Implementing Deep Learning Methods and Feature Engineering for Text Data: The Continuous Bag of Words (CBOW)
The CBOW model architecture tries to predict the current target word (the center word) based on the source context words (surrounding words).
Editor's note: This post is only one part of a far more thorough and in-depth original, found here, which covers much more than what is included here.
Let’s look at some of the popular word embedding models now and engineering features from our corpora!
The Word2Vec Model
This model was created by Google in 2013 and is a predictive deep learning based model to compute and generate high quality, distributed and continuous dense vector representations of words, which capture contextual and semantic similarity. Essentially these are unsupervised models which can take in massive textual corpora, create a vocabulary of possible words and generate dense word embeddings for each word in the vector space representing that vocabulary. Usually you can specify the size of the word embedding vectors and the total number of vectors are essentially the size of the vocabulary. This makes the dimensionality of this dense vector space much lower than the high-dimensional sparse vector space built using traditional Bag of Words models.
There are two different model architectures which can be leveraged by Word2Vec to create these word embedding representations. These include,
- The Continuous Bag of Words (CBOW) Model
- The Skip-gram Model
There were originally introduced by Mikolov et al. and I recommend interested readers to read up on the original papers around these models which include, ‘Distributed Representations of Words and Phrases and their Compositionality’ by Mikolov et al. and ‘Efficient Estimation of Word Representations in Vector Space’ by Mikolov et al. to gain some good in-depth perspective.
The Continuous Bag of Words (CBOW) Model
The CBOW model architecture tries to predict the current target word (the center word) based on the source context words (surrounding words). Considering a simple sentence, “the quick brown fox jumps over the lazy dog”, this can be pairs of (context_window, target_word) where if we consider a context window of size 2, we have examples like ([quick, fox], brown), ([the, brown], quick), ([the, dog], lazy) and so on. Thus the model tries to predict the target_word based on the context_window words.
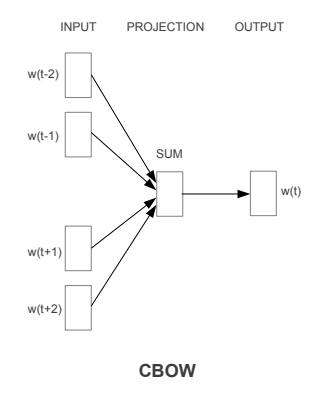
The CBOW model architecture (Source: https://arxiv.org/pdf/1301.3781.pdf Mikolov el al.)
While the Word2Vec family of models are unsupervised, what this means is that you can just give it a corpus without additional labels or information and it can construct dense word embeddings from the corpus. But you will still need to leverage a supervised, classification methodology once you have this corpus to get to these embeddings. But we will do that from within the corpus itself, without any auxiliary information. We can model this CBOW architecture now as a deep learning classification model such that we take in the context words as our input, X and try to predict the target word, Y. In fact building this architecture is simpler than the skip-gram model where we try to predict a whole bunch of context words from a source target word.
Implementing the Continuous Bag of Words (CBOW) Model
While it’s excellent to use robust frameworks which have the Word2Vec model like gensim, let’s try and implement this from scratch to gain some perspective on how things really work behind the scenes. We will leverage our Bible corpus contained in the norm_bible variable for training our model. The implementation will focus on four parts
- Build the corpus vocabulary
- Build a CBOW (context, target) generator
- Build the CBOW model architecture
- Train the Model
- Get Word Embeddings
Without further delay, let’s get started!
Build the corpus vocabulary
To start off, we will first build our corpus vocabulary where we extract out each unique word from our vocabulary and map a unique numeric identifier to it.
Output
------
Vocabulary Size: 12425
Vocabulary Sample: [('perceived', 1460), ('flagon', 7287), ('gardener', 11641), ('named', 973), ('remain', 732), ('sticketh', 10622), ('abstinence', 11848), ('rufus', 8190), ('adversary', 2018), ('jehoiachin', 3189)]
Thus you can see that we have created a vocabulary of unique words in our corpus and also ways to map a word to its unique identifier and vice versa. The PAD term is typically used to pad context words to a fixed length if needed.
Build a CBOW (context, target) generator
We need pairs which consist of a target centre word and surround context words. In our implementation, a target word is of length 1 and surrounding context is of length 2 x window_size where we take window_size words before and after the target word in our corpus. This will become clearer with the following example.
Context (X): ['old','testament','james','bible'] -> Target (Y): king Context (X): ['first','book','called','genesis'] -> Target(Y): moses Context(X):['beginning','god','heaven','earth'] -> Target(Y):created Context (X):['earth','without','void','darkness'] -> Target(Y): form Context (X): ['without','form','darkness','upon'] -> Target(Y): void Context (X): ['form', 'void', 'upon', 'face'] -> Target(Y): darkness Context (X): ['void', 'darkness', 'face', 'deep'] -> Target(Y): upon Context (X): ['spirit', 'god', 'upon', 'face'] -> Target (Y): moved Context (X): ['god', 'moved', 'face', 'waters'] -> Target (Y): upon Context (X): ['god', 'said', 'light', 'light'] -> Target (Y): let Context (X): ['god', 'saw', 'good', 'god'] -> Target (Y): light
The preceding output should give you some more perspective of how X forms our context words and we are trying to predict the target center word Y based on this context. For example, if the original text was ‘in the beginning god created heaven and earth’ which after pre-processing and removal of stopwords became ‘beginning god created heaven earth’ and for us, what we are trying to achieve is that. Given [beginning, god, heaven, earth] as the context, what the target center word is, which is ‘created’ in this case.
Build the CBOW model architecture
We now leverage keras on top of tensorflow to build our deep learning architecture for the CBOW model. For this our inputs will be our context words which are passed to an embedding layer (initialized with random weights). The word embeddings are propagated to a lambda layer where we average out the word embeddings (hence called CBOW because we don’t really consider the order or sequence in the context words when averaged)and then we pass this averaged context embedding to a dense softmax layer which predicts our target word. We match this with the actual target word, compute the loss by leveraging the categorical_crossentropy loss and perform backpropagation with each epoch to update the embedding layer in the process. Following code shows us our model architecture.
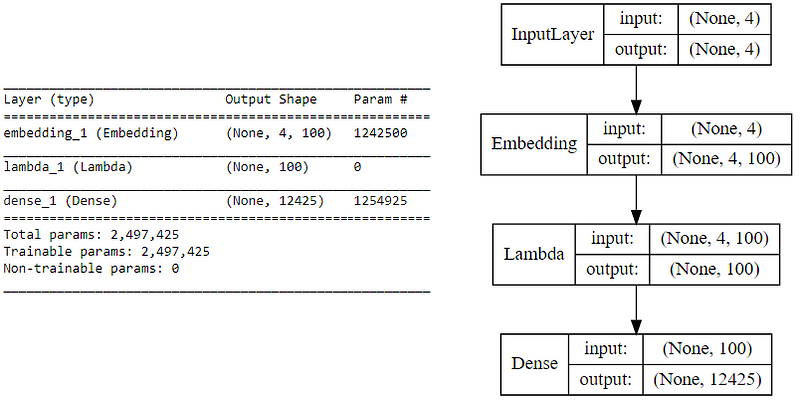
CBOW model summary and architecture
In case you still have difficulty in visualizing the above deep learning model, I would recommend you to read through the papers I mentioned earlier. I will try to summarize the core concepts of this model in simple terms. We have input context words of dimensions (2 x window_size), we will pass them to an embedding layer of size (vocab_size x embed_size) which will give us dense word embeddings for each of these context words (1 x embed_size for each word). Next up we use a lambda layer to average out these embeddings and get an average dense embedding (1 x embed_size) which is sent to the dense softmax layer which outputs the most likely target word. We compare this with the actual target word, compute the loss, backpropagate the errors to adjust the weights (in the embedding layer) and repeat this process for all (context, target) pairs for multiple epochs. The following figure tries to explain the same.
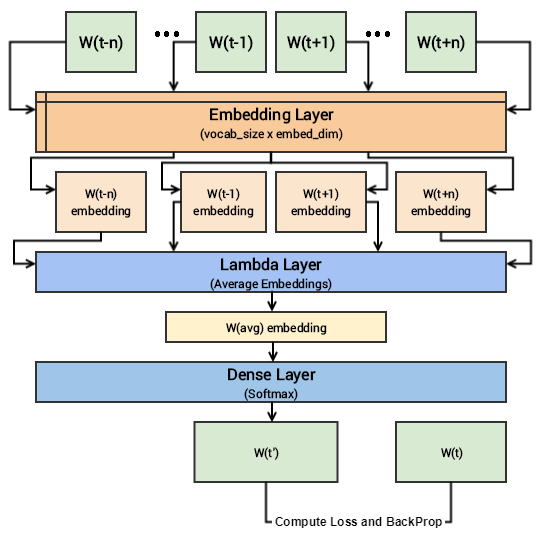
Visual depiction of the CBOW deep learning model
We are now ready to train this model on our corpus using our data generator to feed in (context, target_word) pairs.
Train the Model
Running the model on our complete corpus takes a fair bit of time, so I just ran it for 5 epochs. You can leverage the following code and increase it for more epochs if necessary.
Epoch: 1 Loss: 4257900.60084 Epoch: 2 Loss: 4256209.59646 Epoch: 3 Loss: 4247990.90456 Epoch: 4 Loss: 4225663.18927 Epoch: 5 Loss: 4104501.48929
Note: Running this model is computationally expensive and works better if trained using a GPU. I trained this on an AWS
p2.xinstance with a Tesla K80 GPU and it took me close to 1.5 hours for just 5 epochs!
Once this model is trained, similar words should have similar weights based off the embedding layer and we can test out the same.
Get Word Embeddings
To get word embeddings for our entire vocabulary, we can extract out the same from our embedding layer by leveraging the following code. We don’t take the embedding at position 0 since it belongs to the padding (PAD) term which is not really a word of interest.
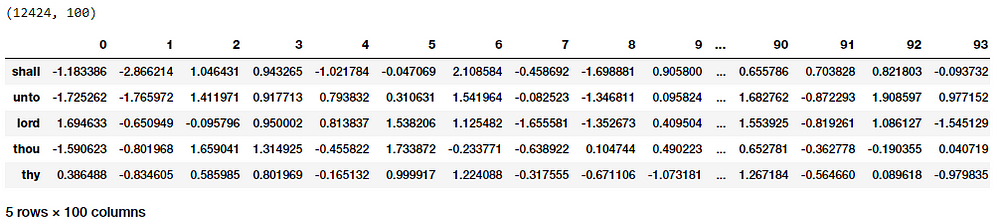
Word Embeddings for our vocabulary based on the CBOW model
Thus you can clearly see that each word has a dense embedding of size (1x100) as depicted in the preceding output. Let’s try and find out some contextually similar words for specific words of interest based on these embeddings. For this, we build out a pairwise distance matrix amongst all the words in our vocabulary based on the dense embedding vectors and then find out the n-nearest neighbors of each word of interest based on the shortest (euclidean) distance.
(12424, 12424)
{'egypt': ['destroy', 'none', 'whole', 'jacob', 'sea'],
'famine': ['wickedness', 'sore', 'countries', 'cease', 'portion'],
'god': ['therefore', 'heard', 'may', 'behold', 'heaven'],
'gospel': ['church', 'fowls', 'churches', 'preached', 'doctrine'],
'jesus': ['law', 'heard', 'world', 'many', 'dead'],
'john': ['dream', 'bones', 'held', 'present', 'alive'],
'moses': ['pharaoh', 'gate', 'jews', 'departed', 'lifted'],
'noah': ['abram', 'plagues', 'hananiah', 'korah', 'sarah']}
You can clearly see that some of these make sense contextually (god, heaven), (gospel, church) and so on and some may not. Training for more epochs usually ends up giving better results. We will now explore the skip-gram architecture which often gives better results as compared to CBOW.
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related:
- Text Data Preprocessing: A Walkthrough in Python
- A General Approach to Preprocessing Text Data
- A Framework for Approaching Textual Data Science Tasks