Text Wrangling & Pre-processing: A Practitioner’s Guide to NLP
I will highlight some of the most important steps which are used heavily in Natural Language Processing (NLP) pipelines and I frequently use them in my NLP projects.
There are usually multiple steps involved in cleaning and pre-processing textual data. I have covered text pre-processing in detail in Chapter 3 of ‘Text Analytics with Python’ (code is open-sourced). However, in this section, I will highlight some of the most important steps which are used heavily in Natural Language Processing (NLP) pipelines and I frequently use them in my NLP projects. We will be leveraging a fair bit of nltk and spacy, both state-of-the-art libraries in NLP. Typically a pip install <library> or a conda install <library> should suffice. However, in case you face issues with loading up spacy’s language models, feel free to follow the steps highlighted below to resolve this issue (I had faced this issue in one of my systems).
# OPTIONAL: ONLY USE IF SPACY FAILS TO LOAD LANGUAGE MODEL # Use the following command to install spaCy > pip install -U spacy OR > conda install -c conda-forge spacy # Download the following language model and store it in disk https://github.com/explosion/spacy-models/releases/tag/en_core_web_md-2.0.0 # Link the same to spacy > python -m spacy link ./spacymodels/en_core_web_md-2.0.0/en_core_web_md en_core Linking successful ./spacymodels/en_core_web_md-2.0.0/en_core_web_md --> ./Anaconda3/lib/site-packages/spacy/data/en_core You can now load the model via spacy.load('en_core')
Let’s now load up the necessary dependencies for text pre-processing. We will remove negation words from stop words, since we would want to keep them as they might be useful, especially during sentiment analysis.
❗ IMPORTANT NOTE: A lot of you have messaged me about not being able to load the contractions module. It’s not a standard python module. We leverage a standard set of contractions available in the
contractions.pyfile in my repository.Please add it in the same directory you run your code from, else it will not work.
import spacy
import pandas as pd
import numpy as np
import nltk
from nltk.tokenize.toktok import ToktokTokenizer
import re
from bs4 import BeautifulSoup
from contractions import CONTRACTION_MAP
import unicodedata
nlp = spacy.load('en_core', parse=True, tag=True, entity=True)
#nlp_vec = spacy.load('en_vecs', parse = True, tag=True, #entity=True)
tokenizer = ToktokTokenizer()
stopword_list = nltk.corpus.stopwords.words('english')
stopword_list.remove('no')
stopword_list.remove('not')
Removing HTML tags
Often, unstructured text contains a lot of noise, especially if you use techniques like web or screen scraping. HTML tags are typically one of these components which don’t add much value towards understanding and analyzing text.
'Some important text'
It is quite evident from the above output that we can remove unnecessary HTML tags and retain the useful textual information from any document.
Removing accented characters
Usually in any text corpus, you might be dealing with accented characters/letters, especially if you only want to analyze the English language. Hence, we need to make sure that these characters are converted and standardized into ASCII characters. A simple example — converting é to e.
'Some Accented text'
The preceding function shows us how we can easily convert accented characters to normal English characters, which helps standardize the words in our corpus.
Expanding Contractions
Contractions are shortened version of words or syllables. They often exist in either written or spoken forms in the English language. These shortened versions or contractions of words are created by removing specific letters and sounds. In case of English contractions, they are often created by removing one of the vowels from the word. Examples would be, do not to don’t and I would to I’d. Converting each contraction to its expanded, original form helps with text standardization.
We leverage a standard set of contractions available in the
contractions.pyfile in my repository.
'You all cannot expand contractions I would think'
We can see how our function helps expand the contractions from the preceding output. Are there better ways of doing this? Definitely! If we have enough examples, we can even train a deep learning model for better performance.
Removing Special Characters
Special characters and symbols are usually non-alphanumeric characters or even occasionally numeric characters (depending on the problem), which add to the extra noise in unstructured text. Usually, simple regular expressions (regexes) can be used to remove them.
'Well this was fun What do you think '
I’ve kept removing digits as optional, because often we might need to keep them in the pre-processed text.
Stemming
To understand stemming, you need to gain some perspective on what word stems represent. Word stems are also known as the base form of a word, and we can create new words by attaching affixes to them in a process known as inflection. Consider the word JUMP. You can add affixes to it and form new words like JUMPS, JUMPED, and JUMPING. In this case, the base word JUMP is the word stem.
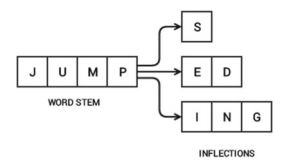
Word stem and its inflections (Source: Text Analytics with Python, Apress/Springer 2016)
The figure shows how the word stem is present in all its inflections, since it forms the base on which each inflection is built upon using affixes. The reverse process of obtaining the base form of a word from its inflected form is known as stemming. Stemming helps us in standardizing words to their base or root stem, irrespective of their inflections, which helps many applications like classifying or clustering text, and even in information retrieval. Let’s see the popular Porter stemmer in action now!
'My system keep crash hi crash yesterday, our crash daili'
The Porter stemmer is based on the algorithm developed by its inventor, Dr. Martin Porter. Originally, the algorithm is said to have had a total of five different phases for reduction of inflections to their stems, where each phase has its own set of rules.
Do note that usually stemming has a fixed set of rules, hence, the root stems may not be lexicographically correct. Which means, the stemmed words may not be semantically correct, and might have a chance of not being present in the dictionary (as evident from the preceding output).
Lemmatization
Lemmatization is very similar to stemming, where we remove word affixes to get to the base form of a word. However, the base form in this case is known as the root word, but not the root stem. The difference being that the root word is always a lexicographically correct word (present in the dictionary), but the root stem may not be so. Thus, root word, also known as the lemma, will always be present in the dictionary. Both nltk and spacy have excellent lemmatizers. We will be using spacy here.
'My system keep crash ! his crash yesterday , ours crash daily'
You can see that the semantics of the words are not affected by this, yet our text is still standardized.
Do note that the lemmatization process is considerably slower than stemming, because an additional step is involved where the root form or lemma is formed by removing the affix from the word if and only if the lemma is present in the dictionary.
Removing Stopwords
Words which have little or no significance, especially when constructing meaningful features from text, are known as stopwords or stop words. These are usually words that end up having the maximum frequency if you do a simple term or word frequency in a corpus. Typically, these can be articles, conjunctions, prepositions and so on. Some examples of stopwords are a, an, the, and the like.
', , stopwords , computer not'
There is no universal stopword list, but we use a standard English language stopwords list from nltk. You can also add your own domain-specific stopwords as needed.
Bringing it all together — Building a Text Normalizer
While we can definitely keep going with more techniques like correcting spelling, grammar and so on, let’s now bring everything we learnt together and chain these operations to build a text normalizer to pre-process text data.
Let’s now put this function in action! We will first combine the news headline and the news article text together to form a document for each piece of news. Then, we will pre-process them.
{'clean_text': 'us unveils world powerful supercomputer beat china us unveil world powerful supercomputer call summit beat previous record holder china sunway taihulight peak performance trillion calculation per second twice fast sunway taihulight capable trillion calculation per second summit server reportedly take size two tennis court',
'full_text': "US unveils world's most powerful supercomputer, beats China. The US has unveiled the world's most powerful supercomputer called 'Summit', beating the previous record-holder China's Sunway TaihuLight. With a peak performance of 200,000 trillion calculations per second, it is over twice as fast as Sunway TaihuLight, which is capable of 93,000 trillion calculations per second. Summit has 4,608 servers, which reportedly take up the size of two tennis courts."}
Thus, you can see how our text pre-processor helps in pre-processing our news articles! After this, you can save this dataset to disk if needed, so that you can always load it up later for future analysis.
news_df.to_csv('news.csv', index=False, encoding='utf-8')
Bio: Dipanjan Sarkar is a Data Scientist @Intel, an author, a mentor @Springboard, a writer, and a sports and sitcom addict.
Original. Reposted with permission.
Related:
- Robust Word2Vec Models with Gensim & Applying Word2Vec Features for Machine Learning Tasks
- Human Interpretable Machine Learning (Part 1) — The Need and Importance of Model Interpretation
- Implementing Deep Learning Methods and Feature Engineering for Text Data: The Skip-gram Model