Emotion and Sentiment Analysis: A Practitioner’s Guide to NLP
Sentiment analysis is widely used, especially as a part of social media analysis for any domain, be it a business, a recent movie, or a product launch, to understand its reception by the people and what they think of it based on their opinions or, you guessed it, sentiment!
What is Sentiment Analysis?
Sentiment analysis is perhaps one of the most popular applications of NLP, with a vast number of tutorials, courses, and applications that focus on analyzing sentiments of diverse datasets ranging from corporate surveys to movie reviews.
The key aspect of sentiment analysis is to analyze a body of text for understanding the opinion expressed by it. Typically, we quantify this sentiment with a positive or negative value, called polarity. The overall sentiment is often inferred as positive, neutral or negative from the sign of the polarity score.
How is Sentiment Analysis Used?
Usually, sentiment analysis works best on text that has a subjective context than on text with only an objective context. Objective text usually depicts some normal statements or facts without expressing any emotion, feelings, or mood.
Subjective text contains text that is usually expressed by a human having typical moods, emotions, and feelings. Sentiment analysis is widely used, especially as a part of social media analysis for any domain, be it a business, a recent movie, or a product launch, to understand its reception by the people and what they think of it based on their opinions or, you guessed it, sentiment!

How to Perform Sentiment Analysis
Typically, sentiment analysis for text data can be computed on several levels, including on an individual sentence level, paragraph level, or the entire document as a whole. Often, sentiment is computed on the document as a whole or some aggregations are done after computing the sentiment for individual sentences. There are two major approaches to sentiment analysis.
- Supervised machine learning or deep learning approaches
- Unsupervised lexicon-based approaches
For the first approach we typically need pre-labeled data. Hence, we will be focusing on the second approach. For a comprehensive coverage of sentiment analysis, refer to Chapter 7: Analyzing Movie Reviews Sentiment, Practical Machine Learning with Python, Springer\Apress, 2018.
In this scenario, we do not have the convenience of a well-labeled training dataset. Hence, we will need to use unsupervised techniques for predicting the sentiment by using knowledgebases, ontologies, databases, and lexicons that have detailed information, specially curated and prepared just for sentiment analysis.
A lexicon is a dictionary, vocabulary, or a book of words. In our case, lexicons are special dictionaries or vocabularies that have been created for analyzing sentiments. Most of these lexicons have a list of positive and negative polar words with some score associated with them, and using various techniques like the position of words, surrounding words, context, parts of speech, phrases, and so on, scores are assigned to the text documents for which we want to compute the sentiment. After aggregating these scores, we get the final sentiment.

Various popular lexicons are used for sentiment analysis, including the following.
- AFINN lexicon
- Bing Liu’s lexicon
- MPQA subjectivity lexicon
- SentiWordNet
- VADER lexicon
- TextBlob lexicon
This is not an exhaustive list of lexicons that can be leveraged for sentiment analysis, and there are several other lexicons which can be easily obtained from the Internet. Feel free to check out each of these links and explore them. We will be covering two techniques in this section.
Sentiment Analysis with AFINN Lexicon
The AFINN lexicon is perhaps one of the simplest and most popular lexicons that can be used extensively for sentiment analysis. Developed and curated by Finn Årup Nielsen, you can find more details on this lexicon in the paper, “A new ANEW: evaluation of a word list for sentiment analysis in microblogs”, proceedings of the ESWC 2011 Workshop.
The current version of the lexicon is AFINN-en-165. txt and it contains over 3,300+ words with a polarity score associated with each word. You can find this lexicon at the author’s official GitHub repository along with previous versions of it, including AFINN-111.The author has also created a nice wrapper library on top of this in Python called afinn, which we will be using for our analysis.
The following code computes sentiment for all our news articles and shows summary statistics of general sentiment per news category.
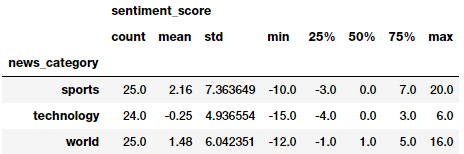
We can get a good idea of general sentiment statistics across different news categories. Looks like the average sentiment is very positive in sports and reasonably negative in technology! Let’s look at some visualizations now.
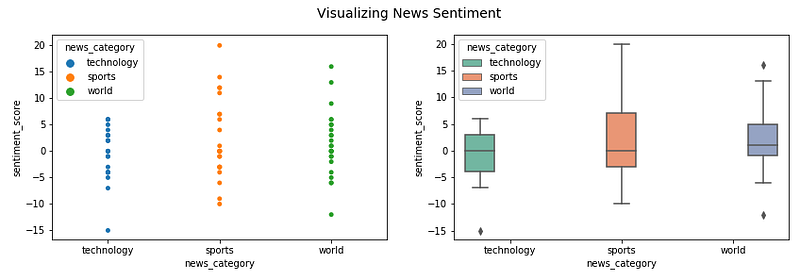
Visualizing news sentiment polarity
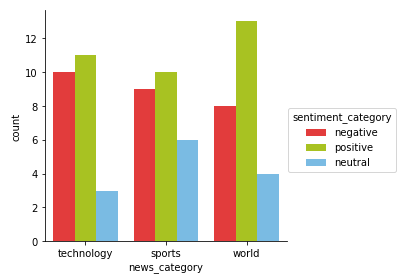
Visualizing sentiment categories per news category

Looks like the most negative article is all about a recent smartphone scam in India and the most positive article is about a contest to get married in a self-driving shuttle. Interesting! Let’s do a similar analysis for world news.

Interestingly Trump features in both the most positive and the most negative world news articles. Do read the articles to get some more perspective into why the model selected one of them as the most negative and the other one as the most positive (no surprises here!).
Sentiment Analysis with TextBlob
TextBlob is another excellent open-source library for performing NLP tasks with ease, including sentiment analysis. It also an a sentiment lexicon (in the form of an XML file) which it leverages to give both polarity and subjectivity scores.
Typically, the scores have a normalized scale as compare to Afinn. The polarity score is a float within the range [-1.0, 1.0]. The subjectivity is a float within the range [0.0, 1.0] where 0.0 is very objective and 1.0 is very subjective. Let’s use this now to get the sentiment polarity and labels for each news article and aggregate the summary statistics per news category.
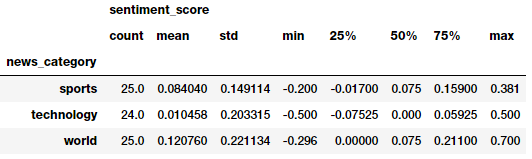
Looks like the average sentiment is the most positive in world and least positive in technology! However, these metrics might be indicating that the model is predicting more articles as positive. Let’s look at the sentiment frequency distribution per news category.
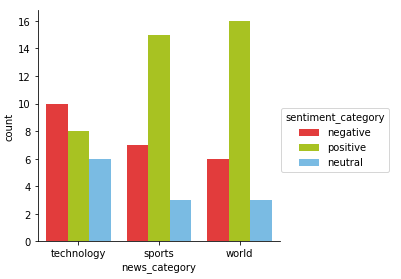
Visualizing sentiment categories per news category

Well, looks like the most negative world news article here is even more depressing than what we saw the last time! The most positive article is still the same as what we had obtained in our last model.
Finally, we can even evaluate and compare between these two models as to how many predictions are matching and how many are not (by leveraging a confusion matrix which is often used in classification). We leverage our nifty model_evaluation_utils module for this.
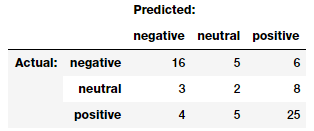
Comparing sentiment predictions across models
TextBlob. Looks like our previous assumption was correct. TextBlob definitely predicts several neutral and negative articles as positive. Overall most of the sentiment predictions seem to match, which is good!
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related: