Must-Know: When can parallelism make your algorithms run faster? When could it make your algorithms run slower?
Efficient implementation is key to achieving the benefits of parallelization, even though parallelism is a good idea when the task can be divided into sub-tasks that can be executed independent of each other without communication or shared resources.
Editor's note: This post was originally included as an answer to a question posed in our 17 More Must-Know Data Science Interview Questions and Answers series earlier this year. The answer was thorough enough that it was deemed to deserve its own dedicated post.
Parallelism is a good idea when the task can be divided into sub-tasks that can be executed independent of each other without communication or shared resources. Even then, efficient implementation is key to achieving the benefits of parallelization. In real-life, most of the programs have some sections that need to be executed in serialized fashion, and the parallelizable sub-tasks need some kind of synchronization or data transfer. Thus, it is hard to predict whether parallelization will actually make the algorithm run faster (than the serialized approach).
Parallelism would always have overhead compared to the compute cycles required to complete the task sequentially. At the minimum, this overhead will comprise of dividing the task into sub-tasks and compiling together the results of sub-tasks.
The performance of parallelism against sequential computing is largely determined by how the time consumed by this overhead compares to the time saved due to parallelization.
Note: The overhead associated with parallelism is not just limited to the run-time of code, but also includes the extra time required for coding and debugging (parallelism versus sequential code).
A widely-known theoretical approach to assessing the benefit of parallelization is Amdahl’s law, which gives the following formula to measure the speedup of running sub-tasks in parallel (over different processors) versus running them sequentially (on a single processor):
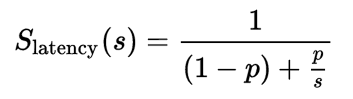
where:
- Slatency is the theoretical speedup of the execution of the whole task;
- s is the speedup of the part of the task that benefits from improved system resources;
- p is the proportion of execution time that the part benefiting from improved resources originally occupied.
To understand the implication of Amdahl’s Law, look at the following figure that illustrates the theoretical speedup against an increasing number of processor cores, for tasks with different level of achievable parallelization:

It is important to note that not every program can be effectively parallelized. Rather, very few programs will scale with perfect speedups because of the limitations due to sequential portions, inter-communication costs, etc. Usually, large data sets form a compelling case for parallelization. However, it should not be assumed that parallelization would lead to performance benefits. Rather, the performance of parallelism and sequential should be compared on a sub-set of the problem, before investing effort into parallelization.
Related: