Frequent Pattern Mining and the Apriori Algorithm: A Concise Technical Overview
This post provides a technical overview of frequent pattern mining algorithms (also known by a variety of other names), along with its most famous implementation, the Apriori algorithm.
Frequent pattern mining. Association mining. Correlation mining. Association rule learning. The Apriori algorithm.
These are all related, yet distinct, concepts that have been used for a very long time to describe an aspect of data mining that many would argue is the very essence of the term data mining: taking a set of data and applying statistical methods to find interesting and previously-unknown patterns within said set of data. We aren't looking to classify instances or perform instance clustering; we simply want to learn patterns of subsets which emerge within a dataset and across instances, which ones emerge frequently, which items are associated, and which items correlate with others. It's easy to see why the above terms become conflated.
So, let's have a look at this essential aspect of data mining. Foregoing the Apriori algorithm for now, I will simply use the term frequent pattern mining to refer to the big tent of concepts outlined above, even if somewhat flawed (and even if I personally prefer the less often used term association mining).
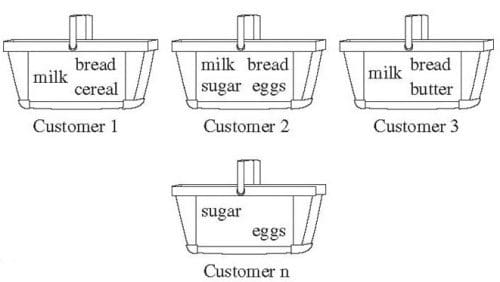
Fig.1: Market Basket Analysis (Han, Kamber & Pei).
Market Basket Analysis
Frequent patterns are patterns which appear frequently within a dataset (surprised?). A frequent itemset is one which is made up of one of these patterns, which is why frequent pattern mining is often alternately referred to as frequent itemset mining.
Frequent pattern mining is most easily explained by introducing market basket analysis (or affinity analysis), a typical usage for which it is well-known. Market basket analysis attempts to identify associations, or patterns, between the various items that have been chosen by a particular shopper and placed in their market basket, be it real or virtual, and assigns support and confidence measures for comparison. The value of this lies in cross-marketing and customer behavior analysis.
The generalization of market basket analysis is frequent pattern mining, and is actually quite similar to classification except that any attribute, or combination of attributes (and not just the class), can be predicted in association. As association does not require the pre-labeling of classes, it is a form of unsupervised learning.
Confidence, Support, and Association Rules
If we think of the total set of items available in our set (sold at a physical store, at an online retailer, or something else altogether, such as transactions for fraud detection analysis), then each item can be represented by a Boolean variable, representing whether or not the item is present within a given "basket." Each basket is then simply a Boolean vector, possibly quite lengthy dependent on the number of available items. A dataset would then be the resulting matrix of all possible basket vectors.
This collection of Boolean basket vectors are then analyzed for associations, patterns, correlations, or whatever it is you would like to call these relationships. One of the most common ways to represent these patterns is via association rules, a single example of which is given below:
milk => bread [support = 25%, confidence = 60%]
How do we know how interesting or insightful a given rule may be? That's where support and confidence come in.
Support is a measure of absolute frequency. In the above example, the support of 25% indicates that, in our finite dataset, milk and bread are purchased together in 25% of all transactions.
Confidence is a measure of correlative frequency. In the above example, the confidence of 60% indicates that 60% of those who purchased milk also purchased bread.
In a given application, association rules are generally generated within the bounds of some predefined minimum threshold for both confidence and support, and rules are only considered interesting and insightful if they meet these minimum thresholds.
Apriori
Apriori enjoys success as the most well-known example of a frequent pattern mining algorithm. Given the above treatment of market basket analysis and item representation, Apriori datasets tend to be large, sparse matrices, with items (attributes) along the horizontal axis, and transactions (instances) along the vertical axis.
From an initial dataset of n attributes, Apriori computes a list of candidate itemsets, generally ranging from size 2 to n-1, or some other specified bounds. The number of possible itemsets of size n-(n+1) to n-1 that can be constructed from a dataset of size n can be determined as follows, using combinations:

The above can also be expressed using the binomial coefficient.
Very large itemsets held within extremely large and sparse matrices can prove very computationally expensive.

Fig.2: Apriori Candidate Itemset Generation Algorithm
A support value is provided to the algorithm. First, the algorithm generates a list of candidate itemsets, which includes all of the itemsets appearing within the dataset. Of the candidate itemsets generated, an itemset can be determined to be frequent if the number of transactions that it appears in is greater than the support value.

Fig.3: Apriori Frequency Itemset Selection Algorithm
Explicit association rules can then trivially be generated by traversing the frequent itemsets, and computing associated confidence levels. Confidence is the proportion of the transactions containing item A which also contains item B, and is calculated as

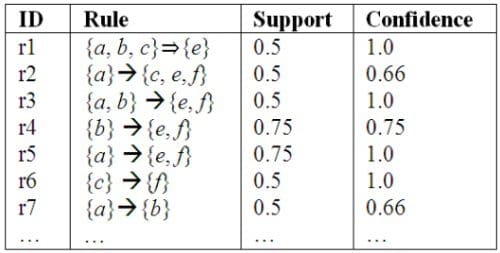
Fig.4: Sample Association Rules with Support and Confidence
(Source: An introduction to frequent pattern mining, by Philippe Fournier-Viger.
The manner in which Apriori works is quite simple; it computes all of the rules that meet minimum support and confidence values. The number of possible potential rules increases exponentially with the number of items in the itemset. Since the computation of new rules does not rely on previously computed rules, the Apriori algorithm provides an opportunity for parallelism to offset computation time.
Check out the results of a recent KDnuggets poll outlining other algorithms which are available and in use today.
Related: