Decision Tree Classifiers: A Concise Technical Overview
The decision tree is one of the oldest and most intuitive classification algorithms in existence. This post provides a straightforward technical overview of this brand of classifiers.
As I'm sure you are undoubtedly aware, decision trees are a type of flowchart which assist in the decision making process. Internal nodes represent tests on particular attributes, while branches exiting nodes represent a single test outcome, and leaf nodes represent class labels.
In machine learning, decision trees have been used for decades as effective and easily understandable data classifiers (contrast that with the numerous blackbox classifiers in existence). Over the years, a number of decision tree algorithms have resulted from research, 3 of the most important, influential, and well-used being:
- Iterative Dichotimiser 3 (ID3) - Ross Quinlan's precursor to the C4.5
- C4.5 - one of the most popular classifiers of all time, also from Quinlan
- CART - independently invented around the same time as C4.5, also still very popular
ID3, C4.5, and CART all adopt a top-down, recursive, divide-and-conquer approach to decision tree induction.
Over the years, C4.5 has become a benchmark against which the performance of newer classification algorithms are often measured. Quinlan’s original implementation contains proprietary code; however, various open-source versions have been coded over the years, including the (at one time very popular) Weka Machine Learning Toolkit's J48 decision tree algorithm.
For this overview of decision trees, we will consider the ID3 algorithm for simplicity, and point out any differences or caveats as warranted.
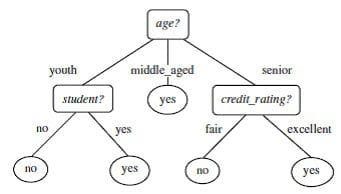
Fig.1: 'Buys Computer?' Decision Tree (Han, Kamber & Pei).
Decision Tree Induction
The model- (or tree-) building aspect of decision tree classification algorithms are composed of 2 main tasks: tree induction and tree pruning. Tree induction is the task of taking a set of pre-classified instances as input, deciding which attributes are best to split on, splitting the dataset, and recursing on the resulting split datasets until all training instances are categorized.
While building our tree, the goal is to split on the attributes which create the purest child nodes possible, which would keep to a minimum the number
of splits that would need to be made in order to classify all instances in our dataset. This purity is generally measured by one of a number of different attribute selection measures.

Fig.2: Decision Tree Induction Algorithm.
Attribute Selection Measures
There are 3 prominent attribute selection measures for decision tree induction, each paired with one of the 3 prominent decision tree classifiers.
- Information gain - used in the ID3 algorithm
- Gain ratio - used in the C4.5 algorithm
- Gini index - used in the CART algorithm
In ID3, purity is measured by the concept of information gain, based on the work of Claude Shannon, which relates to how much would need to be known about a previously-unseen instance in order for it to be properly classified. In practice, this is measured by comparing entropy, or the amount of information needed to classify a single instance of a current dataset partition, to the amount of information to classify a single instance if the current dataset partition were to be further partitioned on a given attribute.
A mouthful, to be sure, but the simple calculations of entropy followed by the required number of information gain comparisons is enough to tell us how much is actually gained if we were to branch on a given attribute, or "the expected reduction in the information requirement caused by knowing the value of [attribute] A" (Han, Kamber & Pei).
That attribute which provides the maximum information gain becomes the attribute upon which to split this partition (the single attribute upon which to split the partition, if we are talking binary decision trees).
Decision tree induction, then, is this process of constructing a decision tree from a set of training data and these above computations.
While I had considered adding these calculations to this post, I concluded that it would get too overly-detailed and become more in-depth than intended. However, for those interested, a good explanation and example of computing entropy and information gain can be found in this Stack Overflow
Decision Tree Raising
A completed decision tree model can be overly-complex, contain unnecessary structure, and be difficult to interpret. Tree pruning is the process of removing the unnecessary structure from a decision tree in order to make it more efficient, more easily-readable for humans, and more accurate as well.
This increased accuracy is due to pruning’s ability to reduce overfitting. Overfitting refers to the idea that models built from algorithms are too specifically-tailored to the particular training dataset that was used to generate them. While these models may do very well at categorizing said training data, overfitted models would perform poorly on another set of unseen testing data. Overfitting is not the sole concern of decision trees; the potential to overfit applies to nearly all machine learning classification algorithms.
There are different approaches to pruning. The C4.5 pruning method is post-pruning, with subtree raising. This means that pruning occurs after the tree has been constructed, as opposed to pre-pruning, and involves subtree raising, as opposed to subtree replacement, an alternative form of pruning. Subtree raising entails raising entire subtrees to replace nodes closer to the root, which also means reclassifying leaves of subtrees closer to the root which may have been replaced during this process.

Fig.3: Decision Tree Raising Algorithm.
Note that Figure 3 line 4 states "if Replacing n with c does not lower accuracy of D..." A tree-raising algorithm could just as easily be configured to consider some delta reduction in accuracy to be acceptable, with the idea being that a less accurate but more easily understandable model could be beneficial in a given situation.
After a model built via induction has been solidified with pruning, classification is then a trivial matter. An unseen instance is run down the tree, starting at its root, with instance-specific attribute-related decisions made as appropriate, until a leaf node is reached. The instance is then classified as per the class associated with the leaf node.
One of the most important takeaways from this discussion should be that decision tree is a classification strategy as opposed to some single, well-defined classification algorithm. This post outlines 3 separate decision tree algorithm implementations, and notes there may be several ways to configure different aspects of each. Indeed, any algorithm which seeks to classify data, and takes a top-down, recursive, divide-and-conquer approach to crafting a tree-based graph for subsequent instance classification, regardless of any other particulars (including attribution split selection methods and optional tree-pruning approach) would be considered a decision tree.
Check out the results of a recent KDnuggets poll outlining other algorithms which are available and in use today.
Related: