Data Science Interview Guide
Traditionally, Data Science would focus on mathematics, computer science and domain expertise. While I will briefly cover some computer science fundamentals, the bulk of this blog will mostly cover the mathematical basics one might either need to brush up on (or even take an entire course).
By Syed Sadat Nazrul, Analytic Scientist
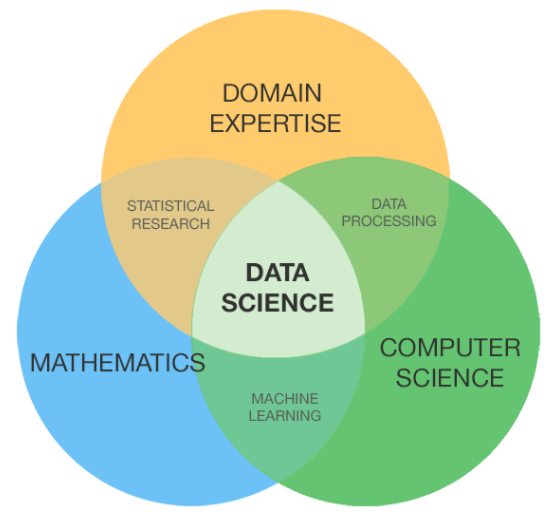
Data Science is quite a large and diverse field. As a result, it is really difficult to be a jack of all trades. Traditionally, Data Science would focus on mathematics, computer science and domain expertise. While I will briefly cover some computer science fundamentals, the bulk of this blog will mostly cover the mathematical basics one might either need to brush up on (or even take an entire course).
Software Tools
In most data science workplaces, software skills are a must. While I understand most of you reading this are more math heavy by nature, realize the bulk of data science (dare I say 80%+) is collecting, cleaning and processing data into a useful form.
Programming Language
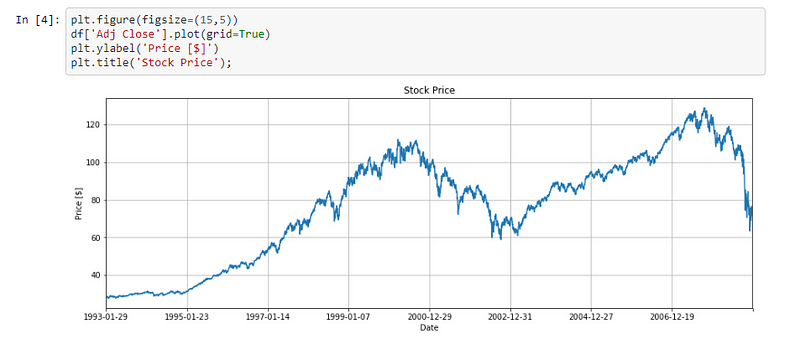
Python and R are the most popular ones in the Data Science space. However, I have also come across C/C++, Java and Scala. Although, I would personally recommend Python as it has all the math libraries as well as specialized libraries for querying various databases and maintaining interactive web UIs. Common Python libraries of choice are matplotlib, numpy, pandas and scikit-learn.
Database Management
It is common to see the majority of the data scientists being in one of two camps: Mathematicians and Database Architects. If you are the second one, the blog won’t help you much (YOU ARE ALREADY AWESOME!). If you are among the first group (like me), chances are you feel that writing a double nested SQL query is an utter nightmare. That being said, it is important to have some knowledge of query optimization (both for SQL and noSQL systems).
Map Reduce
Big Data technologies are a little hard to follow considering how the Apache project keeps on adding new tools all the time. However, I would recommend learning either Hadoop or Spark (though my personal recommendation is Spark). Both use similar Map Reduce algorithms (except Hadoop does it on disk while Spark does it in memory). Common Spark wrappers are Scala, Python and Java.

Additional Information
For more information on software development for data science applications, here are some of my other blogs:
- Python based Plotting with Matplotlib
- Python Package Management with Conda
- How to make your Software Development experience… painless….
- Software Development Design Principles
Data Collection And Cleaning
Now that we have covered the software needs, we will start making a smooth transition into the mathematics domain. Around this part of the process, you generally need to have some parsing background. This might either be collecting sensor data, parsing websites or carrying out surveys. After collecting the data, it needs to be transformed into a usable form (e.g. key-value store in JSON Lines files). Once the data is collected and put in a usable format, it is essential to perform some data quality checks. Some common quality checks are as described below:
NaN Handling
NaN or “Not A Number” is a common place holder for missing data. If the number of NaNs for the specific feature is small, it usually suffice fill in the NaNs with the average value (of the entire dataset or a window), or with 0s (for a sparse dataset).
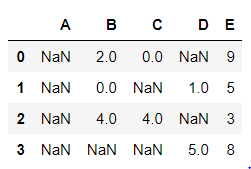
NaNs in a dataset usually indicates:
- the data doesn’t exist
- the data does exist but we don’t know what it is
Based on the specific use case, the appropriate measures should be taken.
Class Imbalance
Specifically for supervised learning models, it is important for classes (or targets) to be balanced. However, in cases of fraud, it is very common to heave heavy class imbalance (e.g. only 2% of the dataset is actual fraud).
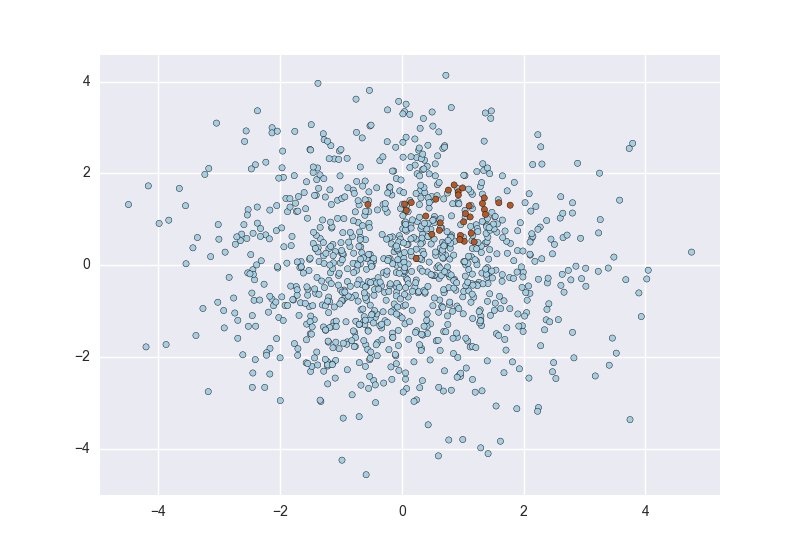
Such information is important to decide on the appropriate choices for feature engineering, modelling and model evaluation. For more information, check my blog on Fraud Detection Under Extreme Class Imbalance.
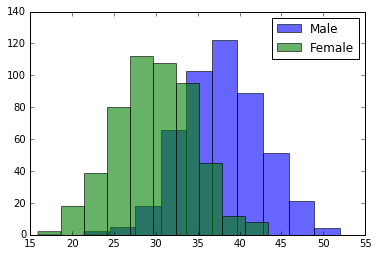
Univariate Analysis
Univariate analysis of single features (ignoring co-variate effects) is important when trying to look for outliers and unusual spikes in the variance. Common univariate analysis of choice is the histogram.
Bivariate Analysis
In bivariate analysis, each feature is compared to other features in the dataset. This would include correlation matrix, co-variance matrix or my personal favorite, the scatter matrix.
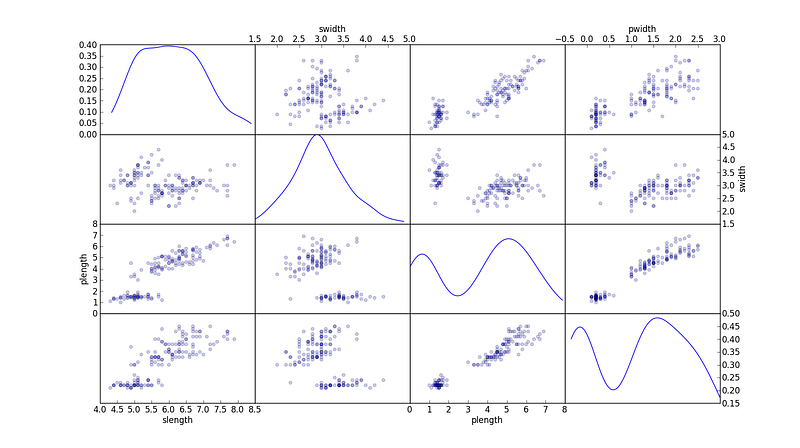
Scatter matrices allow us to find hidden patterns such as
- features that should be engineered together
- features that may need to be eliminated to avoid multicolinearity
Multicollinearity is actually an issue for multiple models like linear regression and hence needs to be taken care of accordingly.
Feature Engineering
Once the data is collected, cleaned and analyzed, it’s time to start creating features to be used in the model. In this section, we will explore some common feature engineering tactics.
Transformation
At times, the feature by itself may not provide useful information. For example, imagine using internet usage data. You will have YouTube users going as high as Giga Bytes while Facebook Messenger users use a couple of Mega Bytes. The simplest solution here would be to take the LOG of the values. Another issue is the use of categorical values. While categorical values are common in the data science world, realize computers can only comprehend numbers. In order for the categorical values to make mathematical sense, it needs to be transformed into something numeric. Typically for categorical values, it is common to perform a One Hot Encoding. In One Hot Encoding, a new feature is created for each categorical value to state if it is present in the given record. Example of One Hot Encoding is given below:
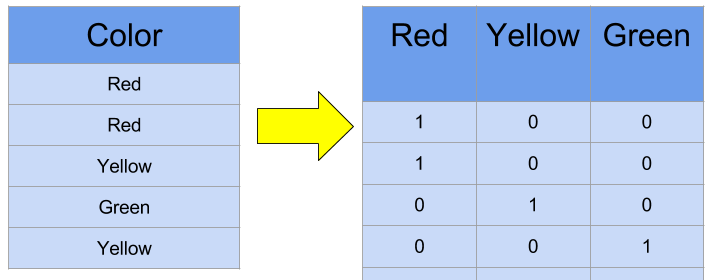
Combination
Certain features are redundant by themselves but are useful when grouped together. For example, imagine you had a predictive model for traffic density and you had a column for each type of car. Naturally, you don’t care about the type of car but the frequency of the total number of cars. Hence, a row wise summation of all the car types can be done to create a new “all_cars” variable.
Dimensionality Reduction
At times, having too many sparse dimensions will hamper the performance of the model. For such situations (as commonly done in image recognition), dimensionality reduction algorithms are used.
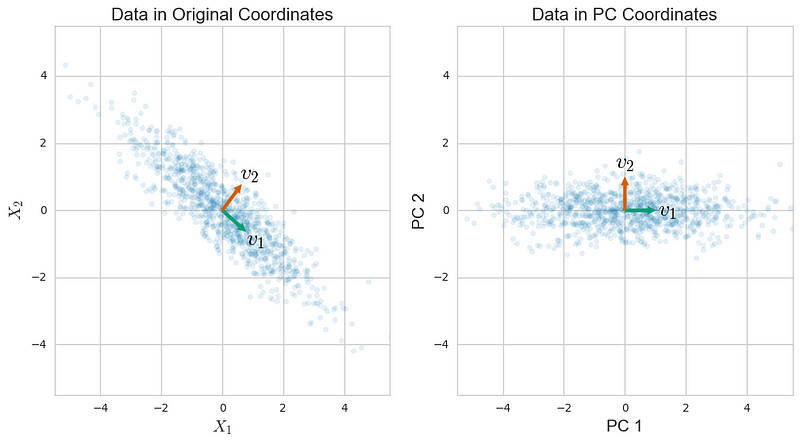
An algorithm commonly used for dimensionality reduction is Principal Components Analysis or PCA. Learn the mechanics of PCA as it is also one of those topics amongst COMMON INTERVIEW QUESTIONS!!! For more information, check our my blog on The DOs and DON’Ts of Principal Component Analysis.
Feature Selection
Now that you have engineered your list of features, it is now time to select the features that will help build the most optimum model for the use case. The common categories and their sub categories are explained in this section.
Filter Methods

Filter methods are generally used as a preprocessing step. The selection of features is independent of any machine learning algorithms. Instead, features are selected on the basis of their scores in various statistical tests for their correlation with the outcome variable. The correlation is a subjective term here. Common methods under this category are Pearson’s Correlation, Linear Discriminant Analysis, ANOVA and Chi-Square.
Wrapper Methods
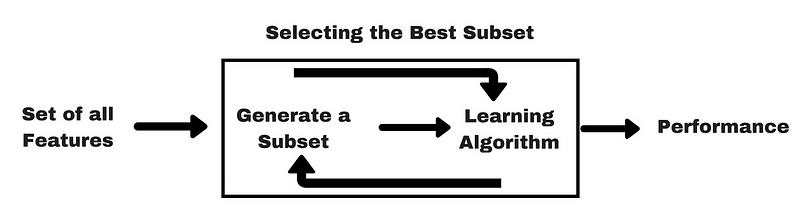
In wrapper methods, we try to use a subset of features and train a model using them. Based on the inferences that we draw from the previous model, we decide to add or remove features from your subset. The problem is essentially reduced to a search problem. These methods are usually computationally very expensive. Common methods under this category are Forward Selection, Backward Elimination and Recursive Feature Elimination.
Embedded Methods
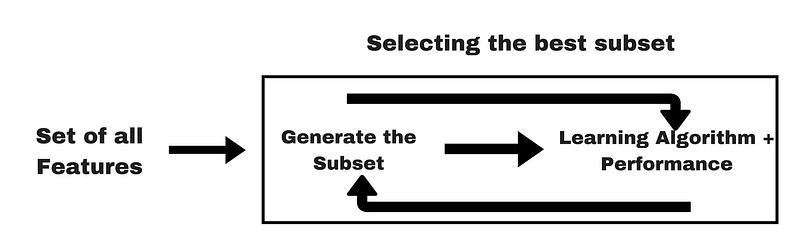
Embedded methods combine the qualities’ of filter and wrapper methods. It’s implemented by algorithms that have their own built-in feature selection methods. LASSO and RIDGE are common ones. The regularizations are given in the equations below as reference:
Lasso:
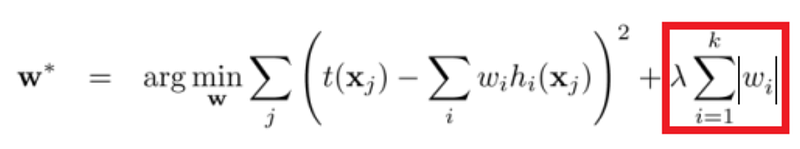
Ridge:
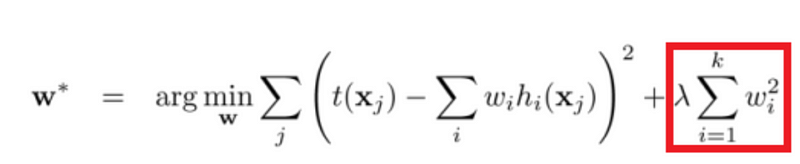
That being said, it is VERY IMPORTANT to understand the mechanics behind LASSO and RIDGE for interviews.