 Ontology and Data Science
Ontology and Data Science
 Ontology and Data Science
Ontology and Data ScienceIn simple words, one can say that ontology is the study of what there is. But there is another part to that definition that will help us in the following sections, and that is ontology is usually also taken to encompass problems about the most general features and relations of the entities which do exist.

Photo by Valentin Antonucci from Pexels
If you are new to the word ontology don’t worry, I’m going to give a primer on what it is, and then why it matters for the data world. I’ll be explicit in the difference between philosophical ontology and the ontology related to information and data in computer science.
Ontology (the philosophical part)

In simple words, one can say that ontology is the study of what there is. But there is another part to that definition that will help us in the following sections, and that is ontology is usually also taken to encompass problems about the most general features and relations of the entities which do exist.
Ontology open new doors for what there is too. Let me give you an example.

Quantum mechanics opened a new view of reality and what “exists” in nature. For some physicists in the 1900s there was simply no reality expressed in the quantum formalism. At the other extreme, there were many quantum physicists who took the diametrically opposite view: that the unitarily evolving quantum state completely describes actual reality, with the alarming implication that practically all quantum alternatives must always continue to coexist (in superposition). And thus opening the whole world to a new view and understanding of the “things” that “exists” in nature.
But let’s come back to the relation of entities part of the definition. Sometimes when we talk about entities and their relation, ontology is referred as formal ontology. These are theories that attempt to give precise mathematical formulations of the properties and relations of certain entities. Such theories usually propose axioms about these entities in question, spelled out in some formal language based on some system of formal logic.
And this will allow us to do a quantum jump to next part of the article.

https://xkcd.com/1240/
Ontology (the information and computational part)
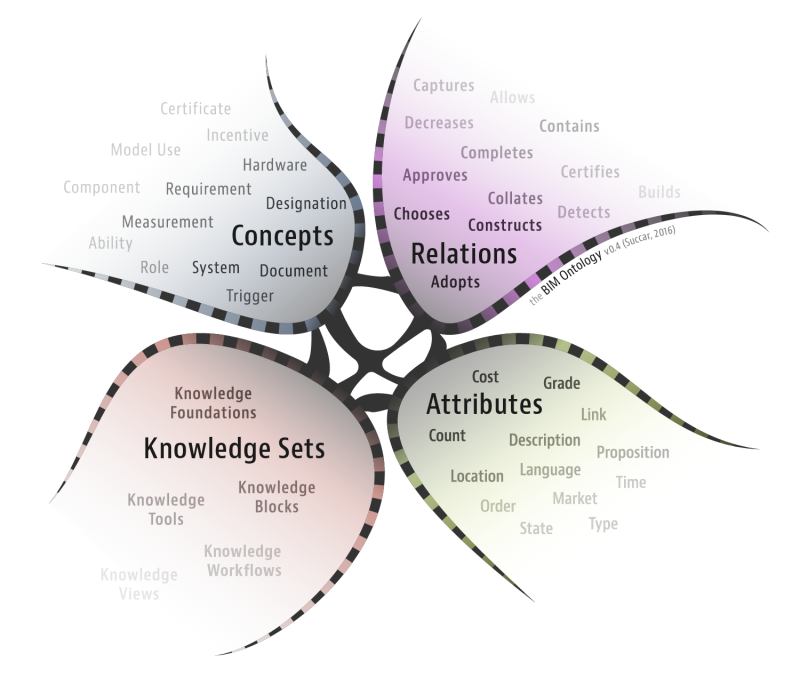
If we bring back the definition of formal ontology from above, and then we think of data and information, it’s possible to set up a framework to study data and its relation to other data. In this framework we represent information in an especially useful way. Information represented in a particular formal ontology can be more easily accessible to automated information processing, and how best to do this is an active area of research in computer science like data science. The use of the formal ontology here is representational. It is a framework to represent information, and as such it can be representationally successful whether or not the formal theory used in fact truly describes a domain of entities.
Now it’s a good moment to see how ontology can help us in the data science world.
If you remember in my last article about semantic technologies:
I talked about the concept of Linked Data. The goal of Linked Data is to publish structured data in such a way that it can be easily consumed and combined with other Linked Data. And also I discussed the concept of the knowledge graph which consists in integrated collections of data and information that also contains huge numbers of links between different data.
Well the missing concept in all those definition was ontology. Because that’s the way we can connect entities and understand their relationships. With ontology one can enable such a description, but first we need to formally specify components such as individuals (instances of objects), classes, attributes and relations as well as restrictions, rules and axioms.
Here’s a pictographic way of explaining the paragraph above:

https://www.ontotext.com/knowledgehub/fundamentals/what-are-ontologies/
Data Bases modeling and ontologies
Currently, most of the technologies that employ data modeling languages (like SQL) are designed using a rigid “Build the Model, then Use the Model” mindset.
For example, suppose you want to change a property in a relational database. You had previously thought that the property was single-valued, but now it needs to be multi-valued. For almost all modern relational databases, this change would require you to delete the entire column for that property and then create an entirely new table that holds all of those property values plus a foreign key reference.
This is not only a lot of work, but it will also invalidate any indices that deal with the original table. It will also invalidate any related queries that your users have written. In short, making that one change can be very difficult and complicated. Often, such changes are so troublesome that they are simply never made.
By contrast, all data modeling statements (along with everything else) in ontological languages for data are incremental, by their very nature. Enhancing or modifying a data model after the fact can be easily accomplished by modifying the concept.
From RDBS to the Knowledge Graph
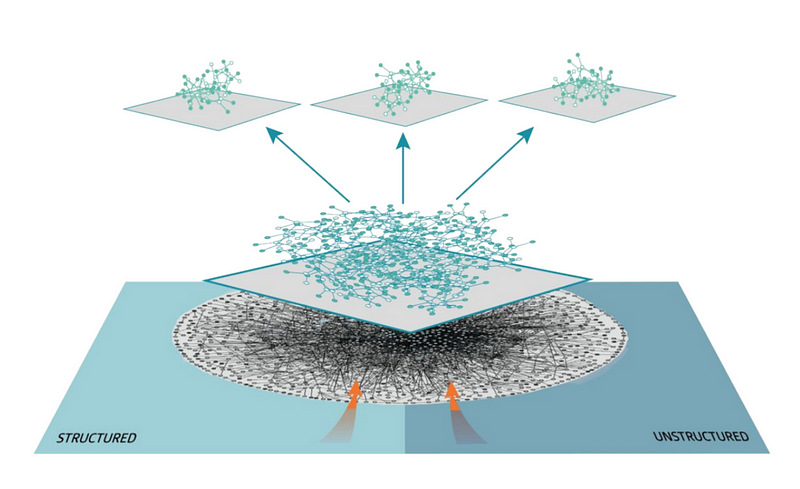
The easiest framework I’ve found so far to transform your data lake into a smart data lake is Anzo. With this you can take the first step towards a fully connected Enterprise Data Fabric.
The Data Fabric is the platform that supports all the data in the company. How it’s managed, described, combined and universally accessed. This platform is formed from an Enterprise Knowledge Graph to create an uniform and unified data environment.
The formation of this data fabric first need to create ontologies between the data you have. This transition can also be thought of as going from traditional data bases to graph data bases + semantics.
According to this presentation by the company Cambridge Semantics there are three reasons why graph data bases are useful:
- Graph Database offerings are showing maturity in capability and diversity
- Graph is being used beyond classical graph problems
- Digital Transformation of complex data requires graph
So if you tie this benefits with a semantic layer, built on ontologies, you can go from having your data like this:
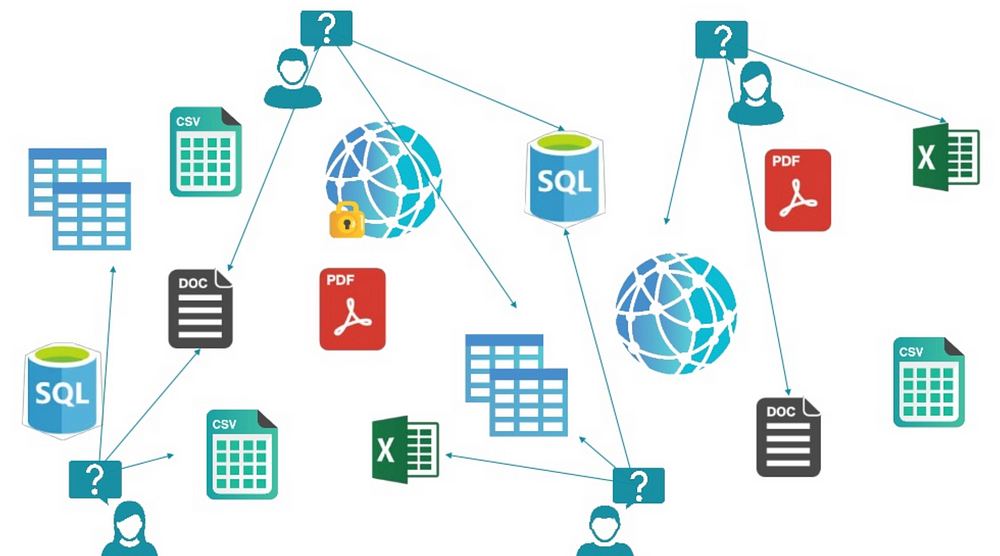
https://www.slideshare.net/camsemantics/the-year-of-the-graph
to this
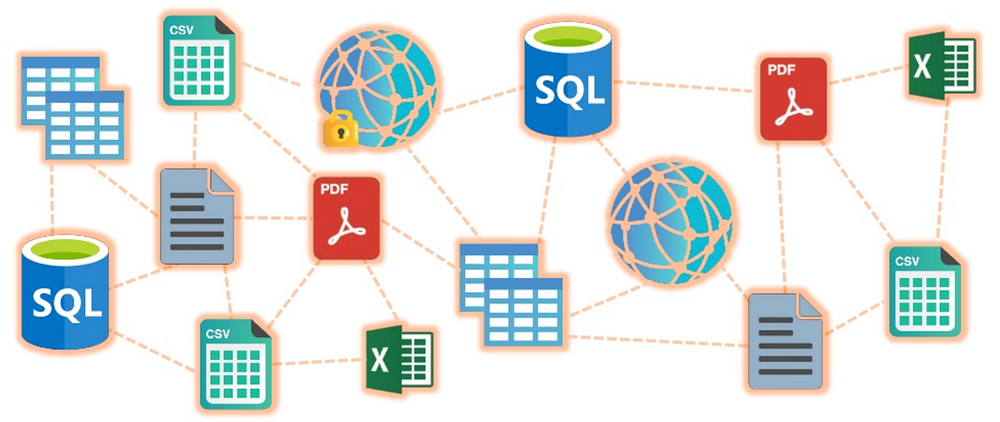
https://www.slideshare.net/camsemantics/the-year-of-the-graph
where you have a human-readable representation of data that uniquely identifies and connects data with common business terms. This layer helps end users access data autonomously, securely and confidently.
And then you can create complex models for discovering patterns in your different data bases.
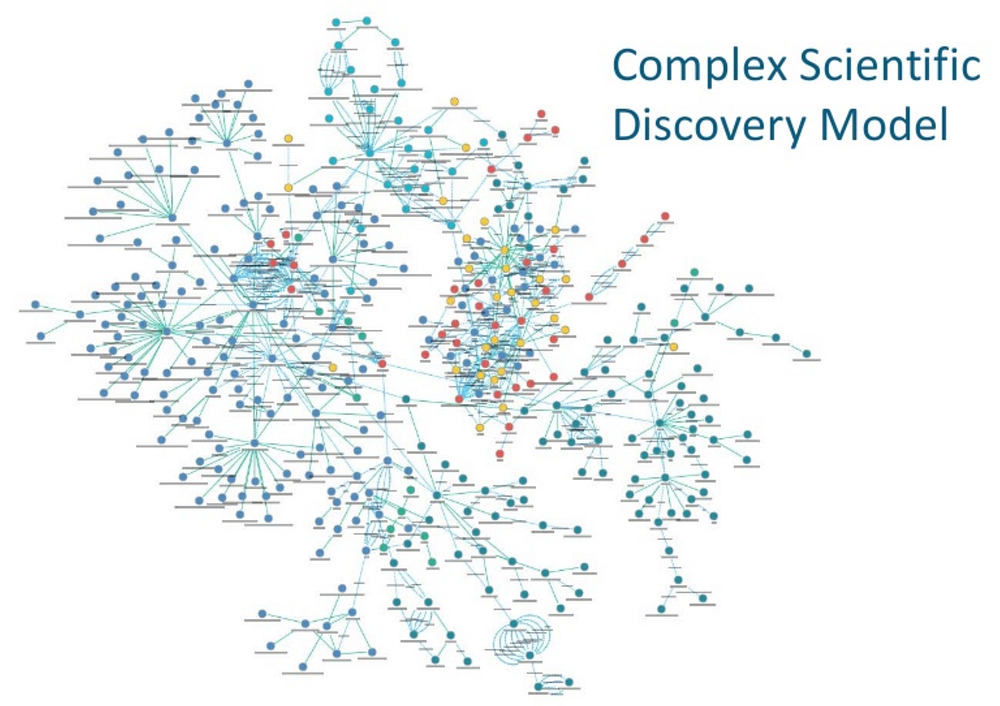
https://www.slideshare.net/camsemantics/the-year-of-the-graph
Inside of that you have ontologies representing the relations between entities. Maybe an example of such an ontology would be good here. This is taken from
Let’s create an ontology about your employees and consultants:
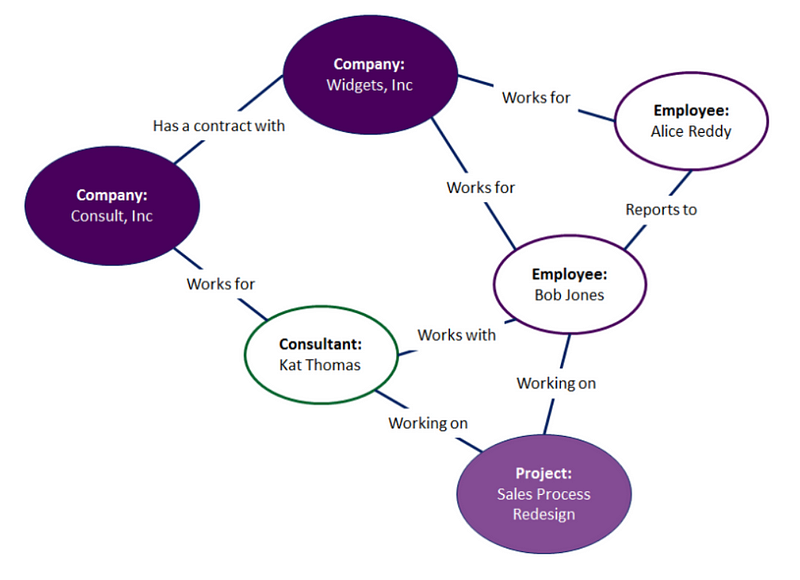
In this example, Kat Thomas is a consultant who is working with Bob Jones on a Sales Process Redesign project. Kat works for Consult, Inc and Bob reports to Alice Reddy. We can infer a lot of information through this ontology. Since the Sales Process Redesign is about sales we can infer that Kat Thomas and Bob Jones have expertise in sales. Consult, Inc must provide expertise in this area as well. We also know that Alice Reddy is likely responsible for some aspect of sales at Widgets, Inc because her direct report is working on the Sales Process Redesign project.
You of course can have that in a relational database with primary keys and then create several joins to get the same relationships but this is more intuitive and easier to understand.
And the amazing part here is that Anzo will connect to your data lake (meaning a whole lot of data inside of HDFS or Oracle or whatever) and create this graph for you, automatically! And then you can go and add or change the ontologies yourself.
The future of Data Science (only next year lol)
In this article:
I talked about what will happen (maybe) in the next years for data science.
For me the key trends for 2019:
- AutoX: We will see more companies developing and including into their stack technologies and libraries for automatic Machine and Deep Learning. The X here means that this auto-tools will be extended to data ingestion, data integration, data cleansing, exploration and deployment. Automation is here to stay.
- Semantic technologies: On the most interesting discoveries for me this year was the connection between DS and semantics. It’s not a new field in the data-world but I see more people getting an interest in the field of semantics, ontologies, knowledge-graphs and its connection to DS and ML.
- Programming less: This is a hard thing to say, but with automation in almost every step of the DS process we will program less and less everyday. We will have tools for creating code and that will understand what we want with NLP and then transform that into queries, sentences and full programs. I think [programming] it’s still a very important thing to learn, but it will be more easy soon.
This is one of the reasons why I’m creating this article, trying to follow what’s happening across the industry, and you should be aware of this. We will program less, and will use semantics technologies more in the near future. It’s closer to the way we think. I mean do you think in relational data bases? I’m not saying we think in graphs, but it’s much easier to pass information between our heads and a knowledge graph than creating weird data base models.
Expect more from me about this interesting topic. And please if you have any suggestions let me know :)
If you have questions just follow me on Twitter:
and LinkedIn:
See you there :)
Bio: Favio Vazquez is a physicist and computer engineer working on Data Science and Computational Cosmology. He has a passion for science, philosophy, programming, and music. He is the creator of Ciencia y Datos, a Data Science publication in Spanish. He loves new challenges, working with a good team and having interesting problems to solve. He is part of Apache Spark collaboration, helping in MLlib, Core and the Documentation. He loves applying his knowledge and expertise in science, data analysis, visualization, and automatic learning to help the world become a better place.
Original. Reposted with permission.
Related:
- What is an Ontology? The simplest definition you’ll find… or your money back*
- AI, Data Science, Analytics Main Developments in 2018 and Key Trends for 2019
- The Core of Data Science