TensorFlow: What Parameters to Optimize?
Learning TensorFlow Core API, which is the lowest level API in TensorFlow, is a very good step for starting learning TensorFlow because it let you understand the kernel of the library. Here is a very simple example of TensorFlow Core API in which we create and train a linear regression model.

This article targets whom have a basic understanding for TensorFlow Core API.
Learning TensorFlow Core API, which is the lowest level API in TensorFlow, is a very good step for starting learning TensorFlow because it let you understand the kernel of the library. Here is a very simple example of TensorFlow Core API in which we create and train a linear regression model.
The steps are as follows:
- Read the trainable parameters of the model (Just a weight and a bias in this example).
- Read the training data into placeholders.
- Create the linear regression model function.
- Create a loss function to assess the prediction errors of the model.
- Create a TensorFlow session.
- Initialize the trainable parameters.
- Run the session to train the regression model.
1. import tensorflow
2.
3. #Trainable Parameters
4. W = tensorflow.Variable([.6], dtype=tensorflow.float32)
5. b = tensorflow.Variable([.2], dtype=tensorflow.float32)
6.
7. #Training Data (inputs/outputs)
8. x = tensorflow.placeholder(dtype=tensorflow.float32)
9. y = tensorflow.placeholder(dtype=tensorflow.float32)
10.
11. #Linear Model
12. linear_model = W * x + b
13.
14. #Linear Regression Loss Function - sum of the squares
15. squared_deltas = tensorflow.square(linear_model - y)
16. loss = tensorflow.reduce_sum(squared_deltas)
17.
18. #Creating a session
19. sess = tensorflow.Session()
20.
21. #Initializing variables
22. init = tensorflow.global_variables_initializer()
23. sess.run(init)
24.
25. #Print the loss
26. print(sess.run(loss, feed_dict={ x: [1, 2, 3, 4], y: [0, 1, 2, 3]}))
27.
28. sess.close()
The loss returned is 53.76. Existence of error, specially for large error, means that the parameters used must be updated. These parameters are expected to be updated automatically but we can start updating it manually until reaching zero error.
- For W=0.8 and b=0.4, the loss is 3.44
- For W=1.0 and b=0.8, the loss is 12.96
- For W=1.0 and b=-0.5, the loss is 1.0
- For W=1.0 and b=-1.0, the loss is 0.0
Thus when W=1.0 and b=-1.0 the desired results is identical to the predicted results and thus we can`t enhance the model more than this. We reached the optimal values for the parameters but not using the optimal way. The optimal way of calculating the parameters is automatic.
There are a number of optimizers already exist in TensorFlow for making things simpler. These optimizers exist in APIs in TensorFlow such as:
- tensorflow.train
- tensorflow.estimator
Here is how we can use tensorflow.train for updating the parameters automatically.
tensorflow.train API
There are a number of optimizers that TensorFlow provides that makes the previous manual work of calculating the best values for the model parameters automatically.
The simplest optimizer is the gradient descent that changes the values of each parameter slowly until reaching the value that minimizes the loss. Gradient descent modifies each variable according to the magnitude of the derivative of loss with respect to the variable.
Because doing such operations of calculating the derivatives is complex and error prone, TensorFlow can calculate the gradients automatically. After calculating the gradients, you need to optimize the parameters yourself.
But TensorFlow makes things easier and easier by providing optimizers that will calculate the derivatives in addition to optimizing the parameters.
tensorflow.train API contains a class called GradientDescentOptimizer that can both calculate the derivatives and optimizing the parameters. For example, the following code shows how to minimize the loss using the GradientDescentOptimizer:
1. import tensorflow
2.
3. #Trainable Parameters
4. W = tensorflow.Variable([0.3], dtype=tensorflow.float32)
5. b = tensorflow.Variable([-0.2], dtype=tensorflow.float32)
6.
7. #Training Data (inputs/outputs)
8. x = tensorflow.placeholder(dtype=tensorflow.float32)
9. y = tensorflow.placeholder(dtype=tensorflow.float32)
10.
11. x_train = [1, 2, 3, 4]
12. y_train = [0, 1, 2, 3]
13.
14. #Linear Model
15. linear_model = W * x + b
16.
17. #Linear Regression Loss Function - sum of the squares
18. squared_deltas = tensorflow.square(linear_model - y_train)
19. loss = tensorflow.reduce_sum(squared_deltas)
20.
21. #Gradient descent optimizer
22. optimizer = tensorflow.train.GradientDescentOptimizer(learning_rate=0.01)
23. train = optimizer.minimize(loss=loss)
24.
25. #Creating a session
26. sess = tensorflow.Session()
27.
28. writer = tensorflow.summary.FileWriter("/tmp/log/", sess.graph)
29.
30. #Initializing variables
31. init = tensorflow.global_variables_initializer()
32. sess.run(init)
33.
34. #Optimizing the parameters
35. for i in range(1000):
36. sess.run(train, feed_dict={x: x_train, y: y_train})
37.
38. #Print the parameters and loss
39. curr_W, curr_b, curr_loss = sess.run([W, b, loss], {x: x_train, y: y_train})
40. print("W : ", curr_W, ", b : ", curr_b, ", loss : ", curr_loss)
41.
42. writer.close()
43.
44. sess.close()
Here is the result returned by the optimizer. It seems that it deduced the right values of the parameters automatically in order to get the least loss.
W : [ 0.99999809] , b : [-0.9999944] , loss : 2.05063e-11
There is some advantages of using such built-in optimizers rather than building it manually. This is because the code for creating such simple linear regression model using TensorFlow Core API is not complex. But it won`t be like that when working with much more complex models. Thus it is preferred to use the frequently used tasks from high-level APIs in TensorFlow.
Here is the dataflow graph of the previous program when visualized using TensorBoard (TB).
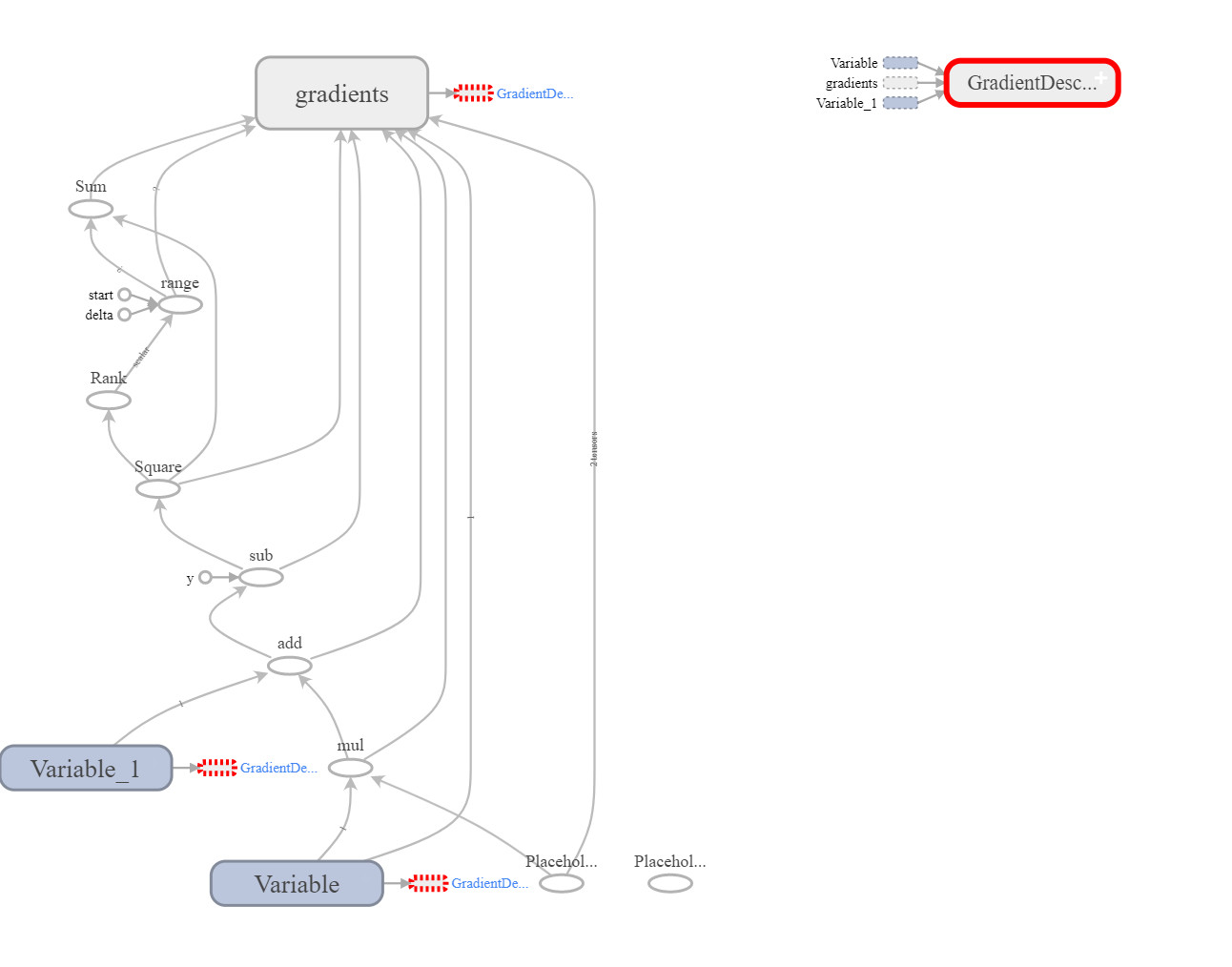
But there is a very important question. How the optimizer deduced the parameters that it should change? How it deduced that we are to optimize the weight (W) and bias (b)? We have not explicitly told the optimizer that these are the parameters that it will change in order to reduce the loss but it deduced it itself. So, how?
In line 35, we run the session and asked to evaluate the train Tensor. TensorFlow will follow the chain of graph nodes to evaluate that Tensor. In line 23, TensorFlow found that to evaluate the train Tensor it should evaluate the optimizer.minimize operation. This operation will try to minimize its input arguments as much as possible.
Following back, to evaluate the minimize operation it will accept one Tensor which is the loss. So, the goal now is to minimize the loss Tensor. But how to minimize the loss? It will still follow the graph back and it will find it is evaluated using the tensorflow.reduce_sum() operation. So, our goal now is to minimize the result of the tensorflow.reduce_sum() operation.
Following back, this operation is evaluated using one Tensor as input which is squared_deltas. So, rather than having our goal to minimize the tensorflow.reduce_sum() operation, our goal now is to minimize the squared_deltas Tensor.
Following the chain back, we find that the squared_deltas Tensor depends on the tensorflow.square() operation. So, we should minimize tensorflow.square() the operation. Minimizing that operation will ask us to minimize its input Tensors which are linear_model and y_train. Looking for thse two tensors, which one can be modified? The Tensors of type Variables can be modified. Because y_train is not a Variable but placeholder, then we can`t modify it and thus we can modify the linear_model to minimize the result.
In line 15, the linear_model Tensor is calculated based on three inputs which are W, x, and b. Looking for these Tensors, only W and x can be changed because they are variables. So, our goal is to minimize these two Tensors W and x.
This is how TensorFlow deduced that to minimize the loss it should minimize the weight and bias parameters.
Bio: Ahmed Gad received his B.Sc. degree with excellent with honors in information technology from the Faculty of Computers and Information (FCI), Menoufia University, Egypt, in July 2015. For being ranked first in his faculty, he was recommended to work as a teaching assistant in one of the Egyptian institutes in 2015 and then in 2016 to work as a teaching assistant and a researcher in his faculty. His current research interests include deep learning, machine learning, artificial intelligence, digital signal processing, and computer vision.
Original. Reposted with permission.
Related: