Using GRAKN.AI to Detect Patterns in Credit Fraud Data
The term Horn Clause Mining, similar to Rule Based Machine Learning or Inductive Logic Programming, is used to describe the inverse of this functionality. Given a large enough knowledge base, can we infer rules that describe the data accurately?
By Oscar Darwin, Grakn Labs.

“Robbery” by stavos is licensed under CC 2.0
The worlds of first order logic and machine learning don’t usually collide. But with increasing sizes of datasets around the web and, more importantly, complex relationships that need to be represented, analysts need ways of applying machine learning techniques to discover patterns in their datasets.
Sitting right in the middle of this space is GRAKN.AI, a powerful database technology that allows complex relationships to be represented and further provides an elegant query language, Graql, that allows retrieval of questions involving these relationships. This blog will assume some familiarity with the GRAKN.AI ecosystem including the terms Ontology, Entities, Relations and Roles.
In case you’re not entirely familiar with the terms mentioned above, or if you just want some some additional background reading, check out our “What is an Ontology?” post, along with this Intro to GRAKN.AI. As always, for the most up to date info, check our documentation.
This summer, as one of the two new interns, it is my job to investigate the possibilities of GRAKN.AI; with both the datasets and also it’s integrations with other machine learning toolkits. In fact, it was on my first day that a chat with our founder, Haikal, on a train back from Cambridge led to the research topic of this blog post.
Horn Clause Mining
Don’t be put off by the title of this section! The idea is actually quite simple. Remember Graql rules? These are statements that are written like:
$uncle-rule isa inference-rule,
lhs {
(family-member : $X, family-member : $Y) isa parent-of;
(family-member : $Y, family-member : $Z) isa brother-of;
},
rhs {
(family-member : $X, family-member : $Z) isa uncle-of;
};
With this rule, we are telling the the GRAKN.AI engine that whenever X has parent Y and Y has brother Z, then Z is the uncle of X. In this example, X, Y and Z are entities and parent-of, brother-of and uncle-of are relations in our ontology. This type of rule is called a horn clause and could be written using logic syntax as:
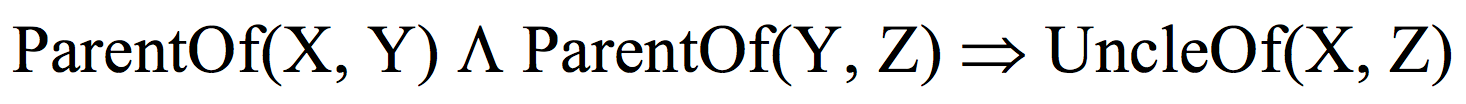
GRAKN.AI uses reasoning to infer relations based on these rules: every time the pattern on the left hand side appears in the knowledge base, GRAKN.AI will symbolically include the right hand side relation as well. That is, it won’t exist in the underlying data, but any queries performed against the database will assume the relation is there.
The term Horn Clause Mining, similar to Rule Based Machine Learning or Inductive Logic Programming, is used to describe the inverse of this functionality. Given a large enough knowledge base, can we infer rules that describe the data accurately? Three projects have emerged in the last decade to answer this question.
All of these systems find rules describing a knowledge base by searching the space of rules in some way and then ranking the results according to their own scoring system. Each project was able to scale to larger and larger datasets. In particular, ScaLeKB able to perform its rule mining algorithm on Freebase, one of the largest knowledge-bases in the world, with 112 million entities.
Time to experiment!
How can we combine GRAKN.AI with one of the above implementations of Horn Clause Mining? The first step is to pick a dataset that will have interesting real world applications, and also have enough structure to exploit it’s relation properties. For example, this German credit fraud dataset. I built an ontology and wrote an import script to get the data into GRAKN.AI (scripts can be found here) which is visualised below:
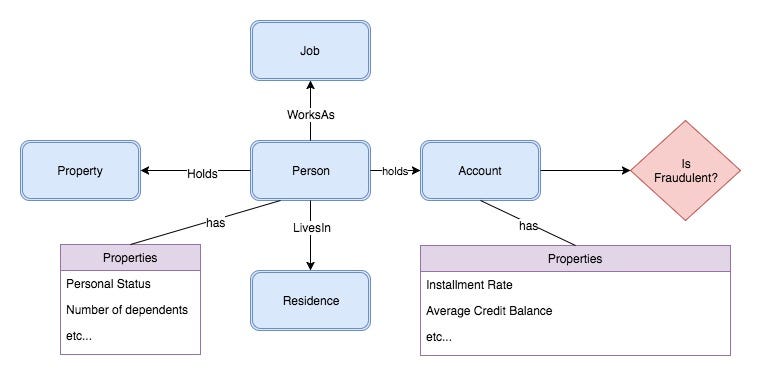
In general, Horn Clause Mining is a kind of pattern recognition that aims to find common relationships that exist between the head of the rule and various possible rule bodies. For example looking at the instances of fraudulent behaviour where a person was living in a particular type of residence and had a particular job. This makes it different from pure graph-based machine learning methods (triangle counting, clustering algorithms) that don’t usually allow multiple different types of relationships to be represented. Similarly, pure machine learning methods usually involve flattening out the data into less complex structures which isn’t ideal either.
Building the Connector
Let us build a simple connector between GRAKN.AI and AMIE+. AMIE+ takes a tab separated file with the structure
<relation> <http://www.w3.org/2000/01/rdf-schema#domain> <role 1>
<relation> <http://www.w3.org/2000/01/rdf-schema#range> <role 2>
...
<entity 1> <relation> <entity 2>
as input. The file starts with a schema section describing the types of the relations and is followed by the instance data consisting of our actual data points. Accessing this information is straightforward, thanks to the GRAKN.AI java API. If you are hosting the GRAKN.AI server on your localhost, to access all the relations in your knowledge base, write:
GraknSession sess= Grakn.session(Grakn.DEFAULT_URI, YOUR_KEYSPACE);
GraknGraph graph = sess.open(GraknTxType.READ);
graph.getRelationType("relation").subTypes()
Note that the subTypes method will return all possible relation concepts, including the relation concept itself! From this, you can cycle through the relations generating schemas for them based on the roles that they relate.
Similarly, to access instance data, call:
graph.getRelationType("relation").instances()
To use AMIE+ we need to trim down the results we want as the software doesn’t know we are specifically interested in rules describing fraudulent behaviour.
- The -maxad <arg> tag reduces the size of possible rules to only include rule bodies of the specified length.
- The -htr <arg> tag selects rules with the specified head relation.
- The -const tag allows rules that don’t just have variables. I.e. isFraudulent(X, false).
- The -bexr <args> tag excludes any relations you list from the body of the rule
Combining these, we have:
java -jar amie_plus.jar -maxad 6 -htr \<has-is_fraudulent\> -const -bexr \<has-is_fraudulent\> output.tsv
We have excluded any fraudulent relations in the body of the rules to reduce the number of rules like
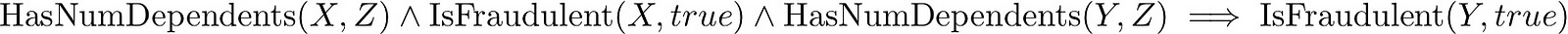
which experimentally was occurring on our particular dataset. These rules aren’t really good as they don’t use features of Y.
So, Running AMIE+ with our fraud data then produces rules such as:

where A and P are account variables and person variables respectively. The body size is the number of occurrences of the body of the rule and the percent accuracy is the proportion of those occurrences such that the head relation existed.
Bear in mind that although the 2nd rule in that list only had a 51% percent accuracy, 30% of the original data was tagged as fraudulent, so this still gives a significant indication of fraud over picking randomly.
For those among you more familiar with machine learning or ILP, the accuracy is calculated on a rule by rule basis, so there is no attempt to combine rules together into a theory and test the accuracy of the theory. In addition, real world machine learning applications would split the data set into a training set, validation set and test set and go through a typical cross validation stage in order to tune our parameters. For our purposes we simply examine the data as a whole though I would be interested to see what kind of accuracy a properly tuned ML system could achieve on unseen data.
To Finish...
At the time of writing I still hadn’t figured out how to get ScaLeKB to work, so perhaps better rules could have been mined using their software. In order to truly complete a machine learning “loop” we would probably need much more data and also perform some validation tests to benchmark this style of machine learning against other more common methods like a Naïve Bayes Classifier or even a decision tree.
This field is nonetheless new and exciting and if you were to pick data that had lots of graphical structure, I suspect whatever graphical patterns existed would be discoverable by this algorithm.
One thing to take away from this exercise was how easy it was to model and retrieve the data in GRAKN.AI. The initial set up of the integration was very straightforward, so in the end 75% of my time was spent understanding and interpreting results from AMIE+ which bodes well for this exciting new technology.
All my code for this project can be found here and keep an eye on this blog for more posts by me over the summer!
Bio: Oscar Darwin is a machine learning intern at GRAKN.AI. Loves maths and music!
Original. Reposted with permission.
Related: