Data Science Basics: What Types of Patterns Can Be Mined From Data?
Why do we mine data? This post is an overview of the types of patterns that can be gleaned from data mining, and some real world examples of said patterns.
Recall that data science can be thought of as a collection of data-related tasks which are firmly rooted in scientific principles. While no consensus exists on the exact definition or scope of data science, I humbly offer my own attempt at an explanation:
Data science is a multifaceted discipline, which encompasses machine learning and other analytic processes, statistics and related branches of mathematics, increasingly borrows from high performance scientific computing, all in order to ultimately extract insight from data and use this new-found information to tell stories.
As far as data science's relationship with data mining, I'm on the record stating that "Data science is both synonymous with data mining, as well as a superset of concepts which includes data mining." Since this post will focus on the different types of patterns which can be mined from data, let's turn our attention to data mining.
Data mining functionality can be broken down into 4 main "problems," namely: classification and regression (together: predictive analysis); cluster analysis; frequent pattern mining; and outlier analysis. There are all sorts of other ways you could break down data mining functionality as well, I suppose, e.g. focusing on algorithms, starting with supervised versus unsupervised learning, etc. However, this is a reasonable and accepted approach to identifying what data mining is able to accomplish, and as such these problems are each covered below, with a focus on what can be solved with each "problem."
Classification
Classification is one of the main methods of supervised learning, and the manner in which prediction is carried out as relates to data with class labels. Classification involves finding a model which describes data classes, which can then be used to classify instances of unknown data. The concept of training data versus testing data is of integral importance to classification.
Popular classification algorithms for model building, and manners of presenting classifier models, include (but are not limited to):
- Decision Trees
- Support Vector Machines
- Neural Networks
- Nearest Neighbors
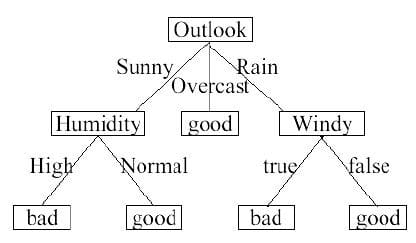
Examples of classification abound. A sample of such opportunities include:
- Identifying credit risks at multiple levels (low, medium, high)
- Loan approvals (binary classification: loan versus no loan)
- Classifying news stories based on multiple topics (politics, sports, business, entertainment, ..., etc.)
To classify news stories, for example, labeled stories can be used to build a model, while stories of unknown classes are then used to test the model, with the model predicting what the story's topic is based on its training. Classification is one of the main drivers of data mining, and its potential applications are, quite literally, endless.
Regression
Regression is similar to classification, in that it is another dominant form of supervised learning and is useful for predictive analysis. They differ in that classification is used for predictions of data with distinct finite classes, while regression is used for predicting continuous numeric data. As a form of supervised learning, training/testing data is an important concept in regression as well. Linear regression is a common form of regression "mining."
What is regression useful for? Like classification, the potential is limitless. A few particular examples include:
- Predicting home prices, as houses tend to be priced on the financial continuum, as opposed to being categorical
- Trend estimation, in the fitting of trend lines to time series data
- Multivariate estimation of health related indicators, such as life expectancy
As a beginner, don't let non-linear regression fool you: it's simply that the best-fit line isn't linear, and it, instead, takes another shape. This can be referred to as curve-fitting, but it is essentially no different than linear regression and fitting straight lines, though the methods used for estimation will be different.
Cluster Analysis
Clustering is used for analyzing data which does not include pre-labeled classes. Data instances are grouped together using the concept of maximizing intraclass similarity and minimizing the similarity between differing classes. This translates to the clustering algorithm identifying and grouping instances which are very similar, as opposed to ungrouped instances which are much less-similar to one another. As clustering does not require the pre-labeling of classes, it is a form of unsupervised learning.
k-means Clustering is perhaps the most well-known example of a clustering algorithm, but is not the only one. Different clustering schemes exist, including hierarchical clustering, fuzzy clustering, and density clustering, as do different takes on centroid-style clustering (the family to which k-means belongs).
Returning to document examples, clustering analysis would allow for a set of documents of unknown authors to be clustered together based on their content style, and (hopefully), as a result, their authors - or, at least, by similar authors. In marketing, clustering can be of particular use in identifying distinct groups of customer bases, allowing for targeting based on what techniques may be known to have worked with other similar customers in said groups.
Other examples? Think of any situation in which you may have a large dataset of instances which are not explicitly separated categorically, but which may "naturally" exhibit similar sets of characteristics: a collection of data describing types of animals (# of legs, eye position, covering); extensive data about numerous types of proteins; genetic info describing individuals of a wide array of ethnic backgrounds. All of these situations (and many more) could benefit from allowing unsupervised clustering algorithms find which instances are similar to one another, and which instances are dissimilar.
Frequent Pattern Mining
Frequent pattern mining is a concept that has been used for a very long time to describe an aspect of data mining that many would argue is the very essence of the term data mining: taking a set of data and applying statistical methods to find interesting and previously-unknown patterns within said set of data. We aren't looking to classify instances or perform instance clustering; we simply want to learn patterns of subsets which emerge within a dataset and across instances, which ones emerge frequently, which items are associated, and which items correlate with others. It's easy to see why the above terms become conflated.
Frequent pattern mining is most closely identified with market basket analysis, which is the identification of subsets of finite superset of products that are purchased together with some level of both absolute and correlative frequency. This concept can be generalized beyond the purchase of items; however, the underlying principle of item subsets remains unchanged.
Outlier Analysis
Outlier analysis, also called anomaly detection, is a bit different than the other data mining "problems," and is often not considered on its own, for a few specific reasons.
First, and most importantly to this discussion, outlier analysis is not its own method of mining as are the other problems above, but instead can actually use the above methods for its own goals (it's an end, as opposed to a means). Second, outlier analysis can also be approached as an exercise in descriptive statistics, which some would argue is not data mining at all (holding that data mining consists of, by definition, predictive statistical methods). However, in the interests of being exhaustive, it has been included here.
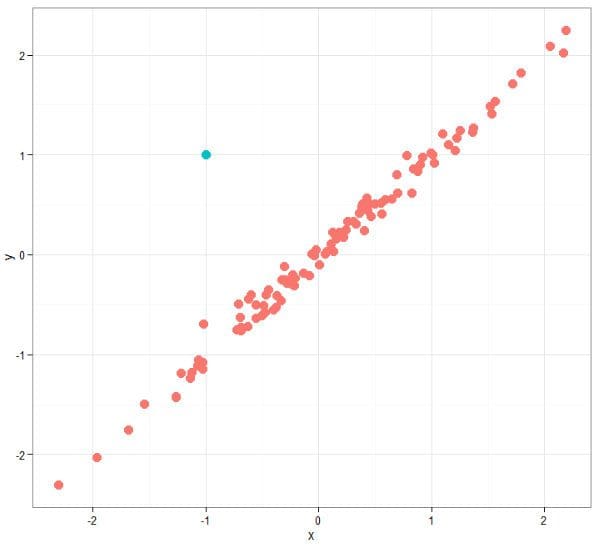
Outliers are data instances which do not seem to readily fit the behavior of the remaining data or a resulting model. Though many data mining algorithms intentionally do not take outliers into account, or can be modified to explicitly discard them, there are times when outliers themselves are where the money is.
And that could not be more literal than in fraud detection, which uses outliers as identification of fraudulent activity. Regularly use your credit card in and around New York and on online, mostly for insignificant purchases? Used it at a coffee shop this AM in Soho, had dinner on the Upper West Side, but spent several thousand dollars "in person" on electronics equipment in Paris sometime in between? There's your outlier, and these are pursued relentlessly using a wide variety of mining and simple descriptive techniques.
Related: