CatBoost vs. Light GBM vs. XGBoost
Who is going to win this war of predictions and on what cost? Let’s explore.
By Alvira Swalin, University of San Francisco

I recently participated in this Kaggle competition (WIDS Datathon by Stanford) where I was able to land up in Top 10 using various boosting algorithms. Since then, I have been very curious about the fine workings of each model including parameter tuning, pros and cons and hence decided to write this blog. Despite the recent re-emergence and popularity of neural networks, I am focusing on boosting algorithms because they are still more useful in the regime of limited training data, little training time and little expertise for parameter tuning.
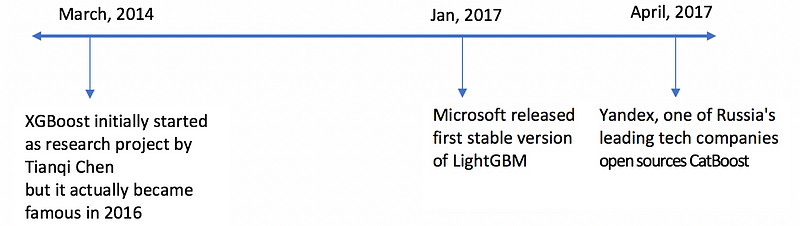
Since XGBoost (often called GBM Killer) has been in the machine learning world for a longer time now with lots of articles dedicated to it, this post will focus more on CatBoost & LGBM. Below are the topics we will cover-
- Structural Differences
- Treatment of categorical variables by each algorithm
- Understanding Parameters
- Implementation on Dataset
- Performance of each algorithm
Structural Differences in LightGBM & XGBoost
LightGBM uses a novel technique of Gradient-based One-Side Sampling (GOSS) to filter out the data instances for finding a split value while XGBoost uses pre-sorted algorithm & Histogram-based algorithm for computing the best split. Here instances means observations/samples.
First let us understand how pre-sorting splitting works-
- For each node, enumerate over all features
- For each feature, sort the instances by feature value
- Use a linear scan to decide the best split along that feature basis information gain
- Take the best split solution along all the features
In simple terms, Histogram-based algorithm splits all the data points for a feature into discrete bins and uses these bins to find the split value of histogram. While, it is efficient than pre-sorted algorithm in training speed which enumerates all possible split points on the pre-sorted feature values, it is still behind GOSS in terms of speed.
So what makes this GOSS method efficient? In AdaBoost, the sample weight serves as a good indicator for the importance of samples. However, in Gradient Boosting Decision Tree (GBDT), there are no native sample weights, and thus the sampling methods proposed for AdaBoost cannot be directly applied. Here comes gradient-based sampling.
Gradient represents the slope of the tangent of the loss function, so logically if gradient of data points are large in some sense, these points are important for finding the optimal split point as they have higher error
GOSS keeps all the instances with large gradients and performs random sampling on the instances with small gradients. For example, let’s say I have 500K rows of data where 10k rows have higher gradients. So my algorithm will choose (10k rows of higher gradient+ x% of remaining 490k rows chosen randomly). Assuming x is 10%, total rows selected are 59k out of 500K on the basis of which split value if found.
The basic assumption taken here is that samples with training instances with small gradients have smaller training error and it is already well-trained.
In order to keep the same data distribution, when computing the information gain, GOSS introduces a constant multiplier for the data instances with small gradients. Thus, GOSS achieves a good balance between reducing the number of data instances and keeping the accuracy for learned decision trees.
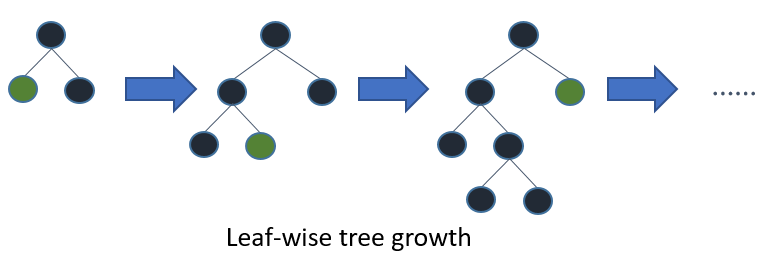
Leaf with higher gradient/error is used for growing further in LGBM
How each model treats Categorical Variables?
CatBoost
CatBoost has the flexibility of giving indices of categorical columns so that it can be encoded as one-hot encoding using one_hot_max_size (Use one-hot encoding for all features with number of different values less than or equal to the given parameter value).
If you don’t pass any anything in cat_features argument, CatBoost will treat all the columns as numerical variables.
Note: If a column having string values is not provided in the cat_features, CatBoost throws an error. Also, a column having default int type will be treated as numeric by default, one has to specify it in cat_features to make the algorithm treat it as categorical.

For remaining categorical columns which have unique number of categories greater than one_hot_max_size, CatBoost uses an efficient method of encoding which is similar to mean encoding but reduces overfitting. The process goes like this —
- Permuting the set of input observations in a random order. Multiple random permutations are generated
- Converting the label value from a floating point or category to an integer
- All categorical feature values are transformed to numeric values using the following formula:
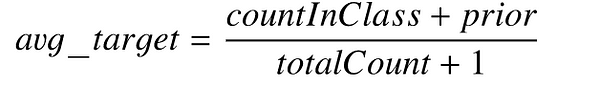
Where, CountInClass is how many times the label value was equal to “1” for objects with the current categorical feature value Prior is the preliminary value for the numerator. It is determined by the starting parameters. TotalCount is the total number of objects (up to the current one) that have a categorical feature value matching the current one.
Mathematically, this can be represented using below equation:
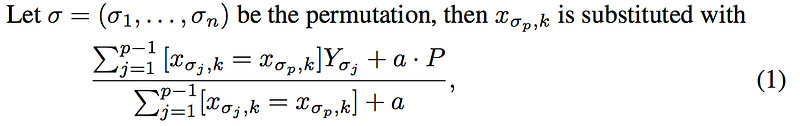
LightGBM
Similar to CatBoost, LightGBM can also handle categorical features by taking the input of feature names. It does not convert to one-hot coding, and is much faster than one-hot coding. LGBM uses a special algorithm to find the split value of categorical features [Link].

Note: You should convert your categorical features to int type before you construct Dataset for LGBM. It does not accept string values even if you passes it through categorical_feature parameter.
XGBoost
Unlike CatBoost or LGBM, XGBoost cannot handle categorical features by itself, it only accepts numerical values similar to Random Forest. Therefore one has to perform various encodings like label encoding, mean encoding or one-hot encoding before supplying categorical data to XGBoost.
Similarity in Hyperparameters
All these models have lots of parameters to tune but we will cover only the important ones. Below is the list of these parameters according to their function and their counterparts across different models.
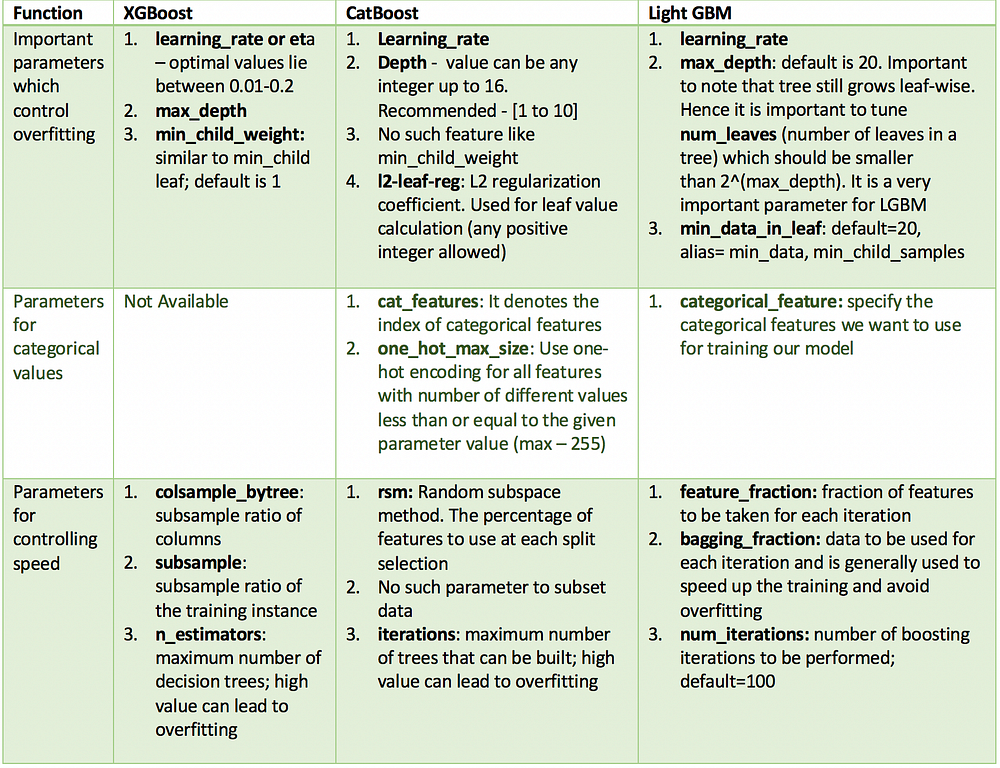
Implementation on a Dataset
I am using the Kaggle Dataset of flight delays for the year 2015 as it has both categorical and numerical features. With approximately 5 million rows, this dataset will be good for judging the performance in terms of both speed and accuracy of tuned models for each type of boosting. I will be using a 10% subset of this data ~ 500k rows.
Below are the features used for modeling:
- MONTH, DAY, DAY_OF_WEEK: data type int
- AIRLINE and FLIGHT_NUMBER: data type int
- ORIGIN_AIRPORT and DESTINATION_AIRPORT: data type string
- DEPARTURE_TIME: data type float
- ARRIVAL_DELAY: this will be the target and is transformed into boolean variable indicating delay of more than 10 minutes
- DISTANCE and AIR_TIME: data type float
XGBoost
Light GBM
CatBoost
While tuning parameters for CatBoost, it is difficult to pass indices for categorical features. Therefore, I have tuned parameters without passing categorical features and evaluated two model — one with and other without categorical features. I have separately tuned one_hot_max_size because it does not impact the other parameters.
Results
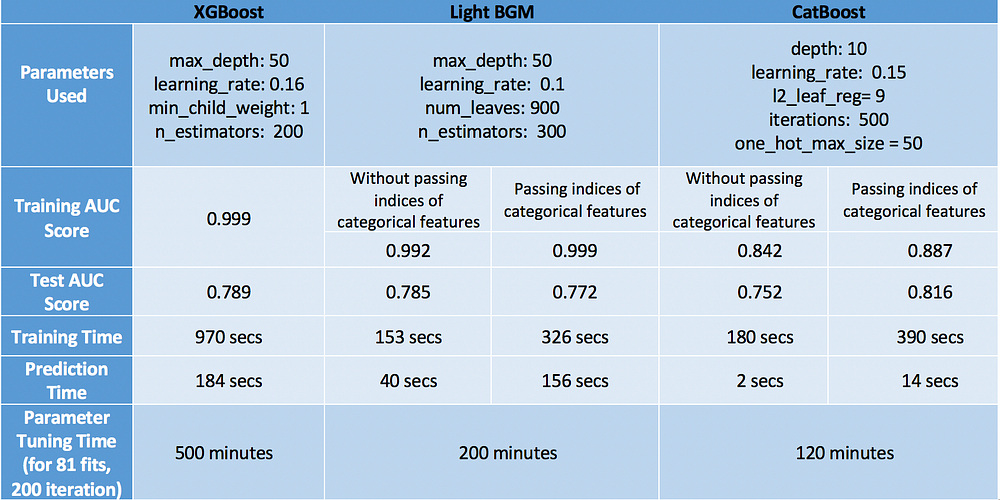
End Notes
For evaluating model, we should look into the performance of model in terms of both speed and accuracy.
Keeping that in mind, CatBoost comes out as the winner with maximum accuracy on test set (0.816), minimum overfitting (both train and test accuracy are close) and minimum prediction time & tuning time. But this happened only because we considered categorical variables and tuned one_hot_max_size. If we don’t take advantage of these features of CatBoost, it turned out to be the worst performer with just 0.752 accuracy. Hence we learnt that CatBoost performs well only when we have categorical variables in the data and we properly tune them.
Our next performer was XGBoost which generally works well. It’s accuracy was quite close to CatBoost even after ignoring the fact that we have categorical variables in the data which we had converted into numerical values for its consumption. However, the only problem with XGBoost is that it is too slow. It was really frustrating to tune its parameters especially (took me 6 hours to run GridSearchCV — very bad idea!). The better way is to tune parameters separately rather than using GridSearchCV. Check out this blogpost to understand how to tune parameters smartly.
Finally, the last place goes to Light GBM. An important thing to note here is that it performed poorly in terms of both speed and accuracy when cat_features is used. I believe the reason why it performed badly was because it uses some kind of modified mean encoding for categorical data which caused overfitting (train accuracy is quite high — 0.999 compared to test accuracy). However if we use it normally like XGBoost, it can achieve similar (if not higher) accuracy with much faster speed compared to XGBoost (LGBM — 0.785, XGBoost — 0.789).
Lastly, I have to say that these observations are true for this particular dataset and may or may not remain valid for other datasets. However, one thing which is true in general is that XGBoost is slower than the other two algorithms.
So which one is your favorite? Please comment with the reasons.
Any feedback or suggestions for improvement will be really appreciated!
Check out my other blogs here!
Resources
- http://learningsys.org/nips17/assets/papers/paper_11.pdf
- https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
- https://arxiv.org/pdf/1603.02754.pdf
- https://github.com/Microsoft/LightGBM
- https://www.analyticsvidhya.com/blog/2017/06/which-algorithm-takes-the-crown-light-gbm-vs-xgboost/
- https://stats.stackexchange.com/questions/307555/mathematical-differences-between-gbm-xgboost-lightgbm-catboost
Bio: Alvira Swalin (Medium) is currently pursuing Master's in Data Science at USF, I am particularly interested in Machine Learning & Predictive Modeling. She is a Data Science Intern at Price (Fx).
Original. Reposted with permission.
Related:
- Gradient Boosting in TensorFlow vs XGBoost
- Lessons Learned From Benchmarking Fast Machine Learning Algorithms
- XGBoost: A Concise Technical Overview