Implementing Deep Learning Methods and Feature Engineering for Text Data: The GloVe Model
The GloVe model stands for Global Vectors which is an unsupervised learning model which can be used to obtain dense word vectors similar to Word2Vec.
Editor's note: This post is only one part of a far more thorough and in-depth original, found here, which covers much more than what is included here.
The GloVe Model
The GloVe model stands for Global Vectors which is an unsupervised learning model which can be used to obtain dense word vectors similar to Word2Vec. However the technique is different and training is performed on an aggregated global word-word co-occurrence matrix, giving us a vector space with meaningful sub-structures. This method was invented in Stanford by Pennington et al. and I recommend you to read the original paper on GloVe, ‘GloVe: Global Vectors for Word Representation’ by Pennington et al. which is an excellent read to get some perspective on how this model works.
We won’t cover the implementation of the model from scratch in too much detail here but if you are interested in the actual code, you can check out the official GloVe page. We will keep things simple here and try to understand the basic concepts behind the GloVe model. We have talked about count based matrix factorization methods like LSA and predictive methods like Word2Vec. The paper claims that currently, both families suffer significant drawbacks. Methods like LSA efficiently leverage statistical information but they do relatively poorly on the word analogy task like how we found out semantically similar words. Methods like skip-gram may do better on the analogy task, but they poorly utilize the statistics of the corpus on a global level.
The basic methodology of the GloVe model is to first create a huge word-context co-occurence matrix consisting of (word, context) pairs such that each element in this matrix represents how often a word occurs with the context (which can be a sequence of words). The idea then is to apply matrix factorization to approximate this matrix as depicted in the following figure.
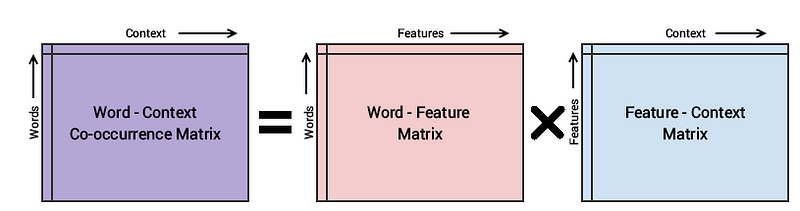
Conceptual model for the GloVe model’s implementation
Considering the Word-Context (WC) matrix, Word-Feature (WF) matrix and Feature-Context (FC) matrix, we try to factorize WC = WF x FC, such that we we aim to reconstruct WC from WF and FC by multiplying them. For this, we typically initialize WF and FC with some random weights and attempt to multiply them to get WC’ (an approximation of WC) and measure how close it is to WC. We do this multiple times using Stochastic Gradient Descent (SGD) to minimize the error. Finally, the Word-Feature matrix (WF) gives us the word embeddings for each word where F can be preset to a specific number of dimensions. A very important point to remember is that both Word2Vec and GloVe models are very similar in how they work. Both of them aim to build a vector space where the position of each word is influenced by its neighboring words based on their context and semantics. Word2Vec starts with local individual examples of word co-occurrence pairs and GloVe starts with global aggregated co-occurrence statistics across all words in the corpus.
Applying GloVe features for Machine Learning Tasks
Let’s try and leverage GloVe based embeddings for our document clustering task. The very popular spacy framework comes with capabilities to leverage GloVe embeddings based on different language models. You can also get pre-trained word vectors and load them up as needed using gensim or spacy. We will first install spacy and use the en_vectors_web_lg model which consists of 300-dimensional word vectors trained on Common Crawl with GloVe.
# Use the following command to install spaCy
> pip install -U spacy
OR
> conda install -c conda-forge spacy
# Download the following language model and store it in disk
https://github.com/explosion/spacy-models/releases/tag/en_vectors_web_lg-2.0.0
# Link the same to spacy
> python -m spacy link ./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg en_vecs
Linking successful
./spacymodels/en_vectors_web_lg-2.0.0/en_vectors_web_lg --> ./Anaconda3/lib/site-packages/spacy/data/en_vecs
You can now load the model via spacy.load('en_vecs')
There are automated ways to install models in spacy too, you can check their Models & Languages page for more information if needed. I had some issues with the same so I had to manually load them up. We will now load up our language model using spacy.
Total word vectors: 1070971
This validates that everything is working and in order. Let’s get the GloVe embeddings for each of our words now in our toy corpus.
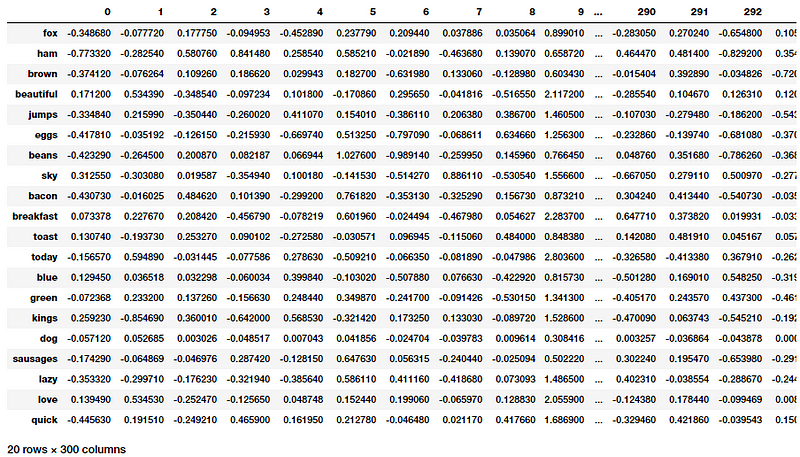
GloVe embeddings for words in our toy corpus
We can now use t-SNE to visualize these embeddings similar to what we did using our Word2Vec embeddings.
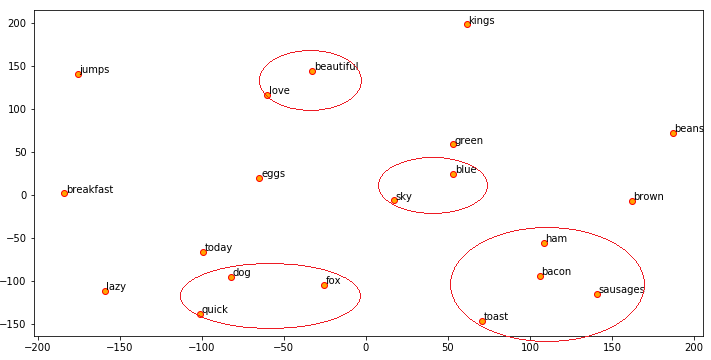
Visualizing GloVe word embeddings on our toy corpus
The beauty of spacy is that it will automatically provide you the averaged embeddings for words in each document without having to implement a function like we did in Word2Vec. We will leverage the same to get document features for our corpus and use k-means clustering to cluster our documents.

Clusters assigned based on our document features from GloVe
We see consistent clusters similar to what we obtained from our Word2Vec model which is good! The GloVe model claims to perform better than the Word2Vec model in many scenarios as illustrated in the following graph from the original paper by Pennington el al.
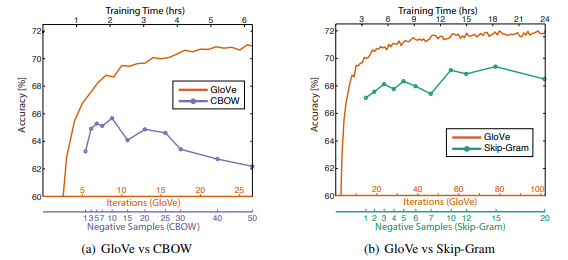
GloVe vs Word2Vec performance (Source: https://nlp.stanford.edu/pubs/glove.pdf by Pennington et al.)
The above experiments were done by training 300-dimensional vectors on the same 6B token corpus (Wikipedia 2014 + Gigaword 5) with the same 400,000 word vocabulary and a symmetric context window of size 10 in case anyone is interested in the details.
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related:
- Text Data Preprocessing: A Walkthrough in Python
- A General Approach to Preprocessing Text Data
- A Framework for Approaching Textual Data Science Tasks