The Data Science of Steel, or Data Factory to Help Steel Factory
Applying Machine Learning to steel production is really hard! Here are some lessons from Yandex researchers on how to balance the need for findings to be accurate, useful, and understandable at the same time.
By Victor Lobachev, Research Director at Yandex Data Factory.
Steel production is an area that has been studied for decades, and as such the industry has remained very conservative. Despite the big data revolution beginning in the early 2000s, “old-school” industries like steel-making have largely shunned any form of data-driven applications.
Fortunately, things change, and here’s an example of how data analytics technologies, born within the internet industry, can be applied to an offline practice like turning pig iron into steel.
The challenge:
When we began work with Magnitogorsk Iron and Steel Works (MMK), one of the world’s largest steel producers and a leading steel company in Russia, a lot of time was spent looking for a challenge that if solved, could (a) positively impact business revenues, and (b) be completed in reasonable time.The challenge that was eventually uncovered and able to meet these criteria, is one well-known to all metallurgists: how much of each ferroalloy to add during steel-making process in order to ensure the required chemistry of the steel at the lowest possible cost.
This chemistry is dictated by the international standards for steel – a list of required ranges for the amounts of each element in the final mix. However, uncertainties in the steel-making process make determining the optimal amount of ferroalloys a complicated task. As ferroalloys participate in numerous chemical reactions, the final absorption of the added elements depends on many factors, which measurements are rough or even unknown.On top of that, ferroalloys are rather expensive –they can cost steelmakers hundreds of millions of dollars per year. As a result, metallurgy companies must balance two competing demands: keeping the use of costly ferroalloys to a minimum during production, and making sure that the resulting chemical composition complies with all requirements.
To help steelmakers with this challenge, we developed a recommendation service based on machine learning technologies and a history of 200,000 smeltings over the past years – luckily stored by MMK.
The solution:
In a nutshell, the solution we developed consists of two parts: (1) the ferroalloy absorption model and (2) the optimization. However, before we discovered success there were a number of failed attempts – each of which provided interesting insights for us to learn from. The first part of the solution is the “absorption model”. Such model takes all available parameters of smeltings – the mass of scrap and crude iron, records of material consumption and chemical measurements, – as well as the amounts of the added ferroalloys, and returns the expected chemical composition of steel.

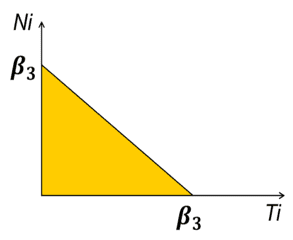
Fig. 1: These two-dimensional examples illustrate the restrictions applied to the percentages of certain chemical elements. The areas in yellow reflect the domains where the requirements are satisfied.
Chemical composition is a vector of percent shares of all chemical elements. Our first attempt was to build a model that would predict the whole vector at once, using a deep learning approach. Despite the recent hype around deep learning, it does not provide the best solution to every problem. In this instance, for example, the neural net proved to be not as good as expected. It is still not quite clear why the neural net failed; one of the reasons could be the various nature of input factors we used. This is far from the traditional deep learning tasks which use homogeneous factors such as computer vision, speech recognition or natural language processing.
We then switched to the element-by-element model. With this relatively straightforward idea, we fed all parameters of available smeltings into a regression tool and built the element models quickly. Unfortunately, this model did not work well either; probably it overlooked some significant dependencies in the data. With this in mind, we started scrupulous feature engineering. Since this required a lot of industry-specific expertise, finding the good set of factors was no easy task.
We spent a lot of time collaborating with MMK professionals and acquiring knowledge from scratch. After a crash course to the basics of steel-making, we finally succeeded in fine-tuning the factors based on the collected experience, and built the smelting model.
The model was built using MatrixNet – a powerful machine-learning tool developed by our parent company, Yandex – and tended to show good results. But, when we optimized on top of that model, we got recommendations that often looked too unusual to the steel casters. In the effort to make our recommendations sound more familiar, we decided to put as much “physical sense” in them as possible. To do this, we needed to simplify the model and make it more interpretable. For this, we used linear regression instead of the complex model used by MatrixNet. Unfortunately, this ended up being less effective than the MatrixNet model.
With this in mind, we decided to use a two-stage process. Linear regression was used as a first step, and then MatrixNet model was trained on the difference between the target value and the prediction of the simple linear model. It made the model even more precise, while keeping the main trends that the model predicts interpretable and familiar to the steel casters.
 Still, the regression model was quite noisy due to the uncertainty of some factors. We had to turn this problem into a solution: instead of sticking to the usual regression model we started using the probabilistic model in which the result was a probability distribution.
Still, the regression model was quite noisy due to the uncertainty of some factors. We had to turn this problem into a solution: instead of sticking to the usual regression model we started using the probabilistic model in which the result was a probability distribution.
As soon as the absorption model was available, we switched to the second part of the solution – optimization. We needed to optimize model parameters including the amounts of ferroalloys added to produce a specific steel grade at the lowest possible cost. Here the tricky part was building a goal function out of the probabilistic model. It required a balance between minimizing costs and maximizing the confidence of meeting chemical composition requirements – for all chemical elements at once.
The trick was successfully done, and we delivered the second part of the solution – to be finally put into practice.
Results:
To see the model at work and test its economic effect, MMK together with Yandex Data Factory conducted a series of experimental smeltings. Preliminary tests at the mill’s oxygen converter plant indicated that the service could help to achieve an average decrease of 5% in ferroalloy use, equating to substantial annual savings of more than $4 million, while maintaining the high quality of steel produced.What’s more, a machine learning model can further learn on new data, increasing the service recommendations accuracy, and thus resulting in more savings.
Optimization of ferroalloy use is only one of the examples of applying machine learning technologies in manufacturing, alongside with quality prediction, computer-vision based monitoring, optimization of production parameters, and so on. Yandex Data Factory experience with MMK proves once again how much data science can do for industrial companies, delivering extra efficiencies across the whole shop floor.
Bio: Victor Lobachev is Research Director at Yandex Data Factory and have over 15 years of analytical and programming experience including business domain analysis, data processing, numerical simulation and object-oriented software development.
Related: