LightGBM: A Highly-Efficient Gradient Boosting Decision Tree
LightGBM is a histogram-based algorithm which places continuous values into discrete bins, which leads to faster training and more efficient memory usage. In this piece, we’ll explore LightGBM in depth.
The power of the LightGBM algorithm cannot be taken lightly (pun intended). LightGBM is a distributed and efficient gradient boosting framework that uses tree-based learning. It’s histogram-based and places continuous values into discrete bins, which leads to faster training and more efficient memory usage. In this piece, we’ll explore LightGBM in depth.
LightGBM Advantages
According to the official docs, here are the advantages of the LightGBM framework:
- Faster training speed and higher efficiency
- Lower memory usage
- Better accuracy
- Support of parallel and GPU learning
- Capable of handling large-scale data
Parameter Tuning
The framework uses a leaf-wise tree growth algorithm, which is unlike many other tree-based algorithms that use depth-wise growth. Leaf-wise tree growth algorithms tend to converge faster than depth-wise ones. However, they tend to be more prone to overfitting.
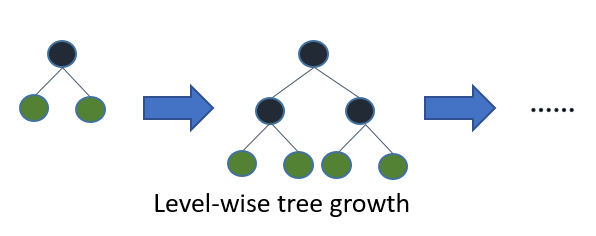
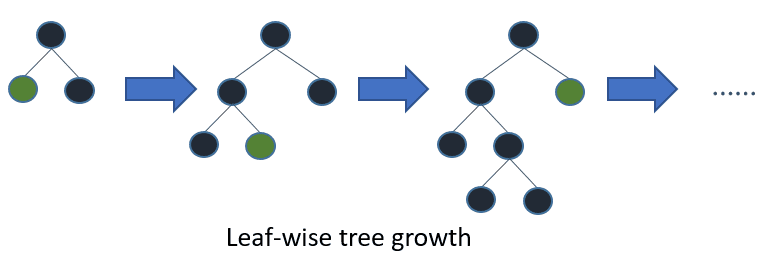
Here are the parameters we need to tune to get good results on a leaf-wise tree algorithm:
num_leaves: Setting the number of leaves tonum_leaves = 2^(max_depth)will give you the same number of leaves as a depth-wise tree. However, it isn’t a good practice. Ideally, the number of leaves should be smaller than2^(max_depth)min_data_in_leafprevents overfitting. It’s set depending onnum_leavesand the number of training samples. For a large dataset, it can be set to hundreds or thousands.max_depthfor limiting the depth of the tree.
Faster speeds on the algorithm can be obtained by using:
- a small
max_bin save_binaryto speed up data loading in future learning- parallel learning
- bagging, through setting
bagging_freqandbagging_fraction feature_fractionfor feature sub-sampling
In order to get better accuracy, one can use a large max_bin, use a small learning rate with large num_iterations, and use more training data. One can also use many num_leaves, but it may lead to overfitting. Speaking of overfitting, you can deal with it by:
- Increasing
path_smooth - Using a larger training set
- Trying
lambda_l1,lambda_l2, andmin_gain_to_splitfor regularization - Avoid growing a very deep tree
Machine learning is rapidly moving closer to where data is collected — edge devices. Subscribe to the Fritz AI Newsletter to learn more about this transition and how it can help scale your business.
Categorical Features
A common way of processing categorical features in machine learning is one-hot encoding. This method is not optimal for tree learners, and especially for high-cardinality categorical features. Trees built on one-hot encoded features are unbalanced and have to grow too deep in order to obtain good accuracy.
Using the categorical_feature attribute, we can specify categorical features (without one-hot encoding) for their model. Categorical features should be encoded as non-negative integers less than Int32.MaxValue. They should start from zero.
LightGBM Applications
LightGBM can be best applied to the following problems:
- Binary classification using the
loglossobjective function - Regression using the
L2loss - Multi-classification
- Cross-entropy using the
loglossobjective function - LambdaRank using
lambdarankwith NDCG as the objective function
Metrics
The metrics supported by LightGBM are:
- L1 loss
- L2 loss
- Log loss
- Classification error rate
- AUC
- NDCG
- MAP
- Multi-class log loss
- Multi-class error rate
- Fair
- Huber
- Poisson
- Quantile
- MAPE
- Kullback-Leibler
- Gamma
- Tweedie
Handling Missing Values
By default, LightGBM is able to handle missing values. You can disable this by setting use_missing=false. It uses NA to represent missing values, but to use zero you can set it zero_as_missing=true.
Core Parameters
Here are some of the core parameters for LightGBM:
taskdefaults totrain. Other options arepredict,convert_model, andrefit. The alias for this parameter istask_type.convert_modelconverts the model into an if-else format.objectivedefaults to regression. The other options areregression_l1,huber,fair,poisson,quantile,mape,gamma,tweedie,binary,multiclass,multiclassova,cross_entropy,cross_entropy_lambda,lambdarank, andrank_xendcg. The aliases for this parameter areobjective_type,app, andapplication.boostingdefaults togbdt— a traditional Gradient Boosting Decision Tree. Other options arerf, — Random Forest,dart, — Dropouts meet Multiple Additive Regression Trees,goss— Gradient-based One-Side Sampling. This parameter’s aliases areboosting_typeandboost.num_leaves: maximum tree leaves for base learners — defaults to 31max_depth: maximum tree depth for base learnerslearning_rate: the boosting learning raten_estimators: number of boosted trees to fit — defaults to 200000importance_type: the type of importance to be filled in thefeature_importances_. Usingsplitmeans that the number of times a feature is used in a model will be contained in the result.device_type: device for the tree learning — CPU Or GPU. Can be used withdeviceas the alias.
Learning Control Parameters
Let’s look at a couple of learning control parameters:
force_col_wise: When set to true, it forces col-wise histogram building. It’s recommended to set this to true when the number of columns is large, or the total number of bins is large. You can also set it to true when you want to reduce cost on memory, and when thenum_threadsis large, e.g greater than 20. This parameter is only used with a CPU.force_row_wise: When set to true, it forces row-wise histogram building. This parameter is only used with a CPU. You can turn this one on when the number of data points is large, the total number of bins is smaller, and when thenum_threadsis small (e.g. less than or equal to 16). It can also be set to true when you want to use a smallbagging_fractionorgossboosting to speed up training.neg_bagging_fraction: Used for imbalanced binary classification problems.bagging_freq: The frequency for bagging. Zero means bagging is disabled.feature_fraction: Can be used to deal with overfitting. For instance, setting it to 0.5 would mean that LightGBM will select 50% of the features at each tree node.extra_trees: Set to true when you want to use extremely randomized trees.early_stopping_round: When true, training stops once a certain parameter fails to improve.max_drop: Defaults to 50. Signifies the number of trees to drop on every iteration.cat_l2: L2 regularization in a categorical splitcat_smooth: Reduces the effect of noise in categorical features, especially for categories with limited data.path_smooth: Helps prevent overfitting on leaves with few samples.
Objective Parameters
Here are a couple of objective parameters to take note of:
is_unbalance: Can be set to true if the training data is unbalanced for classification problems.num_class: Used to indicate the number of classes in a multi-classification problem.scale_pos_weight: Weight of labels with positive class. Cannot be used together withis_unbalance. This parameter increases the overall performance metric of the model but may result in poor estimates of the individual class probabilities.
Practical Implementation
We’ll now look at a quick implementation of the algorithm. We’ll use scikit-lean’s wrapper for the classifier.
As always, we start by importing the model:
from lightgbm import LGBMClassifierThe next step is to create an instance of the model while setting the objective. The options for the objective are regression for LGBMRegressor, binary or multi-class for LGBMClassifier, and LambdaRank for LGBMRanker.
model = LGBMClassifier(objective=’multiclass’)When fitting the model, we can set the categorical features:
model.fit(X_train,y_train,categorical_feature=[0,3])Once you run predictions on the model, you can also obtain the important features:
predictions = model.predict(X_test)importances = model.feature_importances_
Conclusion
I hope that this has given you enough background into LightGBM to start experimenting on your own. We’ve seen that we can use it for both regression and classification problems. For more information on the framework, you can check out the official docs:
Welcome to LightGBM's documentation! - LightGBM 2.3.2 documentation
LightGBM is a gradient boosting framework that uses tree based learning algorithms. It is designed to be distributed...
Bio: Derrick Mwiti is a data analyst, a writer, and a mentor. He is driven by delivering great results in every task, and is a mentor at Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- Research Guide: Advanced Loss Functions for Machine Learning Models
- Automated Machine Learning in Python
- Federated Learning: An Introduction