply a list of projects that have been observed for their usefulness in some way or another, or have been subjectively noted as popular.
What follows are 5 selected projects which have been deemed useful for Spark. Use cases are given, as are resources to learn more about both the projects and their interaction with Spark.
1. Mesos
Apache Mesos is an open source cluster manager born out of the AMPLab at UC Berkeley. From its website:
Apache Mesos abstracts CPU, memory, storage, and other compute resources away from machines (physical or virtual), enabling fault-tolerant and elastic distributed systems to easily be built and run effectively.
Mesos runs on nodes of a cluster and provides an APIs to applications for managing and scheduling resources. This is of consequence to Spark users, as Mesos is one of the cluster configurations in which Spark can operate. Spark's official documentation even includes information on Mesos as a cluster manager.
Why use Mesos over Spark standalone or YARN? From Learning Spark, written by Spark developers from Databricks (including some co-founders):
One advantage of Mesos over both YARN and standalone mode is its fine-grained sharing option, which lets interactive applications such as the Spark shell scale down their CPU allocation between commands. This makes it attractive in environments where multiple users are running interactive shells.
Here is a video from Spark Summit 2015 in San Francisco which discusses running Spark on top of Mesos.
2. Spark Cassandra Connector
Cassandra is highly scalable, high performance database management software. The Spark Cassandra Connector project is actively-developed open source software which allows Spark to interact with Cassandra tables. From its Github repository:
This library lets you expose Cassandra tables as Spark RDDs, write Spark RDDs to Cassandra tables, and execute arbitrary CQL queries in your Spark applications.
The Spark Cassandra Connector takes care of the configuration to connect Spark with Cassandra. This was previously possible via some hard work on your own, or using the Spark Hadoop API.
You can find a very detailed overview of configuring the Spark Cassandra Connector and using it from within a Spark program here.
3. Zepellin
Zepellin is an interesting Spark project which is currently a member of the Apache Incubator. Zepellin is working to bring integrated IPython (Jupyter) style notebooks to the Spark ecosystem. There are existing alternatives to this, but they are (however well) after-the-fact solutions. Zepellin is built from the ground up with Spark, Scala, and related technologies in mind, without reliance on Jupyter. Worth noting, it allows for direct and easy publishing of code execution results in your hosted blog or website as an embedded iframe.
From the project website:
A web-based notebook that enables interactive data analytics.
You can make beautiful data-driven, interactive and collaborative documents with SQL, Scala and more.
The Zepellin interpreter allows for additional language plugins. The currently-supported languages include Scala (with Spark), Python (with Spark), SparkSQL, Hive, Markdown, and Shell.
4. Spark Job Server
Spark Job Server is a succinct and accurate title for this project. From the Github repository:
spark-jobserver provides a RESTful interface for submitting and managing Apache Spark jobs, jars, and job contexts. This repo contains the complete Spark job server project, including unit tests and deploy scripts. It was originally started at Ooyala, but this is now the main development repo.
Why use Spark Job Server? The RESTful interface allows jobs to be submitted from any language or environment, with job context being handled by the job server.
Spark Job Server is an active project, and its repo includes a wealth of useful information.
5. Alluxio (formerly Tachyon)
Alluxio defines itself as "a memory speed virtual distributed storage system." Formerly known as Tachyon, Alluxio sits between computation frameworks, such as Apache Spark, and various types of storage systems, including Amazon S3, HDFS, Ceph, and others. Spark jobs can run on Alluxio without any changes, to which Alluxio can provide significant performance increases. Alluxio claims that "Baidu uses Alluxio to improve their data analytics performance by 30 times."
From their website:
Alluxio is an open source memory-centric distributed storage system enabling reliable data sharing at memory-speed across cluster jobs, possibly written in different computation frameworks, such as Apache Spark, Apache MapReduce, and Apache Flink.
This article discusses the benefits of using Alluxio (then Tachyon) as an in-memory storage layer for data, and touts how, in one case, it is the key to moving data from a central warehouse to Spark for processing.
Related: