Understanding What is Behind Sentiment Analysis – Part 1
Build your first sentiment classifier in 3 steps.
By Enrique Fueyo, CTO & Co-founder @ Lang.ai

Photo by Jerry Kiesewetter on Unsplash
Introduction
Sentiment analysis, sometimes called opinion mining or polarity detection, refers to the set of AI algorithms and techniques used to extract the polarity of a given document: whether the document is positive, negative or neutral.
Typically this polarity is represented as either a set of classes (ex. {Positive, Neutral, Negative}) or a real number that represents the probability that the document is positive or negative. Some other implementations use more classes or grades between Positive, Negative and Neutral (0–5 stars, 0–10 grade).
Historically, it is considered that sentiment analysis started in early 2000’s with the articles published by Bo Pang and Lillian Lee and by Peter Turney.
Machine Learning
Machine learning represents a branch of AI that covers the algorithms that are able to grasp some knowledge from data (training) and build a model or make data-driven predictions.
This algorithms can also be classified as:
- Supervised learning is used to denote the algorithms that, at training time, are presented with the input sample and its expected output;
- Unsupervised learning algorithms have access to the input samples but not to the desired outcomes.
- In between, we can also find semi-supervised algorithms where the training set is composed of both: raw input samples and pairs of input and output samples.
In this article we will focus on supervised sentiment analysis, where we have a training corpus of multiple sentences labelled as either positive or negative. For simplicity we will omit the neutral label so we just have to solve a binary classification problem.
The “Bag of Words” Model
This model is a simplification that removes all the information regarding the order of the words and only pays attention to what words are included in the document. Optionally their frequency is also taken into account: the number of times each word occurs in the document.
As any simplification, it reduces the complexity of the task and makes it more tractable at the expense of losing some information that might be useful so, depending on the task you are going to perform, it may be helpful or not.
The information we give up here is grammar or syntactic information as we have lost the order of the words (they all are mixed inside the bag!). However, for document classification tasks like sentiment analysis or topic extraction, where the outcome is typically influenced by a few key words that hold the semantic information, this shouldn’t be a huge problem specially in short and informal texts.
As an example, for the bag of words model there won’t be any difference between the sentence “Alice loves Bob” and “Bob loves Alice”. ????
Our First Sentiment Analysis Classifier
Step 1: Analyzing our corpus
As mentioned, we need a corpus to train the classifier with. Typically, your corpus will consist on a set of thousands, tens of thousands or more sentences labelled in one of the classes (Positive-Negative or Positive-Neutral-Negative, 0–5 stars…). Our corpus will be much smaller, and to avoid any bias we will use the same number of sentences for each class (three sentences)
Analysis for our corpus:
- You like that movie — POSITIVE
- We enjoyed the meal — POSITIVE
- I like apples — POSITIVE
- I hate wars — NEGATIVE
- You hate apples — NEGATIVE
- That movie was terrible — NEGATIVE
Step 2: Creating our vocabulary
Then, we have to create our vocabulary (the words the classifier has been trained on) from all the words that appeared in the corpus sentences and count how many sentences, in each class, contain each word.
Vocabulary: {you, like, that, movie, we, enjoyed, the, meal, I, apples, hate, wars, was, terrible}
This table below is based on our limited corpus but the idea is that, as long as the corpus is large enough, neutral words will tend to appear evenly in both positive and negative sentences (for instance movie) and it should prevent words like was to be so negative (0/3 vs 1/3).
+--------+---------+----------+ | | Positive| Negative | +--------+---------+----------+ | I | 1 | 1 | | enjoyed| 1 | 0 | | like | 2 | 0 | | hate | 0 | 1 | | was | 0 | 1 | | that | 1 | 1 | | movie | 1 | 1 | | ... | . | . | +--------+---------+----------+
Positive words will tend to occur more in positive sentences as well as negative words with negative sentences.
Step 3: Predicting the sentiment
Now, for every new text, we can try to predict its sentiment given the words it contains. To accomplish it, we will calculate a positive score and a negative score by multiplying the positive and negative scores for each word from the table above; then we just have to check which score is higher.
For numerical stability we will add a small (i.e. smoothing) constant number k to all the values in the table above to avoid multiplying by zero if a word hasn’t occur in any specific class. We will use k=0.01.
Let’s analyze the following example:
“I enjoyed that movie”
Positive = I(1.01) * enjoyed(1.01) * that(1.01) * movie(1.01) = 1.04
Negative = I(1.01) * enjoyed(0.01) * that(1.01) * movie(1.01) = 0.01
Conclusion
Based on the previous result we can conclude that the sentence “I enjoyed that movie” is positive since the Positive value (1.04) is bigger than the Negative one (0.01).
The Naïve-Bayes Classifier
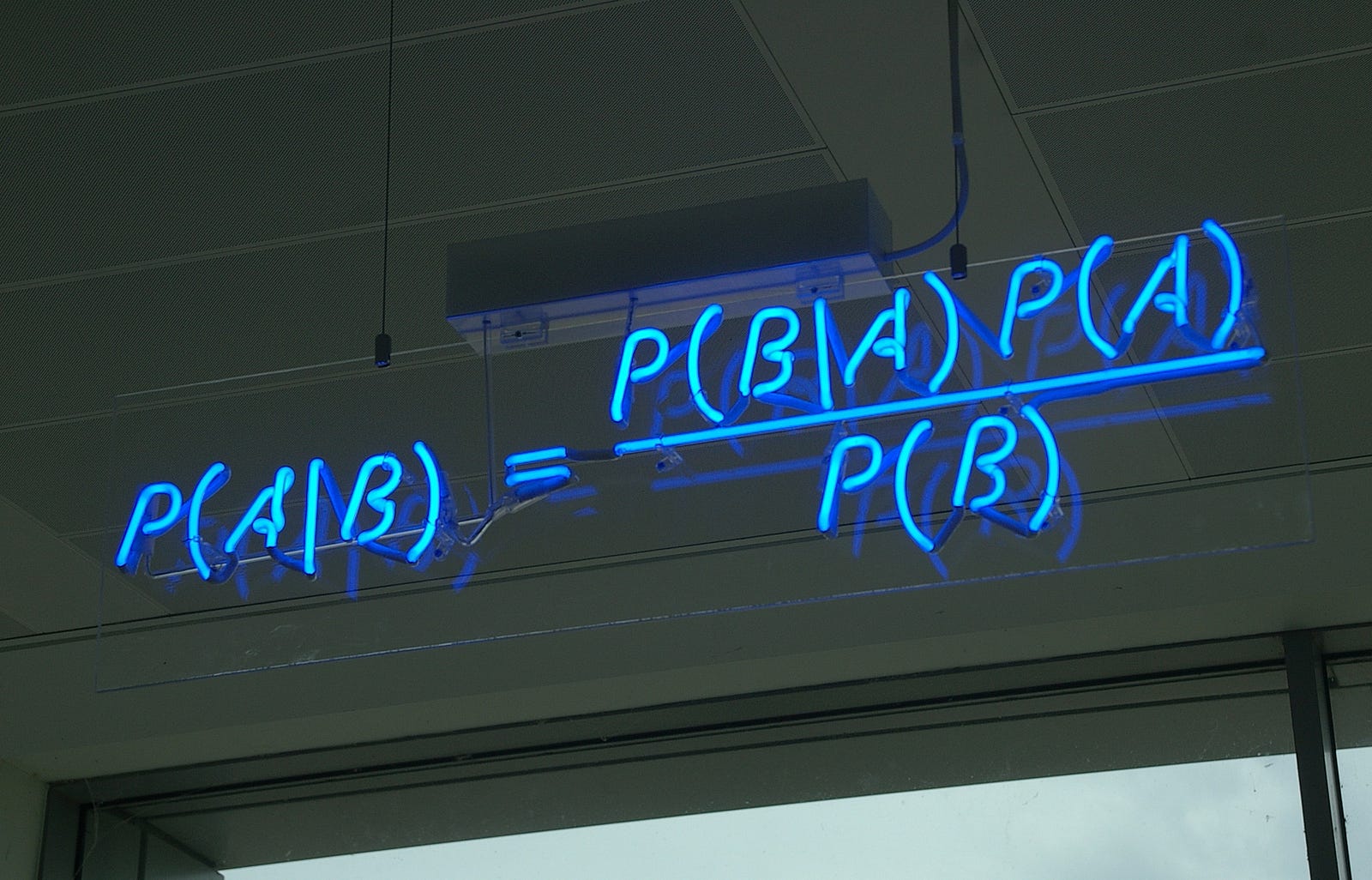
Simple statement of Bayes’ theorem — Photo by Mattbuck
The independence between words assumption is a huge assumption in language since the occurrence of a word is highly affected by the surrounding words in the sentence, i.e. they are not independent as we have just supposed. Even though this simplification doesn’t hold true, this model still works for multiple tasks (especially for short and simple texts).
Wrap up
Apart from the baseline we have described here, there are some modifications we can do to achieve better results and overcome some of the problems this simple model has. We will discuss a few of them in the next article.
Bio: Enrique Fueyo is CTO and co-founder at Lang.ai, where they try to unlock the value from unstructured text data thanks to Unsupervised AI. Their work is mainly focused on uncovering intents or semantic clusters from unlabelled data without external ontologies, which makes it language-agnostic, that can be later transformed into a real time API to classify new documents.
Original. Reposted with permission.
Related: