8 Common Pitfalls That Can Ruin Your Prediction
A good prediction can help your work and make it easier. But how can you be sure that your prediction is good? Here are some common pitfalls that you should avoid.
By Norbert Obsuszt, AnswerMiner.
On an ordinary day, you make hundreds of predictions based on previous observations, usually with the help of your personal neural network located at the top of your neck. If you want better predictions, you need more information, so you have to utilize others’ observations, not just yours.
Data-based predictions can increase your company’s profit or make your life better.
But be careful! Some common mistakes can cause your predictions to be useless or even misleading.
Common Predictions You Are Always Calculating
- If you will need an umbrella (based on weather forecasts and the temperature sensors in your skin)
- When you should start to go to work (based on the day of week, the current month, and traffic reports)
- Which bit of work will reap the most benefits in the future (based on writing a blog post, sending an email, or meeting up with a loyal customer)
- What your colleague is thinking when he tells you something (based on his gestures, facial expression, and intonation)
- How your child will react to the birthday gift you are thinking about buying him (based on his age, his interest, the gift price, and the product category)
Examples of Data-Based Predictions That Create Profit
- How many loaves of bread will be sold in your bakery? If you bake too few or too many, you will lose money.
- Of those who signed up, how many people will come to your meetup? You must order enough but not too much food because it costs money.
- When should you change currency from USD to EUR or vice versa? Currency rates are hard to predict, but you can save 1%-2%.
- Which applicant is more likely to perform well in the job position for which you are hiring? Hiring the best salesman will bring you more customers and thus, more money.
- How many customers will you potentially lose over the next month? If you predict the churn rate of paying customers, you can prevent it.
The more data you have, the better your predictions will be.
Keep this Critical Advice in Mind
- Method Selection
There are several prediction algorithms and sub-variant, and all have their advantages and disadvantages. You must choose the one that best fits your needs.
- Linear Regression: easy to understand but cannot capture complex relationships
- Decision Tree: easy to understand and visualize but need to select parameters carefully
- Random Forest: very high-quality prediction models but hard to visualize and can be slow
- Neural Networks: best prediction power for very complex tasks but extraordinarily compute-intensive and impossible to understand its behavior
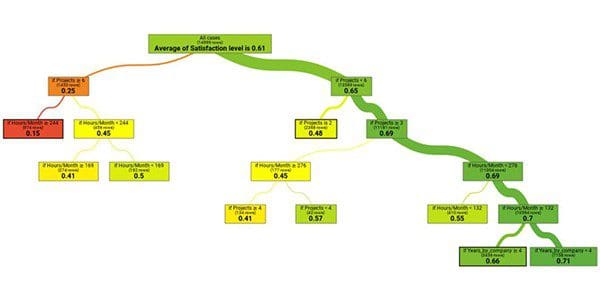
Decision tree
- Overfitting
Overfitting is when your draw general conclusions based on very specific, rarely occurring events that happened only by coincidence.
- Good Prediction: If the sky is cloudy and humidity is high, it will likely rain.
- Overfitted Prediction: If the day of the week is Friday, the day of the month is an even number, the month of the year is after June,the current time is between 9:00 a.m. and 10:00 a.m., and your car is currently at the mechanic, then it will likely rain.
The second prediction is not good but overfitted because the conditions listed happened simultaneously very few times, so even if you always experience rain when the above conditions were met, you may fail to predict rain in the future.
Avoiding overfitting is one the biggest challenges when you build a prediction model. You can never know if the prediction is overfitted or if there is a real relationship.
Only the future will tell.
There are some techniques, however, that can help you, for example, cross-validating the efficiency of your model.
- Mixing Past and Future
If you want to predict something based on several different factors, be careful when selecting the predictors; they must be in the past compared to your target.
It may seem obvious, but if you have a dataset with many columns, you can be easily trapped. For example, do not predict a web-shop visitor’s chance of purchase based on the time spent on your web-shop that day. That “Total Minutes in Web Shop” column may also contain those minutes that are spent in your web-shop after purchasing.
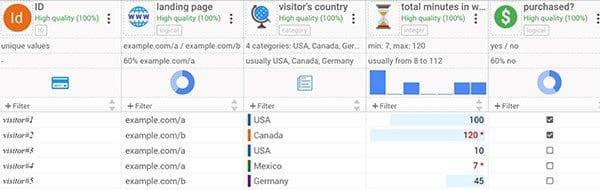
Historical data example
If you want to create a prediction using the above historical data table, do not include “Total Minutes in Web Shop.” You can include the predictors “Landing Page” and “Visitor’s Country” because this data is generated before the time of purchase.
- Outliers
Most numeric datasets contain outliers because of unclean or wrong data or because of some special exceptions.
Outliers are evil and ruin everything. Get rid of them before making any predictions, because the result of the mean calculation will be malformed.
Try to predict normally distributed data, instead of Cauchy-distributed.
- Measuring the Efficiency
You should always and continuously measure the efficiency of your prediction for these reasons:
- Too bad or even too good of a performance of a prediction indicates something is wrong with your model or prediction.
- You want to know what accuracy you can expect from the prediction model.
- Things change over time, so your prediction will be outdated at some point, and you want to detect that.
You should always compare the efficiency to some basic rule of thumb.For example, suppose you want to predict if there will be snow in Florida today, and you are building a complex prediction model to determine it.
If your model hits the real outcome (snow or no snow) at 90%, that is not good, because if you always guess no snow, then you would have 99% hit rate.
- Not Enough Predictors
People always make the mistake of using domain-specific knowledge only to improve their predictions. This is a problem mainly because they want to gather possible causes, but predictions have nothing to do with causality.
If you want to predict ice cream sales, do not use only ice cream-related predictors but also bikini or air-conditioner sales, amount of political news, or the federal base interest rate.
These factors do not influence ice cream sales, but they are correlated with them, so they can be used as predictors.
If you accidentally include a predictor that is not correlated with your target, it is not a problem the prediction algorithm will eliminate it automatically.
- Believing the Results
People want to believe that they have logical skills, have experience, are smart, are wise, and are rational. However, they are not; rather they are biased in many ways.
If you create a good prediction model and validate it, do not throw it away, saying,
“It cannot be.There is something wrong with the data.” or “I know my field better than an algorithm.”
Use your domain-specific expertise to create a prediction model, but once it is done, do not simply overwrite it.
- Applying the Results
There is no point in building prediction models if you do not apply them.Before creating predictions, always define the action you will take depending on the possible results.
Suppose you are building a prediction model to detect if a visitor to your web-shop will purchase something based on the visitor’s nationality, gender, browser version, landing page, and so on.
If you are unable to do anything with this information, it was pointless to predict. However, if you have a professional web developer and can dynamically throw discounts to users based on the prediction, you can give discounts only to those who are not likely to buy anything without it.
Additionally, if you predict that the user will buy from your web shop, then there is no need to lower your profits by giving him a discount.
I hope I was able to give you some useful tips in this article. Let me share one more thing with you. AnswerMiner can create predictions in no time based on many data sources.
Bio: Norbert Obsuszt is the founder of AnswerMiner, data scientist, and programmer. He took his degree in maths and programming. Norbert is passionate about Data Analytics, Predictive Analytics, and Data Science. He can be reached at norbert.obsuszt@answerminer.com
Related:
- Justice Can’t Be Colorblind: How to Fight Bias with Predictive Policing
- How To Debug Your Approach To Data Analysis
- Removing Outliers Using Standard Deviation in Python