Named Entity Recognition: A Practitioner’s Guide to NLP
Named entity recognition (NER) , also known as entity chunking/extraction , is a popular technique used in information extraction to identify and segment the named entities and classify or categorize them under various predefined classes.
In any text document, there are particular terms that represent specific entities that are more informative and have a unique context. These entities are known as named entities , which more specifically refer to terms that represent real-world objects like people, places, organizations, and so on, which are often denoted by proper names. A naive approach could be to find these by looking at the noun phrases in text documents. Named entity recognition (NER) , also known as entity chunking/extraction , is a popular technique used in information extraction to identify and segment the named entities and classify or categorize them under various predefined classes.
SpaCy has some excellent capabilities for named entity recognition. Let’s try and use it on one of our sample news articles.
[(US, 'GPE'), (China, 'GPE'), (US, 'GPE'), (China, 'GPE'), (Sunway, 'ORG'), (TaihuLight, 'ORG'), (200,000, 'CARDINAL'), (second, 'ORDINAL'), (Sunway, 'ORG'), (TaihuLight, 'ORG'), (93,000, 'CARDINAL'), (4,608, 'CARDINAL'), (two, 'CARDINAL')]

Visualizing named entities in a news article with spaCy
We can clearly see that the major named entities have been identified by spacy. To understand more in detail about what each named entity means, you can refer to the documentation or check out the following table for convenience.
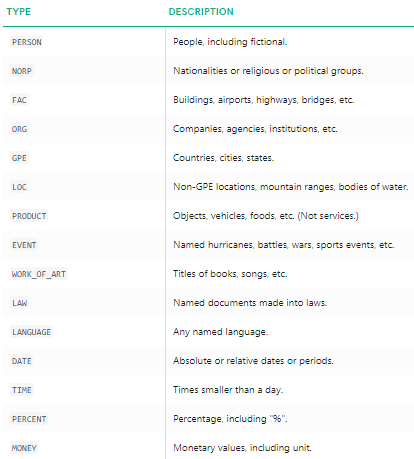
Named entity types
Let’s now find out the most frequent named entities in our news corpus! For this, we will build out a data frame of all the named entities and their types using the following code.
We can now transform and aggregate this data frame to find the top occuring entities and types.

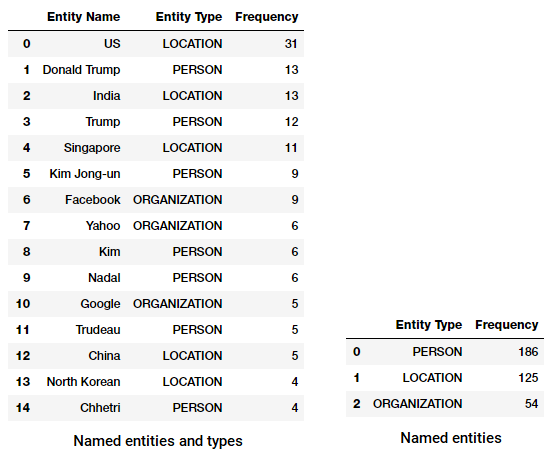
Top named entities and types in our news corpus
Do you notice anything interesting? (Hint: Maybe the supposed summit between Trump and Kim Jong!). We also see that it has correctly identified ‘Messenger’ as a product (from Facebook).
We can also group by the entity types to get a sense of what types of entites occur most in our news corpus.

Top named entity types in our news corpus
We can see that people, places and organizations are the most mentioned entities though interestingly we also have many other entities.
Another nice NER tagger is the StanfordNERTagger available from the nltkinterface. For this, you need to have Java installed and then download the Stanford NER resources. Unzip them to a location of your choice (I used E:/stanford in my system).
Stanford’s Named Entity Recognizer is based on an implementation of linear chain Conditional Random Field (CRF) sequence models. Unfortunately this model is only trained on instances of PERSON, ORGANIZATION and LOCATION types. Following code can be used as a standard workflow which helps us extract the named entities using this tagger and show the top named entities and their types (extraction differs slightly from spacy).
Top named entities and types from Stanford NER on our news corpus
We notice quite similar results though restricted to only three types of named entities. Interestingly, we see a number of mentioned of several people in various sports.
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related:
- Robust Word2Vec Models with Gensim & Applying Word2Vec Features for Machine Learning Tasks
- Human Interpretable Machine Learning (Part 1) — The Need and Importance of Model Interpretation
- Implementing Deep Learning Methods and Feature Engineering for Text Data: The Skip-gram Model