What’s the Difference Between Data Integration and Data Engineering?
Why is this distinction important? Because it’s critical to understanding how leading-organizations are investing in new data engineering skills that exploit advanced analytics to create new sources of business and operational value.
Sometimes I write a blog because I’ve learned something new that I’m eager to share. And sometimes I write a blog because we’ve just done something enlightening in one of my classes or client exercises. But sometimes I write a blog because I don’t know anything about a topic, and writing a blog is the best way to force myself to learn what I don’t know. The latter is the driving factor behind this blog: What’s the Difference between data integration and data engineering?
Why is this distinction important? Because it’s critical to understanding how leading-organizations are investing in new data engineering skills that exploit advanced analytics to create new sources of business and operational value (see Figure 1).
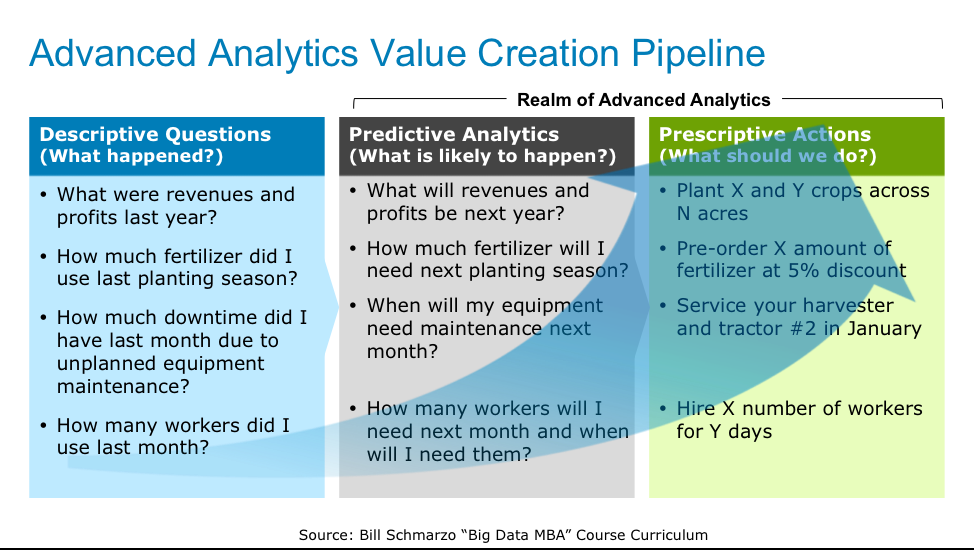
Figure 1: Advanced Analytics Value Creation Pipeline
To understand the business and operational potential of the “Advanced Analytics Value Creation Pipeline”, we need to understand the roles, responsibilities and expectations of the data integration, data engineering and data science capabilities. So, here we go!
Data Integration, Data Engineering, Data Science…Oh My!
Let’s start with a visual on the different roles and responsibilities of data integration, data engineering and data science in the advanced analytics value creation pipeline (see Figure 2).
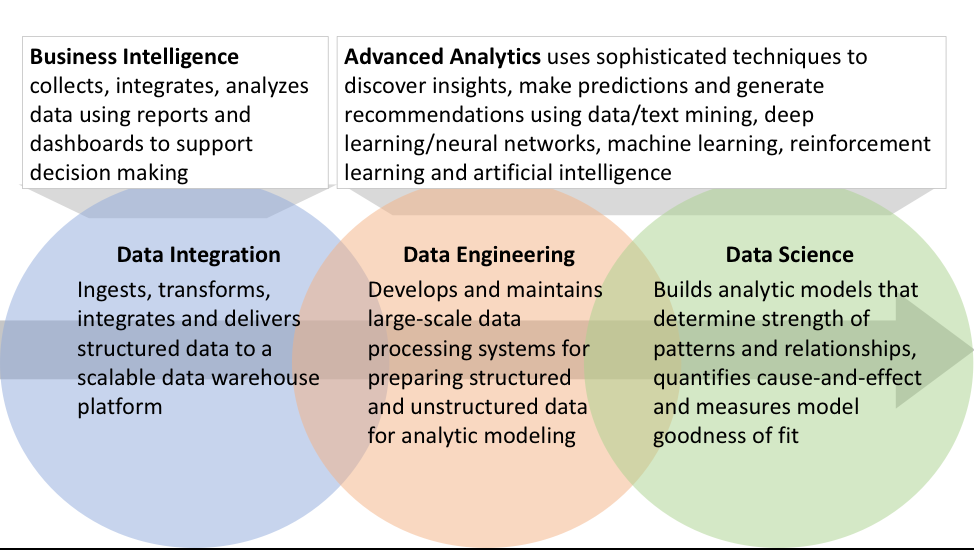
Figure 2: Overlapping Roles of Data Integration, Data Engineering and Data Science
Figure 2... busy, hard to read, uses too much lingo…perfect because at this point that’s how my head feels about these three critically important but distinct roles in the analytics value creation process. Let’s drill into more details to identify the key responsibilities for these different but critically important roles.
Data Integration ingests, transforms and integrates structured data and delivers data to a scalable data warehouse platform using traditional ETL (Extract, Transform, Load) tools and methodologies to collect of data from various sources into a single data warehouse:
- Ingests, transforms and blends/integrates structured and unstructured data and delivers the data to a data warehouse.
- Includes both technical processes and business logic to transform data from disparate sources into cohesive meaningful data with quality, governance and compliance considerations.
- Combination of technical and business processes used to combine data from disparate sources into meaningful and valuable information. A complete data integration solution delivers trusted data from a variety of sources.
- Traditional domain of ETL (Extract, Transform and Load) that transforms and cleans the data as it is being extracted from various data sources and loaded into one data store (data warehouse). For example, converting a single variable of “address” into “street address”, “city”, “state” and “zip code” fields.
Data Engineering develops, constructs and maintains large-scale data processing systems that collects data from variety of structured and unstructured data sources, stores data in a scale-out data lake and prepares the data using ELT (Extract, Load, Transform) techniques in preparation for the data science data exploration and analytic modeling:
- Collects the data from a variety of traditional and non-traditional sources, stores it in a data repository, cleanses and integrates the data (data prep) for analysis.
- Designers, builders and managers of the information and big data infrastructure. They co-develop the architecture that helps analyze and process data that the organization required and further optimize those systems to perform smoothly.
- Evaluates, compares and improves the different approaches including design patterns innovation, data lifecycle design, data ontology alignment, annotated datasets, and elastic search approaches.
- Prepares the data for the data scientist exploration and discovery process. For example, we have data containing 30 attributes where two attributes are used to compute another attribute (for example, an index), and that computed feature is used for further analysis. In this way, the data could be changed according to the requirement of the applied model.
- “Wrangles” the data, sometimes called data munging or data schmarzing (just checking to see if you’re reading) which transforms, maps and “munges" the raw data using algorithms (e.g. sorting, parsing) into predefined data structures, and depositing the results into a data lake for the downstream analytics.
Much of the data engineering work tends to be domain specific (requires an understanding of the unique meaning of the data given the business or operational problem being solved) and involves the business stakeholders
Data Science embraces the scientific method to massage and organize big data for analytic exploration and model development in order to build analytic models that determines strength of patterns and relationships, quantifies cause-and-effect and measures model goodness of fit:
- Data exploration and data discovery to identify and quantify characteristic of the data. This is an interactive process to determine which variables and metrics to test in the interactive analytic model development process.
- Data enrichment is the process of creating new higher-order variables that enhance the content and context of the raw data given the problem being addressed. Data enrichment techniques include log transformations, RFM (recency, frequency, monetary) calculations, indices, share, attributions and scores.
- Data visualization uses tools and techniques to identify patterns, trends, outliers and correlations that might be useful in the analytic modeling process; to identify variables and metrics that might be better predictors of business and operational performance.
- Feature engineering, the process creating new input features for machine learning, is one of the most effective ways to improve predictive models.
- Rapid fail fast/learn faster analytic model development, testing and refinement that determines strength of patterns and relationships, quantifies cause-and-effect and measures model goodness of fit (see Figure 3).
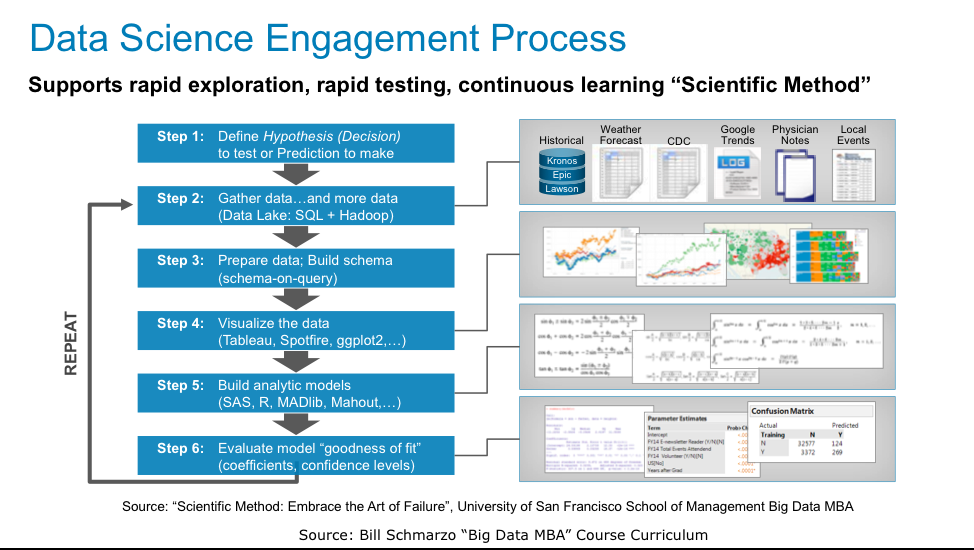
Figure 3: Data Science Data Exploration and Analytic Model Development Process
Note: Model deployment is not the responsibility ofData Science. The data engineering and data science team must collaborate with the DevOps team to operationalize the data feeds and analytic models into the operational systems (e.g., Point-of-Sales, Procurement, Finance, Manufacturing, Inventory Management, Sales, Marketing, Call Center).
Role of the Business Stakeholders
To be successful, data engineering and data science require close collaboration with the business analysts and stakeholders who are users of the resulting analytics. The closer the function comes to deriving a business outcome, the closer the business stakeholder collaboration to driving the business outcome (see Figure 4).
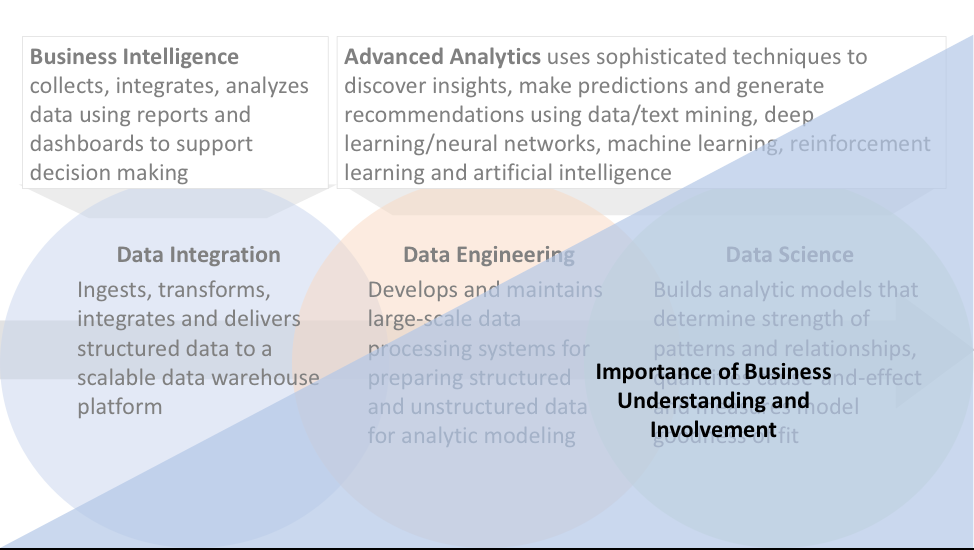
Figure 4: Importance of Business Problem Understanding
A technique for ensuring business stakeholder contribution is to get the business users to “Think Like A Data Scientist.” That is, the more that the business and operational stakeholders understand the potential of data science to help them make better decisions, the better the ultimate data engineering and data science results. See the blog “Refined Thinking like a Data Scientist Series” for more details on how to bring the business and operational stakeholders into the data engineering and data science process.
Data Engineering Summary
Okay, tell me what I got right and what I got wrong. I’m not afraid to learn because I think this data engineering role will continue to grow in business and operational importance.
And while the Harvard Business Review may have declared “Data Scientist: The Sexiest Job of the 21st Century,” it is the data engineering team that allows them to shine. Without the data engineering support, the sexy data scientist job will quickly devolve into something about as sexy as a street sweeper.
Sources:
- Data Preparation, Preprocessing and Wrangling in Deep Learning
https://www.xenonstack.com/blog/data-science/preparation-wrangling-machine-learning-deep/ - Artificial Intelligence is not “Fake” Intelligence
https://www.linkedin.com/pulse/artificial-intelligence-fake-bill-schmarzo/ - Data wrangling
https://en.wikipedia.org/wiki/Data_wrangling - Data Wrangling Versus ETL: What’s the Difference?
https://tdwi.org/articles/2017/02/10/data-wrangling-and-etl-differences.aspx
Original. Reposted with permission.
Related:
- Great Data Scientists Don’t Just Think Outside the Box, They Redefine the Box
- Democratizing Artificial Intelligence, Deep Learning, Machine Learning with Dell EMC Ready Solutions
- The Key to Data Monetization