Why the Data Scientist and Data Engineer Need to Understand Virtualization in the Cloud
This article covers the value of understanding the virtualization constructs for the data scientist and data engineer as they deploy their analysis onto all kinds of cloud platforms. Virtualization is a key enabling layer of software for these data workers to be aware of and to achieve optimal results from.
Justin Murray, Technical Marketing Architect at VMware.
More and more application workloads are moving to the different cloud platforms. This could be a move to a public, private or hybrid cloud (where the latter is a mixture of public and private). Big data and analytics application workloads are on the move too. It is important that the data science/engineering community has a good understanding of these clouds at a deeper level so as to make the best use of them for doing their analytics work more effectively.
Virtualization is at the core of all modern cloud environments – it is the cloud infrastructure shown below. The unit that provides the flexibility, elasticity, ease of management and scaling in any cloud is the virtual machine – essentially through the hardware independence and portability that virtual machines offer.
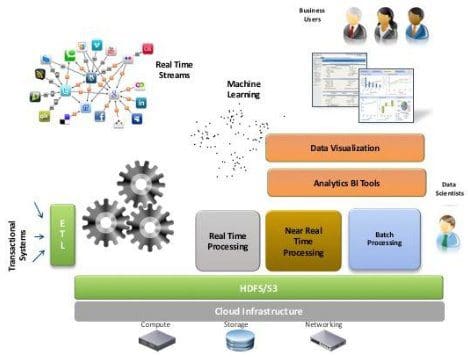
Although non-virtualized servers may be supported in some clouds, it is very rare in our experience that a cloud deployment would use this native hardware approach – and it can become inefficient. No cloud service provider wants to be duty bound to acquire and provision new hardware servers when you want to expand your analytics processing cluster or other distributed application– that kind of setup can take some time! Virtualization is the answer here, through rapid provisioning of virtual machines for this purpose – given the hardware capacity to do so, of course. Multi-tenancy on the cloud is also achieved through virtualization. Two tenant workloads may live on common servers, but are separated from each other through their encapsulation in virtual machines.
Data scientists and data engineers have been accustomed to running their data processing and analysis work on a bare metal or physical environment up to now. But with the recent rapid growth in cloud infrastructure, these folks need to understand the new virtualized infrastructure within their clouds, as it is now underlying and controlling their workloads. We will go through the main points of interest for the data scientist in this virtualization area and the benefits from using it here.
An Industry Trend
Many data science/engineering workloads are based on Hadoop and Spark platforms today, with Python, Scala, R, Java or others as the programming environment that operate on them. We see a big growth in interest in deploying these platforms to all types of clouds over recent months. As one example, the Databricks company, a leader in the development of Spark, deploys the platform to the public cloud, first. The Spark technology is absolutely suitable for the private cloud too, as we will see in a later section.
Leading Hadoop distributors such as Cloudera, Hortonworks and MapR have developed tools for deploying their distributions to public and private clouds. The pure play analytics/machine learning vendors, like H2O and Turi also deploy their software as a service on the cloud. We see many smaller software companies deploying their big data products or infrastructure from day one to some form of cloud, no longer just to bare metal.
There was an early misconception that virtualization in this way would slow the big data analytics workload down. However, extensive testing has shown that quite the opposite is true. Performance is as good as bare metal for virtualized private cloud-based big data workloads that use the underlying virtualization layer in the right way. We will show some testing results here to prove that point. The result of all of this is that the pace of companies’ moving to cloud is now picking up.
Sharing the Cloud Infrastructure Language
Business managers ask their data science teams to find the answers to key business questions. Data scientists depend on their data engineers to integrate, load, cleanse, index and manage the data so it is suitably organized for their queries. These queries or jobs can range from questions about fraud detection, customer pattern analysis, product feature use, sentiment analysis, product quality or many other business areas.
Data science teams are made up of people with a variety of skills, with analytics and statistical processing in general being very prevalent among them, along with data cleansing, data integration and SQL/programming ability as essential skills for data engineers. Data scientists/engineers are often not involved in choosing or managing the infrastructure supporting their applications, though naturally they want to get the highest level of flexibility and the best performance from their applications.
It is very advantageous to the organization if the data science/data engineering people can speak the language of the cloud infrastructure decision makers, so they can have a conversation about the best deployment choices. This can be as fundamental as how many virtual CPUs or how much memory a set of virtual machines should have, for optimal behavior of particular workloads –or about the architecture of the system as a whole.
Iteration on a Data Problem
Data scientists often iterate several times on the solution to a data analytics question. They refine queries that give different answers to a question over time before they are happy with the results. They expand or contract the quantity of data used for queries and along with that, the processing framework that holds the data – such as a Spark cluster as one example. This is a dynamic environment, where the amount of compute power and storage needed to support the analysis is unpredictable. Demand on the infrastructure can fluctuate widely over the course of a single project’s lifetime. This variability means that the application infrastructure must be open to expansion and contraction at will, according to user needs.
System Services
The types of software services that data scientists need will vary too – requiring a lot of freedom of configuration by the end user community. One group may be using dashboards, another workbooks/notebooks, others SQL engines for querying data while others still will write programs in Python and Scala to process the data. The toolkit for the data scientist/data engineer is growing continually with new features appearing regularly.
To do their work properly, data scientists need a scalable compute infrastructure and high-performance data storage mechanism to support them. Their demands on the infrastructure will vary, but when they need it, performance is at a premium.
The data science teams also need their supporting infrastructure to be available on-demand – their time should not be wasted in waiting for that infrastructure to be provisioned. The scientist may use the infrastructure heavily for a period of time and then move off the initial project to some other activity.
Trading off the compute requirements of separate data science teams with different measures can be a significant task for the manager or the Chief Data Officer (CDO), who is in over all of these teams.
This is the key area in which virtualization and cloud can help these communities. When managers such as the CDO are concerned with keeping their data analytics teams operating at maximum efficiency, they don’t want the infrastructure getting in the way. By carving up their total set of computing resources into pools that can be allocated to teams flexibly, they can avoid the single-use purpose to which many physical clusters were initially put and use cycles from elsewhere that happen to be available.
Multiple Changing Factors in the Big Data World
In big data, one infrastructure does not fit all processing needs. At the Hadoop level, for example, older distributed platforms may be suitable for some batch-type workloads whereas Spark should be used for other more interactive requirements or for iterating over a dataset. This means that there will almost certainly be more than one distribution of the platform (e.g. the Spark version) or combinations of other products in use at any one time. We have found many versions and two or more distributions of this software in use at once at many of the enterprises that we interact with, for example. Virtualization provides the key to running all of these variants at once, with separation between them.
Other variables are also at play:
- The types of questions being asked by the Chief Data Officer vary over time requiring differing application types to support them
- The infrastructure, (such as open source Hadoop and Spark distributions) are changing at a rapid pace
- Multiple versions of the software infrastructure are likely to be needed at the same time by different teams
- Separation of performance concerns across these teams is essential
- Data may be shared across multiple teams while the processing they do on that data may differ
- Certain instances of the infrastructure may be tuned for interactive response while others are designed for batch processing
These variables all lead to a need for the type of flexibility that only virtualized platforms provide. It does so by separating each group/version/distribution/application from others, giving them their own sandbox or collection of virtual machines to work in and isolating the performance of one collection from another.