Top 5 Advantages That CatBoost ML Brings to Your Data to Make it Purr
This article outlines the advantages of CatBoost as a GBDTs for interpreting data sources that are highly categorical or contain missing data points.

Image by Editor
Businesses worldwide are increasingly expecting their decision-making processes to be informed by data-driven predictive analytics systems, or at least they should be. From timely investment to fulfillment logistics to fraud prevention, data is being leveraged in an increasing number of workflows, with an increasing number of eyes on it. In other words, streams of information that were often relegated to data scientists are now being viewed – and manipulated – by people less savvy in the data dark arts.
Today, relative data laypersons may suddenly find themselves with the responsibility to both contribute to data pools and interpret their ML analysis of them. This could lead to situations that make your data spit and hiss at you, instead of purring cooperatively. To mitigate the potential of scratches from poor data hygiene bites from overfitting, or worse, CatBoost leaps up onto the kitchen table, clearly presenting itself as the best option for many verticals.
The Benefits of Owning a Cat(Boost)
CatBoost is a gradient-boosting ML system that sets itself apart from other GBDTs by offering unique solutions for interpreting data sources that are highly categorical or contain missing data points. Indeed, this is where the API gets its name, from Boosting Categories, rather than from some feline origin. Side-by-side comparisons show that CatBoost also outperforms XGBoost and LightBGM significantly in terms of prediction delivery time and parameter tuning time, while remaining comparable in other metrics.
Under the hood, CatBoost achieves this by using the split-by-popularity method to create symmetrical decision trees. By grouping features into a single split with only a left and right child, the necessary processing power and time are greatly reduced when compared to trees with children for each individual feature in a set. These features could be categorical or numerical. They can then be parsed at different levels of the tree until the target variable is met. This effectively regularizes the data, discouraging data points from developing explicit correlations by offering multiple viewpoints on the same subsets. This gives CatBoost’s predictions more resilience from both overfitting and generalization errors in the training process.
While these points are obviously advantageous from a data science and computational perspective, their benefits across an entire organization might be less apparent.
CatBoost, An Operational Support Animal
So, it doesn’t greet you with your slippers when you arrive at home, it doesn’t return the care and attention you give it in an affectionate way, so how exactly does CatBoost improve your operations? How does CatBoost’s computational efficiency actually help with essential business functions, and for whom? There are certain elements of CatBoost’s algorithm that seem like small differences compared to similar ML systems, but translate into huge logistical dividends for many businesses.
We’re going to zoom in on several such components, then zoom back out to see how their real-world implementations help streamline processes and ultimately save money – saving money is a language everyone in the company speaks. Businesses might recognize some of their granular pain points being addressed as we explore, especially if they got scratched, or even scarred.
5 Ways CatBoost Can Housebreak Your Data
For each of these nuances within the open-source API, there are practical benefits that are immediately obvious to data scientists. For the increasing number of non-tech teams being asked to participate in data analysis chain of their companies, as well as those people whose job it is to approve ML workflows, it is decidedly less obvious.
1: No need for one-hot encoding
CatBoost handles categorical features in plaintext, avoiding the need for extensive preprocessing, as with other GBDTs that insist on numerical inputs. The most common preprocessing method for categorical data is labeling it though one-hot encoding, which breaks data into a binary, though in some cases using a dummy, ordinal, LOO, or Bayesian target encoding method is more applicable, depending on the nature of the data. Categorical features preprocessed via one-hot encoding can often be expansive and become overly dimensional quickly. Through CatBoost’s in-built ordinal encoding system, categorical features are assigned a numerical value, but the long processing times and overfitting characteristics of highly dimensional data are avoided.
Though these calculations might happen in the cloud, the on-the-ground benefits include:
- As the API handles text-based categorical data natively, there are less calculations and less transformations of the data that are required, which results in less error.
- Compared to one-hot encoding, CatBoost breaks data into less features, increasing simplicity and ultimately interpretability for analyst teams.
- Text-based data that gets fed into the library gets returned with the same text label, also streamlining interpetability.
- CatBoost facilitates deep analysis by making it easy to focus on a single feature’s contribution to the model, rather than a specific value of a specific feature, as is the case with one-hot encoded columns. Using the get_feature_importance()method, CatBoost measures the features using SHAP values, which can also be easily visualized for interpretation and analysis (see below).
- By the same token, this usage of categorical data allows staff from across departments the ability to both enter and interpret data much more easily.
- This level of accessibility allows companies to have unified data streams, so all arms of the company are referring to a single pool of information. Companies that have been bitten by interdepartmental confusion from having multiple profiles of a single entity know how many stresses and resources this can save.
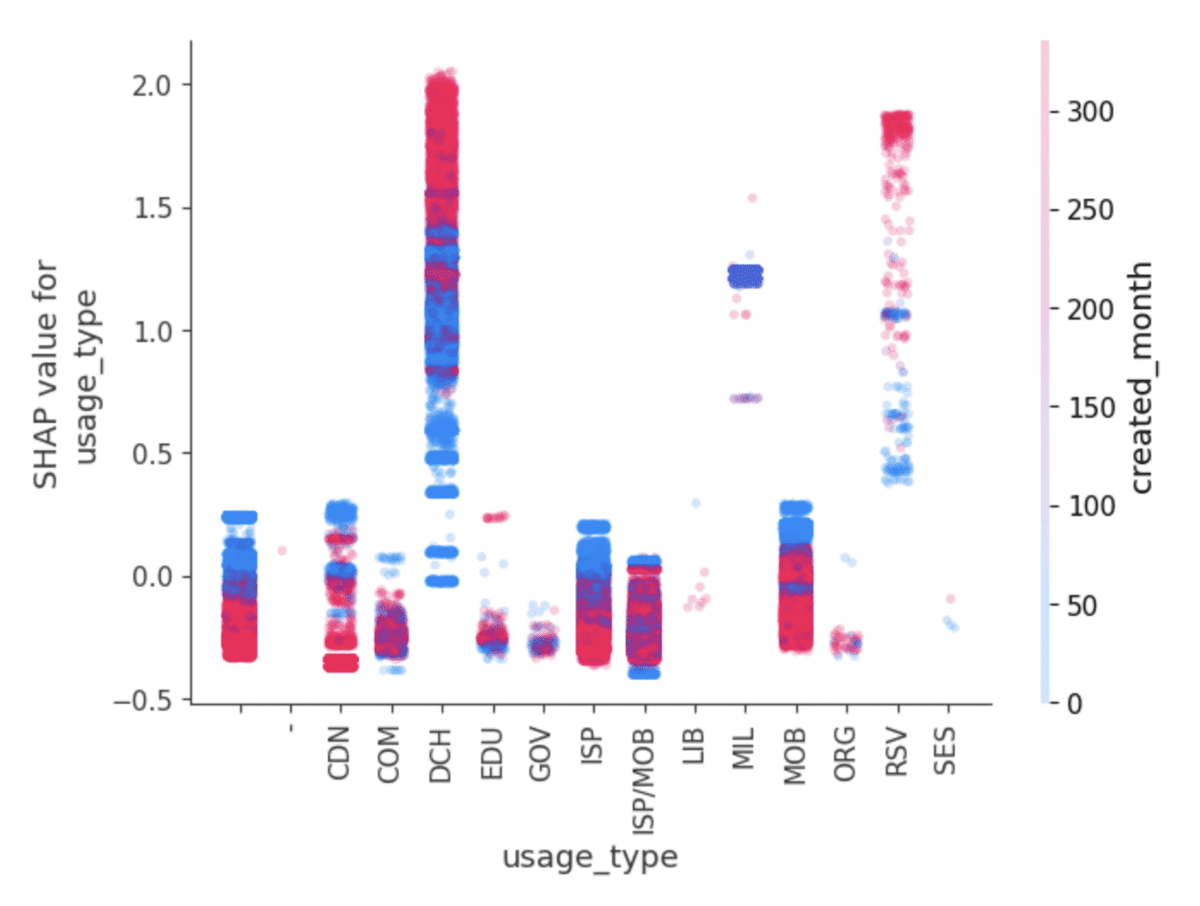
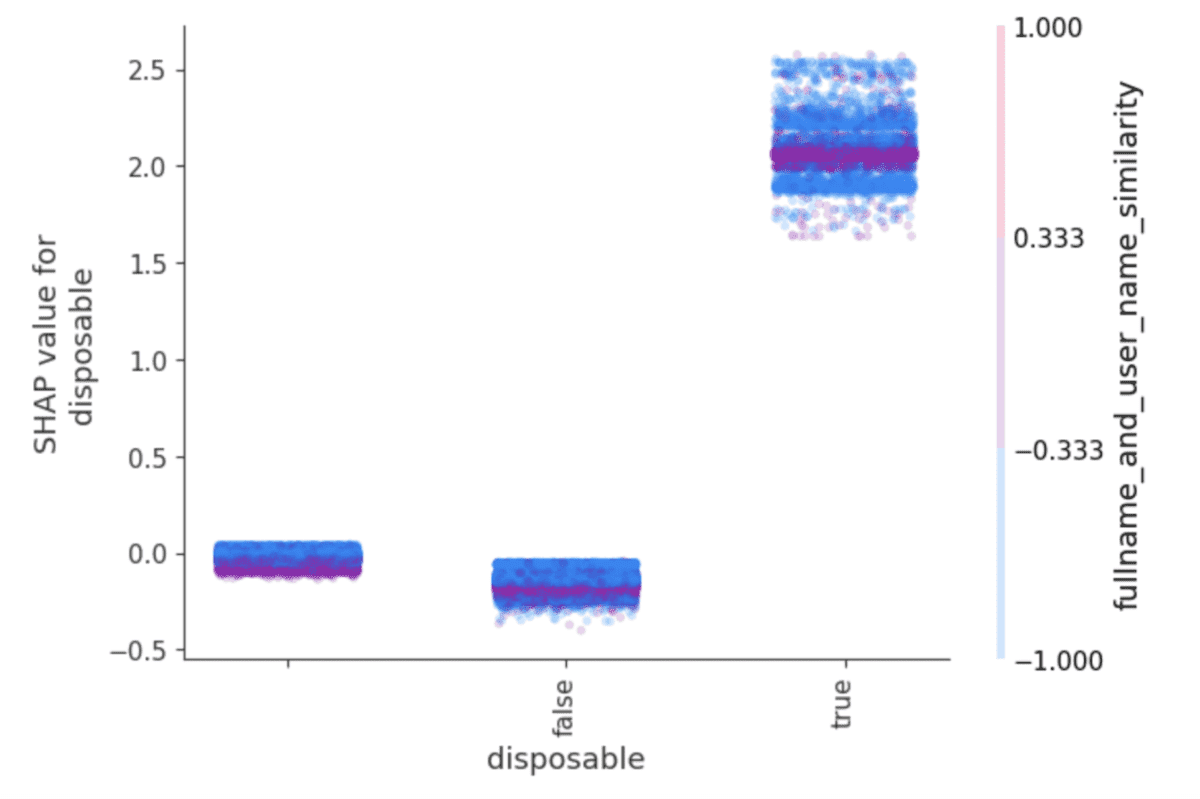
CatBoost natively hosts the SHAP library, facilitating output visualizations like these, which were trained on fraud prevention data.
This aspect of CatBoost’s API is an obvious advantage for verticals working with data that is inherently less numerical than, say, financial forecasting. Areas like medical diagnosis, fraud prevention, market segmentations, and advertising are all fields that deal with large amounts of categorical data, and would benefit from CatBoost’s deft claws at dealing with it.
2: Oblivious trees

CatBoost leverages oblivious decision trees as the base learner in its gradient boosting process. This means that each tree is limited to a single symmetrical split, with either side being balanced by the algorithm’s built-in feature importance measurement.
Rather than have nodes split multiple times for a highly dimensional feature, as with XGBoost, CatBoost instead creates multiple levels to analyze a single feature. This gives it the ability to shine when it comes to:
- Optimizing processing time and power. Highly dimensional non-numerical data will inevitably require more processing time and power when pushed through XGBoost compared to CatBoost. A single split in each node means significantly faster processing speed for each decision, cutting down on energy usage and optimizing wait times, internally or externally.
- Regularization and robustness against overfitting. Algorithms that take features and split trees into all possible outcomes of that feature will notice their data overfitting often. By limiting the complexity of each level of the tree, it essentially creates a more rigid regression line through your data, a sort of de facto regularization. This results in less false negatives and false positives, which could translate into how your organization uses its data in any number of ways.
- Ease of interpretability. Again, depending on the industry and what process is being automated, there may be good reason to be able to explain how a given ML determination was made. This could be to satisfy a customer, but could also be part of legal compliance when it comes to having transparently fair practices or performing safety due diligence.
The oblivious tree model of CatBoost is what gives it most of its processing lightness, and also makes it a highly scalable option for large datasets. When handling categorical data, CatBoost is much more efficient at drawing conclusions quickly while also disregarding data noise. In the fields of market segmentation, automated supply chain optimization, PPC advertising, for example, noisy data is sometimes the reason a seemingly random advertisement gets targeted at your device, or a chain store has too much or too little of something.
3: Data “Nan Handling”
Datasets with missing values are, of course, less useful for analysis in general. When approaching numerical datasets, tather than let those missing values affect the stability of the model, CatBoost automatically replaces the missing values. Depending on the size of the subset, the value is either replaced through simple calculations, or else through machine-learning derived relationships between features. Those relationships may be only borderline explainable, but the explainable benefits in actual work processes include:
- Better performance in terms of accuracy and false positive rates, turning into smoother processes anywhere data is being analyzed by CatBoost.
- In the case of fraud prevention, null values can themselves be useful as indicators of potential risk.
- Facilitates bespoke models for individual customers, as each will have different processes, and will have different data and nan ratios (rate of Not a Number entries in datasets).
- Other verticals like healthcare, banking, customer analytics, and supply chain management make good use of nan handling – consider anywhere someone on the data entry chain, from new customers to fulfillment agents, might be inclined to not fill in part of a form. Sometimes this could be laziness, other times, it could indicate attempted application fraud.
Notably, CatBoost only handles numerical data nan handling natively. For categorical data, an individual category along the lines of “empty string” or “missing value” should be created in order for these NaN values to be considered in the symmetrical split.
Here’s an example of how to easily handle the nan values in categorical data:
for col in df.columns:
if df[col].dtype.name in ("bool", "object", "category"):
if (df[col].dtype.name == "category" and
("" not in df[col].cat.categories)):
df[col] = df[col].cat.add_categories([""])
df[col] = df[col].fillna("")
4: Parallel Processing (Zoomies)
As mentioned above, CatBoost’s single, symmetrical split is greatly beneficial to processing power and prediction speed.
There are two main reasons for this. The first is the symmetrical tree structure’s ability to reach a prediction through vector multiplication. Where other gradient-boosting libraries would perform these calculations at each level of the tree, CatBoost can apply it to the entire tree, drastically speeding up prediction generation.
The second explanation for CatBoost’s speed is its sort-by-popularity feature, which takes dimensional data and groups it into two equal branches, as opposed to creating a possible branch for each feature. Naturally, a single split takes less energy to navigate than 5, but having this kind of organization lends itself easy to parallel processing – splitting data into subsets to divide the task across multiple processors. Depending on the available hardware resources, CatBoost can also find the method of parallel processing that is most optimal.
Apart from the obvious benefits of lower energy consumption and faster overall processes, consider some ways that customer and partner experiences might be affected by inefficient data handling:
- Internal workflows are often fraught with small wait times that can balloon into larger ones. We all know this.
- Small wait times for risk analysis, fraud prevention, age verification, and other security measures can make or break an online experience. Churn obviously increases as high-friction wait times do.
5: Cuteness factor
CatBoost is quite endearing compared to similar ML algorithms. Regardless of the level of machine learning or data expertise, the API can be learned with its clear and understandable documentation. Consider these features together:
- Explains hypertuning parameters to understand what specific problem is being solved
- Automatically handles categorical data including pre-processing
- Has a robust model that is generally deployable out-of-box
- Advanced visualizations
from catboost import CatBoostRegressor
from sklearn.datasets import load_boston
boston_data = load_boston()
model = CatBoostRegressor(
depth=2, verbose=False, iterations=1).fit(
boston_data['data'], boston_data['target'])
The code block above showcases how clean and easy a CatBoost model can be trained on a boston dataset. This is a good example of how CatBoost creates a more approachable environment than some, especially considering the large and active community around the product.
The benefits of this approachability should be clear, particularly for people with experience onboarding themselves to new pieces of advanced business software. In general, being able to include a wider range of team members in data processes without scaring them off is valuable for distributing responsibilities and optimizing resource distribution.
Are You A CatBoost Person or…
Though it was designed with speed and efficiency for categorical data specifically, CatBoost handles numerical data with the same deftness. That said, there are some areas that could certainly be just as well-suited with XGBoost or LightGBM. These two algorithms were designed with speed and scalability in mind, including purely numerical data that is highly dimensional and constantly changing. So verticals that deal with very large datasets that are inherently complete and in flux, may do better with one of these two APIs, like:
- financial forecasting
- energy distribution
- supply chain management
LightGBM in particular thrives in places where processing speed is critical, such as natural language processing and image recognition.
As data becomes more omnipresent within the business functions of an increasingly digitized corporate space, data solutions need to be more accessible. Verticals like advertising, market analysis, customer segmentation, fraud prevention, and medical treatment, CatBoost is likely a good match. Many kinds of finance, too. Though it may never be as accessible as an actual housecat, in many cases CatBoost may be more friendly, and certainly more useful.
Gellért Nacsa is the Data Science Lead at SEON. He studied applied mathematics at university and worked as a data analyst, algorithm designer, and data scientist. He enjoys playing with data, machine learning, and learning new stuff all the time.