 A “Weird” Introduction to Deep Learning
A “Weird” Introduction to Deep Learning
 A “Weird” Introduction to Deep Learning
A “Weird” Introduction to Deep LearningThere are amazing introductions, courses and blog posts on Deep Learning. But this is a different kind of introduction.

There are amazing introductions, courses and blog posts on Deep Learning. I will name some of them in the resources sections, but this is a different kind of introduction.

But why weird? Maybe because it won’t follow the “normal” structure of a Deep Learning post, where you start with the math, then go into the papers, the implementation and then to applications.
It will be more close to the post I did before about “My journey into Deep Learning”, I think telling a story can be much more helpful than just throwing information and formulas everywhere. So let’s begin.
NOTE: There’s a companion webinar to this article. Find it here:
Why Am I making this introduction?

Sometimes is important to have a written backup of your thoughts. I tend to talk a lot, and be present in several presentations and conference, and this is my way of contributing with a little knowledge to everyone.
Deep Learning (DL)is such an important field for Data Science, AI, Technology and our lives right now, and it deserves all of the attention is getting. Please don’t say that deep learning is just adding a layer to a neural net, and that’s it, magic! Nope. I’m hopping that after reading this you have a different perspective of what DL is.
Deep Learning Timeline
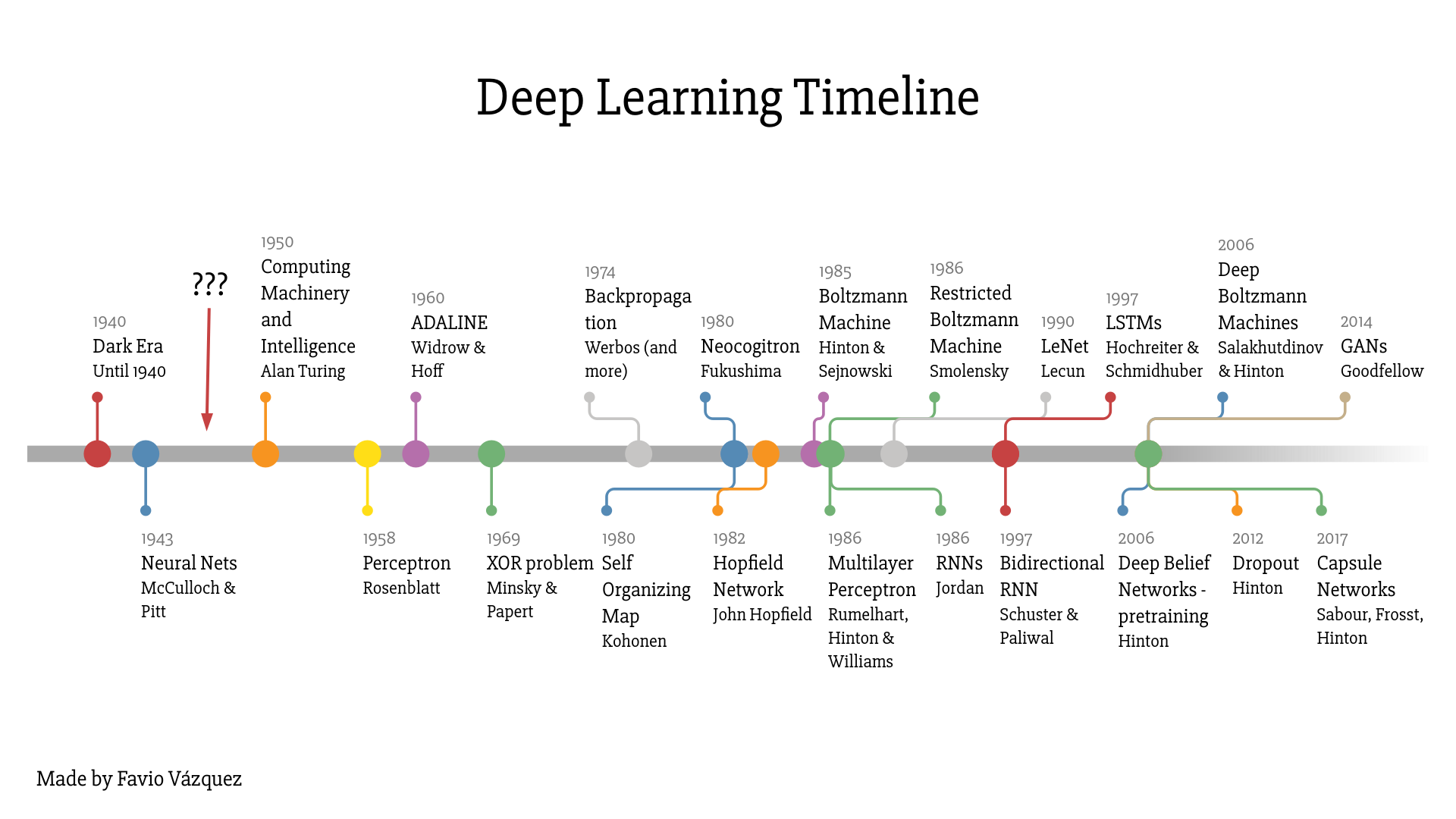
I just created this timeline based on several papers and other timelines with the purpose of everyone seeing that Deep Learning is much more than just Neural Networks. There has been really theoretical advances, software and hardware improvements that were necessary for us to get to this day. If you want it just ping me and I’ll send it to you. (Find my contact in the end of the article).
What is weird about Deep Learning?

Deep Learning has been around for quite a while now. So why it became so relevant so fast the last 5–7 years?
As I said before, until the late 2000s, we were still missing a reliable way to train very deep neural networks. Nowadays, with the development of several simple but important theoretical and algorithmic improvements, the advances in hardware (mostly GPUs, now TPUs), and the exponential generation and accumulation of data, DL came naturally to fit this missing spot to transform the way we do machine learning.
Deep Learning is an active field of research too, nothing is settle or closed, we are still searching for the best models, topology of the networks, best ways to optimize their hyperparameters and more. Is very hard, as any other active field on science, to keep up to date with the investigation, but it’s not impossible.
A side note on topology and machine learning (Deep Learning with Topological Signatures by Hofer et al.):
Methods from algebraic topology have only recently emerged in the machine learning community, most prominently under the term topological data analysis (TDA). Since TDA enables us to infer relevant topological and geometrical information from data, it can offer a novel and potentially beneficial perspective on various machine learning problems.
Luckily for us, there are lots of people helping understand and digest all of this information through courses like the Andrew Ng one, blog posts and much more.
This for me is weird, or uncommon because normally you have to wait for sometime (sometime years) to be able to digest difficult and advance information in papers or research journals. Of course, most areas of science are now really fast too to get from a paper to a blog post that tells you what yo need to know, but in my opinion DL has a different feel.
Breakthroughs of Deep Learning and Representation Learning

We are working with something that is very exciting, most people in the field are saying that the last ideas in the papers of deep learning (specifically new topologies and configurations for NN or algorithms to improve their usage) are the best ideas in Machine Learning in decades (remember that DL is inside of ML).
I’ve used the word learning a lot in this article so far. But what is learning?
In the context of Machine Learning, the word “learning” describes an automatic search process for better representations of the data you are analyzing and studying (please have this in mind, is not making a computer learn).
This is a very important word for this field, REP-RE-SEN-TA-TION. Don’t forget about it. What is a representation? It’s a way to look at data.
Let me give you an example, let’s say I tell you I want you to drive a line that separates the blue circles from the green triangles for this plot:
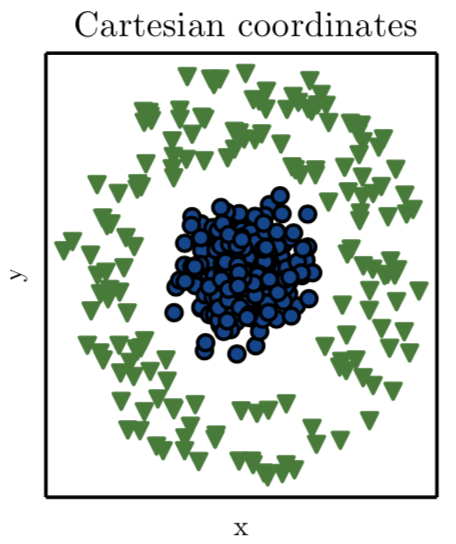
Ian Goodfellow et al. (Deep Learning, 2016)
This example is from the book of Deep Learning by Ian Goodfellow, et al. (2016).
So, if you want to use a line this is what the author says:
“… we represent some data using Cartesian coordinates, and the task is impossible.”
This is impossible if we remember the concept of a line:
A line is a straight one-dimensional figure having no thickness and extending infinitely in both directions. From Wolfram MathWorld.
So is the case lost? Actually no. If we find a way of representing this data in a different way, in a way we can draw a straight line to separate the types of data. This is somethinkg that math taught us hundreds of years ago. In this case what we need is a coordinate transformation, so we can plot or represent this data in a way we can draw this line. If we look the polar coordinate transformation, we have the solution:

Ian Goodfellow et al. (Deep Learning, 2016)
And that’s it now we can draw a line:
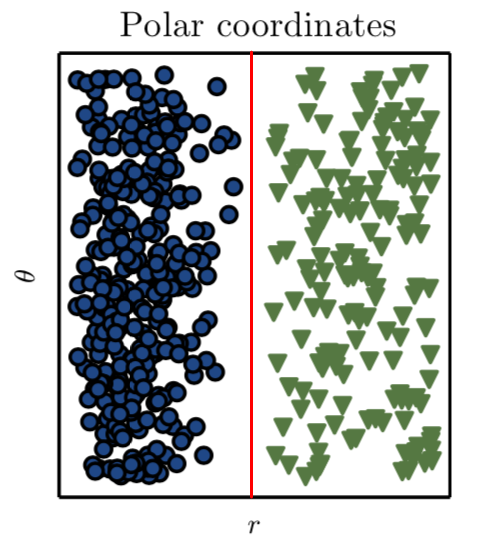
So, in this simple example we found and chose the transformation to get a better representation by hand. But if we create a system, a program that can search for different representations (in this case a coordinate change), and then find a way of calculating the percentage of categories being classified correctly with this new approach, in that moment we are doing Machine Learning.
This is something very important to have in mind, deep learning is representation learning using different kinds of neural networks and optimize the hyperparameters of the net to get (learn)the best representation for our data.
This wouldn’t be possible without the amazing breakthroughs that led us to the current state of Deep Learning. Here I name some of them:
1. Idea: Back Propagation.
Learning representations by back-propagating errors by David E. Rumelhart, Geoffrey E. Hinton & Ronald J. Williams.
A theoretical framework for Back-Propagation by Yann Lecun.
2. Idea: Better initialization of the parameters of the nets. Something to remember: The initialization strategy should be selected according to the activation function used (next).
Weight Initialization for Deep Networks - Practical aspects of Deep Learning | Coursera
This course will teach you the "magic" of getting deep learning to work well. Rather than the deep learning process…
How to train your Deep Neural Network
There are certain practices in Deep Learning that are highly recommended, in order to efficiently train Deep Neural…
CS231n Convolutional Neural Networks for Visual Recognition
Course materials and notes for Stanford class CS231n: Convolutional Neural Networks for Visual Recognition.
3. Idea: Better activation functions. This mean, better ways of approximating the functions faster leading to faster training process.
Understanding Activation Functions in Neural Networks
Recently, a colleague of mine asked me a few questions like “why do we have so many activation functions?”, “why is…
Activation Functions: Neural Networks
Sigmoid, tanh, Softmax, ReLU, Leaky ReLU EXPLAINED !!!
4. Idea: Dropout. Better ways of preventing overfitting and more.
Learning Less to Learn Better — Dropout in (Deep) Machine learning
In this post, I will primarily discuss the concept of dropout in neural networks, specifically deep nets, followed by…
Dropout: A Simple Way to Prevent Neural Networks from Overfitting, a great paper by Srivastava, Hinton and others.
5. Idea: Convolutional Neural Nets (CNNs).
Gradient based learning applied to document recognition by Lecun and others
ImageNet Classification with Deep Convolutional Neural Networks by Krizhevsky and others.
6. Idea: Residual Nets (ResNets).
[1512.03385v1] Deep Residual Learning for Image Recognition
Abstract: Deeper neural networks are more difficult to train. We present a residual learning framework to ease the…
[1608.02908] Residual Networks of Residual Networks: Multilevel Residual Networks
Abstract: A residual-networks family with hundreds or even thousands of layers dominates major image recognition tasks…
7. Idea: Region Based CNNs. Used for object detection and more.
[1311.2524v5] Rich feature hierarchies for accurate object detection and semantic segmentation
Abstract: Object detection performance, as measured on the canonical PASCAL VOC dataset, has plateaued in the last few…
[1703.06870] Mask R-CNN
Abstract: We present a conceptually simple, flexible, and general framework for object instance segmentation. Our…
facebookresearch/Detectron
Detectron - FAIR's research platform for object detection research, implementing popular algorithms like Mask R-CNN and…
8. Idea: Recurrent Neural Networks (RNNs) and LSTMs.
A Beginner's Guide to Recurrent Networks and LSTMs
Contents The purpose of this post is to give students of neural networks an intuition about the functioning of…
Understanding LSTM Networks -- colah's blog
These loops make recurrent neural networks seem kind of mysterious. However, if you think a bit more, it turns out that…
Recurrent Layers - Keras Documentation
input_length: Length of input sequences, to be specified when it is constant. This argument is required if you are…
BTW: It was shown by Liao and Poggio (2016) that ResNets == RNNs, arXiv:1604.03640v1.
9. Idea: Generative Adversarial Networks (GANs).
[1406.2661v1] Generative Adversarial Networks
Abstract: We propose a new framework for estimating generative models via an adversarial process, in which we…
nashory/gans-awesome-applications
gans-awesome-applications - Curated list of awesome GAN applications and demo
10. Idea: Capsule Networks.
What is a CapsNet or Capsule Network?
What is a Capsule Network? What is Capsule? Is CapsNet better than Convolutional Neural Network (CNN)? This article is…
Understanding Hinton’s Capsule Networks. Part I: Intuition.
Part of Understanding Hinton’s Capsule Networks Series:
gram-ai/capsule-networks
capsule-networks - A PyTorch implementation of the NIPS 2017 paper "Dynamic Routing Between Capsules".
And there are many others but I think those are really important theoretical and algorithmic breakthroughs that are changing the world, and that gave momentum for the DL revolution.