The Machine Learning Abstracts: Decision Trees
Decision trees are a classic machine learning technique. The basic intuition behind a decision tree is to map out all possible decision paths in the form of a tree.
By Narendra Nath Joshi, Carnegie Mellon.

To be or not to be, is the question? But it is, really? Or isn’t it really? OMG, this is addictive, isn’t it? But again, is it?
Decision Tree Learning is a classic algorithm used in machine learning for classification and regression purposes.
Regression is the process of predicting a continuous value as opposed to predicting a discrete class label in classification
The basic intuition behind a decision tree is to map out all possible decision paths in the form of a tree.

A tree showing survival of passengers on the Titanic (“sibsp” is the number of spouses or siblings aboard). The figures under the leaves show the probability of outcome and the percentage of observations in the leaf. Source: Wikipedia
Each path from the root to a leaf of the tree signifies a decision process. Let us try to analyze and deeply understand decision trees using our Spring cleaning example we talked about in the previous part about classification.
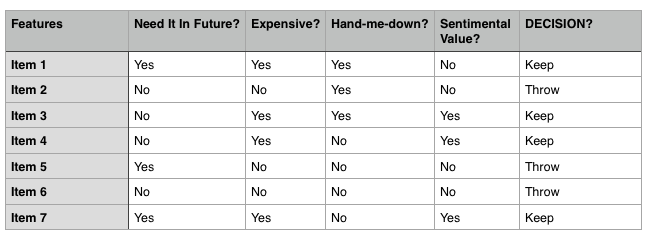
Our training data.
We inferred that the rule the classification algorithm learns is
KEEP = SENTIMENTAL_VALUE | (NEED_FUTURE & EXPENSIVE)
So, a decision tree for the current problem would be something like this:
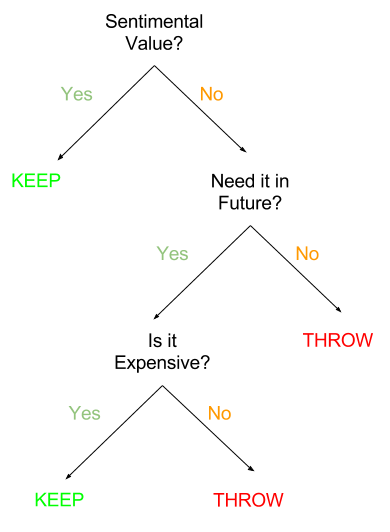
The Decision Tree for our Spring cleaning problem
Explaining, ain’t nobody got time for dat?
Let’s see how we go about the process of constructing a decision tree.
Decision tree construction involves splitting. In our example, each feature has only two possible values (“yes” and “no”). So, each feature can be split into two ways.
We can go about splitting every possible feature into two, but that would give us a very big and highly inefficient tree.
How do we ensure we have a reasonable and a good tree?
Before splitting at each level of the tree, we evaluate all features based on their distribution and decide which feature is the best to split. More formally, which feature gives us the highest information gain on splitting.
Information gain is defined as the expected amount of information that would be needed to specify whether a new input instance should be classified “yes” or “no”, given that the example reached that node from the root.
What do you mean “reached that node”?
All training examples do not reach all parts of the tree. For instance, consider item 3in our Spring cleaning example.
It is eliminated and classified as “KEEP” at the root of our decision tree itself and does not make it to lower levels of the tree.

There are algorithms for constructing decision trees. The one I talked about above is called the ID3 algorithm which is a basic one.
There are some advanced ones too like C4.5 algorithm, CART (Classification and Regression Tree) and CHAID (CHi-squared Automatic Interaction Detector)
Thanks y’all, next time I shall preach a little about Unsupervised Learning and stuff.
Bio: Narendra Nath Joshi is a graduate student in AI and Machine Learning at Carnegie Mellon University, currently pursuing a research intern at Disney Research Pittsburgh. Has a keen interest in natural language, computer vision, and deep learning.
Original. Reposted with permission.
Related: