Fast Gradient Boosting with CatBoost
In this piece, we’ll take a closer look at a gradient boosting library called CatBoost.
In gradient boosting, predictions are made from an ensemble of weak learners. Unlike a random forest that creates a decision tree for each sample, in gradient boosting, trees are created one after the other. Previous trees in the model are not altered. Results from the previous tree are used to improve the next one. In this piece, we’ll take a closer look at a gradient boosting library called CatBoost.
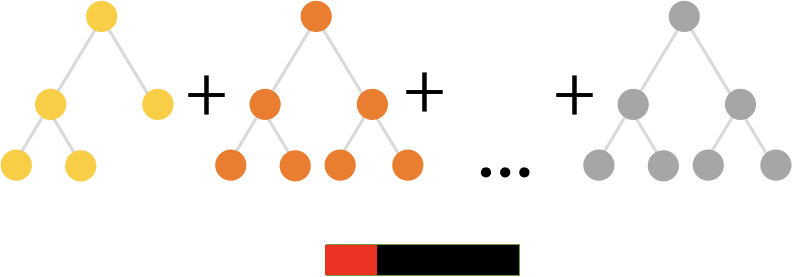
CatBoost is a depth-wise gradient boosting library developed by Yandex. It uses oblivious decision trees to grow a balanced tree. The same features are used to make left and right splits for each level of the tree.
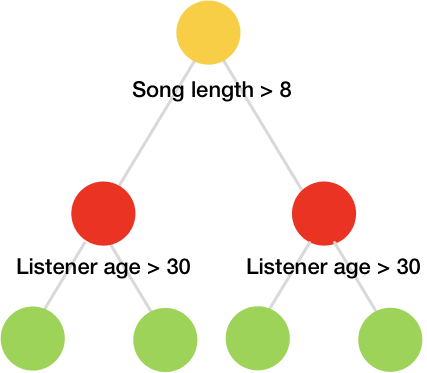
As compared to classic trees, the oblivious trees are more efficient to implement on CPU and are simple to fit.
Dealing with Categorical Features
The common ways of handling categorical in machine learning are one-hot encoding and label encoding. CatBoost allows you to use categorical features without the need to pre-process them.
When using CatBoost, we shouldn’t use one-hot encoding, as this will affect the training speed, as well as the quality of predictions. Instead, we simply specify the categorical features using the cat_features parameter.
Advantages of using CatBoost
Here are a few reasons to consider using CatBoost:
- CatBoost allows for training of data on several GPUs.
- It provides great results with default parameters, hence reducing the time needed for parameter tuning.
- Offers improved accuracy due to reduced overfitting.
- Use of CatBoost’s model applier for fast prediction.
- Trained CatBoost models can be exported to Core ML for on-device inference (iOS).
- Can handle missing values internally.
- Can be used for regression and classification problems.
Training Parameters
Let’s look at the common parameters in CatBoost:
loss_functionalias asobjective— Metric used for training. These are regression metrics such as root mean squared error for regression and logloss for classification.eval_metric— Metric used for detecting overfitting.iterations— The maximum number of trees to be built, defaults to 1000. It aliases arenum_boost_round,n_estimators, andnum_trees.learning_ratealiaseta— The learning rate that determines how fast or slow the model will learn. The default is usually 0.03.random_seedaliasrandom_state— The random seed used for training.l2_leaf_regaliasreg_lambda— Coefficient at the L2 regularization term of the cost function. The default is 3.0.bootstrap_type— Determines the sampling method for the weights of the objects, e.g Bayesian, Bernoulli, MVS, and Poisson.depth—The depth of the tree.grow_policy— Determines how the greedy search algorithm will be applied. It can be eitherSymmetricTree,Depthwise, orLossguide.SymmetricTreeis the default. InSymmetricTree, the tree is built level-by-level until the depth is attained. In every step, leaves from the previous tree are split with the same condition. WhenDepthwiseis chosen, a tree is built step-by-step until the specified depth is achieved. On each step, all non-terminal leaves from the last tree level are split. The leaves are split using the condition that leads to the best loss improvement. InLossguide, the tree is built leaf-by-leaf until the specified number of leaves is attained. On each step, the non-terminal leaf with the best loss improvement is splitmin_data_in_leafaliasmin_child_samples— This is the minimum number of training samples in a leaf. This parameter is only used with theLossguideandDepthwisegrowing policies.max_leavesaliasnum_leaves— This parameter is used only with theLossguidepolicy and determines the number of leaves in the tree.ignored_features— Indicates the features that should be ignored in the training process.nan_mode— The method for dealing with missing values. The options areForbidden,Min, andMax. The default isMin. WhenForbiddenis used, the presence of missing values leads to errors. WithMin, the missing values are taken as the minimum values for that feature. InMax, the missing values are treated as the maximum value for the feature.leaf_estimation_method— The method used to calculate values in leaves. In classification, 10Newtoniterations are used. Regression problems using quantile or MAE loss use oneExactiteration. Multi classification uses oneNetwoniteration.leaf_estimation_backtracking— The type of backtracking to be used during gradient descent. The default isAnyImprovement.AnyImprovementdecreases the descent step, up to where the loss function value is smaller than it was in the last iteration.Armijoreduces the descent step until the Armijo condition is met.boosting_type— The boosting scheme. It can beplainfor the classic gradient boosting scheme, orordered, which offers better quality on smaller datasets.score_function— The score type used to select the next split during tree construction.Cosineis the default option. The other available options areL2,NewtonL2, andNewtonCosine.early_stopping_rounds— WhenTrue, sets the overfitting detector type toIterand stops the training when the optimal metric is achieved.classes_count— The number of classes for multi-classification problems.task_type— Whether you are using a CPU or GPU. CPU is the default.devices— The IDs of the GPU devices to be used for training.cat_features— The array with the categorical columns.text_features—Used to declare text columns in classification problems.
Regression Example
CatBoost uses the scikit-learn standard in its implementation. Let’s see how we can use it for regression.
The first step — as always — is to import the regressor and instantiate it.
from catboost import CatBoostRegressor
cat = CatBoostRegressor()When fitting the model, CatBoost also enables use to visualize it by setting plot=true:
cat.fit(X_train,y_train,verbose=False, plot=True)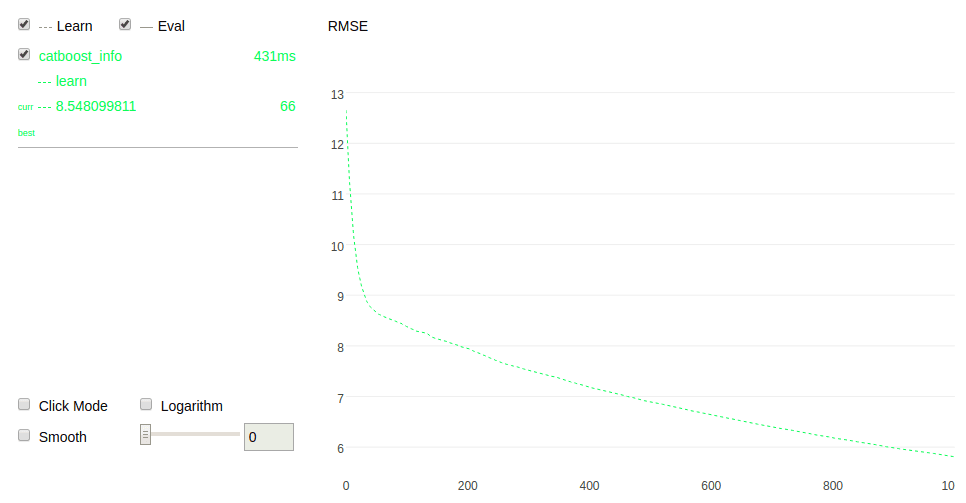
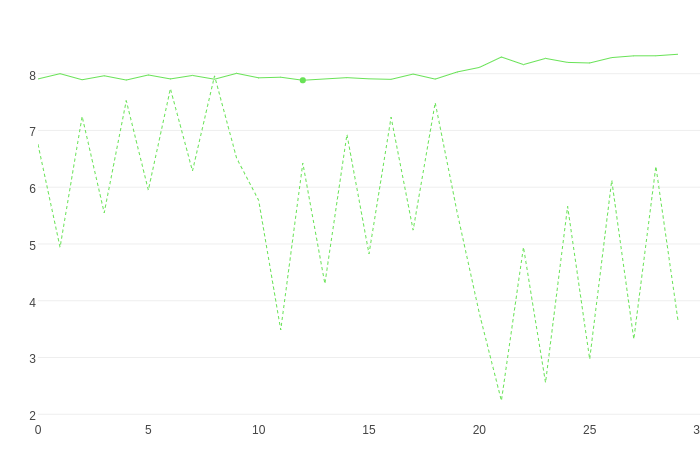
It also allows you to perform cross-validation and visualize the process:
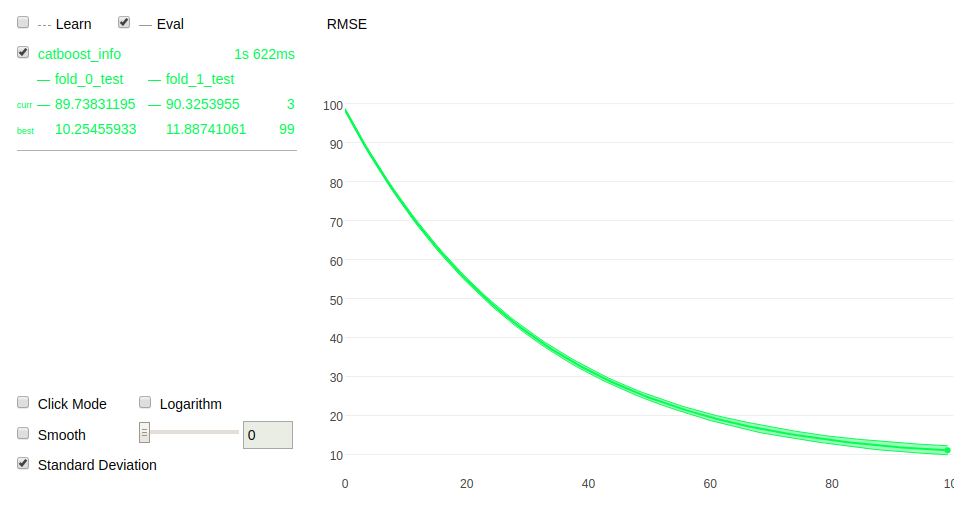
Similarly, you can also perform grid search and visualize it:
We can also use CatBoost to plot a tree. Here’s the plot is for the first tree. As you can see from the tree, the leaves on every level are being split on the same condition—e.g 297, value >0.5.
cat.plot_tree(tree_idx=0)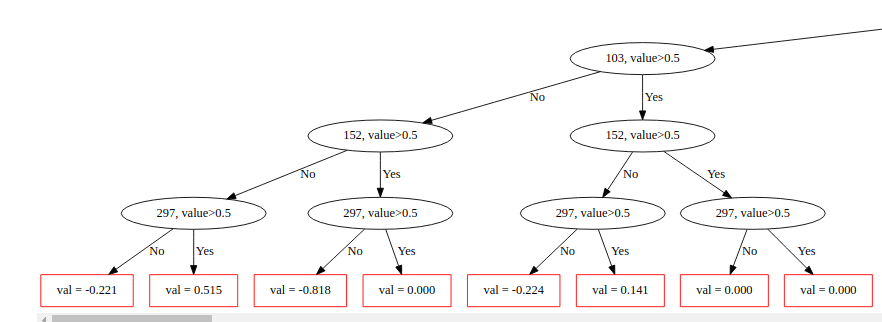
CatBoost also gives us a dictionary with all the model parameters. We can print them by iterating through the dictionary.
for key,value in cat.get_all_params().items():
print(‘{}, {}’.format(key,value))
Final Thoughts
In this piece, we’ve explored the benefits and limitations of CatBoost, along with its primary training parameters. Then, we worked through a simple regression implementation with scikit-learn. Hopefully this gives you enough information on the library so that you can explore it further.
CatBoost - state-of-the-art open-source gradient boosting library with categorical features support
CatBoost is an algorithm for gradient boosting on decision trees. It is developed by Yandex researchers and engineers...
The Data Science Bootcamp in Python
Learn Python for Data Science,NumPy,Pandas,Matplotlib,Seaborn,Scikit-learn, Dask,LightGBM,XGBoost,CatBoost and much...
Bio: Derrick Mwiti is a data analyst, a writer, and a mentor. He is driven by delivering great results in every task, and is a mentor at Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- LightGBM: A Highly-Efficient Gradient Boosting Decision Tree
- Understanding Gradient Boosting Machines
- Mastering Fast Gradient Boosting on Google Colaboratory with free GPU