Data Retrieval with Web Scraping: A Practitioner’s Guide to NLP
Proven and tested hands-on strategies to tackle NLP tasks.
Thanks to Springboard for helping me develop this content as a way to make learning NLP easier for everyone and also to all the excellent students in the Data Science Career Track bootcamp for giving me new perspectives in this domain. Check out Springboard’s DSC bootcamp if you are interested in a career-focused structured path towards learning Data Science.

Introduction
Unstructured data, especially text, images and videos contain a wealth of information. However, due to the inherent complexity in processing and analyzing this data, people often refrain from spending extra time and effort in venturing out from structured datasets to analyze these unstructured sources of data, which can be a potential gold mine.

Natural Language Processing (NLP) is all about leveraging tools, techniques and algorithms to process and understand natural language-based data, which is usually unstructured like text, speech and so on. In this series of articles, we will be looking at tried and tested strategies, techniques and workflows which can be leveraged by practitioners and data scientists to extract useful insights from text data. We will also cover some useful and interesting use-cases for NLP. This article will be all about processing and understanding text data with tutorials and hands-on examples.
Outline for this Series
The nature of this series will be a mix of theoretical concepts but with a focus on hands-on techniques and strategies covering a wide variety of NLP problems. Some of the major areas that we will be covering in this series of articles include the following.
- Processing & Understanding Text
- Feature Engineering & Text Representation
- Supervised Learning Models for Text Data
- Unsupervised Learning Models for Text Data
- Advanced Topics
Feel free to suggest more ideas as this series progresses, and I will be glad to cover something I might have missed out on. A lot of these articles will showcase tips and strategies which have worked well in real-world scenarios.
What this article covers
This article will be covering the following aspects of NLP in detail with hands-on examples.
- Data Retrieval with Web Scraping
- Text wrangling and pre-processing
- Parts of Speech Tagging
- Shallow Parsing
- Constituency and Dependency Parsing
- Named Entity Recognition
- Emotion and Sentiment Analysis
This should give you a good idea of how to get started with analyzing syntax and semantics in text corpora.
Motivation
Formally, NLP is a specialized field of computer science and artificial intelligence with roots in computational linguistics. It is primarily concerned with designing and building applications and systems that enable interaction between machines and natural languages that have been evolved for use by humans. Hence, often it is perceived as a niche area to work on. And people usually tend to focus more on machine learning or statistical learning.

When I started delving into the world of data science, even I was overwhelmed by the challenges in analyzing and modeling on text data. However, after working as a Data Scientist on several challenging problems around NLP over the years, I’ve noticed certain interesting aspects, including techniques, strategies and workflows which can be leveraged to solve a wide variety of problems. I have covered several topics around NLP in my books “Text Analytics with Python” (I’m writing a revised version of this soon) and “Practical Machine Learning with Python”.
However, based on all the excellent feedback I’ve received from all my readers (yes all you amazing people out there!), the main objective and motivation in creating this series of articles is to share my learnings with more people, who can’t always find time to sit and read through a book and can even refer to these articles on the go! Thus, there is no pre-requisite to buy any of these books to learn NLP.
Getting Started
When building the content and examples for this article, I was thinking if I should focus on a toy dataset to explain things better, or focus on an existing dataset from one of the main sources for data science datasets. Then I thought, why not build an end-to-end tutorial, where we scrape the web to get some text data and showcase examples based on that!
The source data which we will be working on will be news articles, which we have retrieved from inshorts, a website that gives us short, 60-word news articles on a wide variety of topics, and they even have an app for it!
In this article, we will be working with text data from news articles on technology, sports and world news. I will be covering some basics on how to scrape and retrieve these news articles from their website in the next section.
Standard NLP Workflow
I am assuming you are aware of the CRISP-DM model, which is typically an industry standard for executing any data science project. Typically, any NLP-based problem can be solved by a methodical workflow that has a sequence of steps. The major steps are depicted in the following figure.

We usually start with a corpus of text documents and follow standard processes of text wrangling and pre-processing, parsing and basic exploratory data analysis. Based on the initial insights, we usually represent the text using relevant feature engineering techniques. Depending on the problem at hand, we either focus on building predictive supervised models or unsupervised models, which usually focus more on pattern mining and grouping. Finally, we evaluate the model and the overall success criteria with relevant stakeholders or customers, and deploy the final model for future usage.
Scraping News Articles for Data Retrieval
We will be scraping inshorts, the website, by leveraging python to retrieve news articles. We will be focusing on articles on technology, sports and world affairs. We will retrieve one page’s worth of articles for each category. A typical news category landing page is depicted in the following figure, which also highlights the HTML section for the textual content of each article.
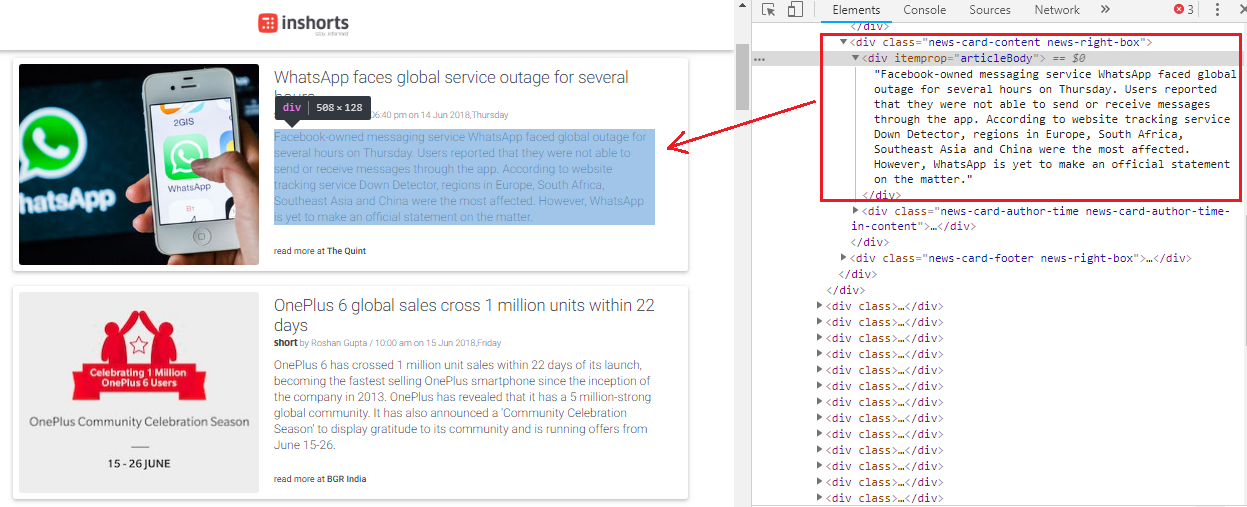
The landing page for technology news articles and its corresponding HTML structure
Thus, we can see the specific HTML tags which contain the textual content of each news article in the landing page mentioned above. We will be using this information to extract news articles by leveraging the BeautifulSoup and requests libraries. Let’s first load up the following dependencies.
import requests from bs4 import BeautifulSoup import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import os %matplotlib inline
We will now build a function which will leverage requests to access and get the HTML content from the landing pages of each of the three news categories. Then, we will use BeautifulSoup to parse and extract the news headline and article textual content for all the news articles in each category. We find the content by accessing the specific HTML tags and classes, where they are present (a sample of which I depicted in the previous figure).
It is pretty clear that we extract the news headline, article text and category and build out a data frame, where each row corresponds to a specific news article. We will now invoke this function and build our dataset.
news_df = build_dataset(seed_urls) news_df.head(10)

Our news dataset
We, now, have a neatly formatted dataset of news articles and you can quickly check the total number of news articles with the following code.
news_df.news_category.value_counts() Output: ------- world 25 sports 25 technology 24 Name: news_category, dtype: int64
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related:
- Robust Word2Vec Models with Gensim & Applying Word2Vec Features for Machine Learning Tasks
- Human Interpretable Machine Learning (Part 1) — The Need and Importance of Model Interpretation
- Implementing Deep Learning Methods and Feature Engineering for Text Data: The Skip-gram Model