What to do when your training and testing data come from different distributions
However, sometimes only a limited amount of data from the target distribution can be collected. It may not be sufficient to build the needed train/dev/test sets. What to do in such a case? Let us discuss some ideas!
By Nezar Assawiel, Machine Learning Developer, Founder at Clinical AI

credit: https://www.chessbazaar.com/blog/game-chess-can-make-child-genius-smarter/
To build a well-performing machine learning (ML) model, it is essential to train the model on and test it against data that come from the same target distribution.
However, sometimes only a limited amount of data from the target distribution can be collected. It may not be sufficient to build the needed train/dev/test sets.
Yet similar data from other data distributions might be readily available. What to do in such a case? Let us discuss some ideas!
Some background knowledge
To better follow the discussion here, you can read up on the following basic ML concepts, if you are not familiar with them already:
- Train, dev (development), and test sets: Note that the dev set is also called the validation or the hold-on set. This post is a good short introduction to the topic.
- Bias (underfitting) and variance (overfitting) errors: This is a great simple explanation of these errors.
- How the train/dev/test split is correctly made: You may refer to this post that I have written before for a short background on this topic.
Scenario
Say you are building a dog-image classifier application that determines if an image is of a dog or not.
The application is intended for users in rural areas who can take pictures of animals by their mobile devices for the application to classify the animals for them.
Studying the target data distribution — you found that the images are mostly blurry, low resolution, and similar to the following:

Left: Dog (Volpino Italiano breed), Right: Arctic fox.
You were only able to collect 8,000 such images, which is not enough to build the train/dev/test sets. Let us assume you have determined you’ll need at least 100,000 images.
You wondered if you could use images from another dataset — in addition to the 8,000 images you collected — to build the train/dev/test sets.
You realized you can easily scrape the web to build a dataset of 100,000 images or more, with similar dog-image vs. non-dog-image frequencies to those frequencies required.
But, clearly this web dataset comes from a different distribution, with high resolution and clear images such as the following:



Images of dogs (left and right) and a fox (center).
How would you build the train/dev/test sets?
You can’t only use the original 8,000 images you collected to build the train/dev/test sets as they are not enough to make a well-performing classifier. Generally, computer vision as other natural perception problems — speech recognition or natural language processing — need a lot of data.
Also, you can’t only use the web dataset. The classifier will not perform well on the users’ blurry images, which are different from the clear, high definition web images used to train the model.
So, what do you do? Let us consider some possibilities.
A possible option — shuffling the data
Something you can do is to combine the two datasets and randomly shuffle them. Then, split the resulting dataset into train/dev/test sets.
Assuming you decided to go with a 96:2:2% split for the train/dev/test sets, this process will be something like this:
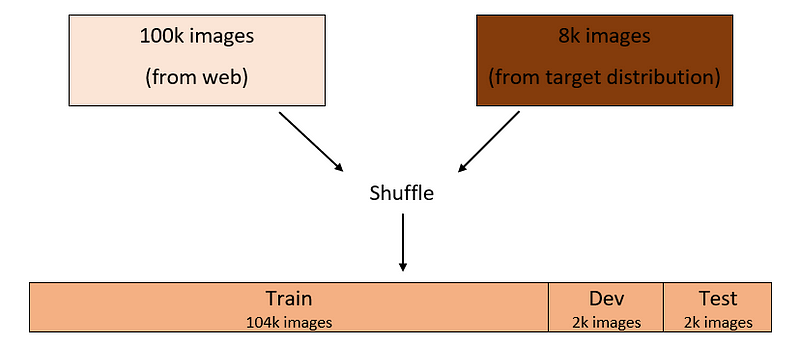
With this set up, the train/dev/test sets all come from the same distribution, as illustrated by the colors in the graph above, which is desired.
However, there a big drawback here!
If you look at the dev set, out of 2,000 images, on average only 148 images come from the target distribution.
This means that for the most part you are optimizing the classifier for the web images distribution (1,852 images out of 2,000 images) — which is not what you want!
The same thing can be said about the test set when assessing the performance of the classifier against it. So, this is not a good way to make the train/dev/test split.
A better option
An alternative is to make the dev/test sets come from the target distribution dataset, and the training set from the web dataset.
Say you’re still using 96:2:2% split for the train/dev/test sets as before. The dev/test sets will be 2,000 images each — coming from the target distribution — and the rest will go to the train set, as illustrated below:
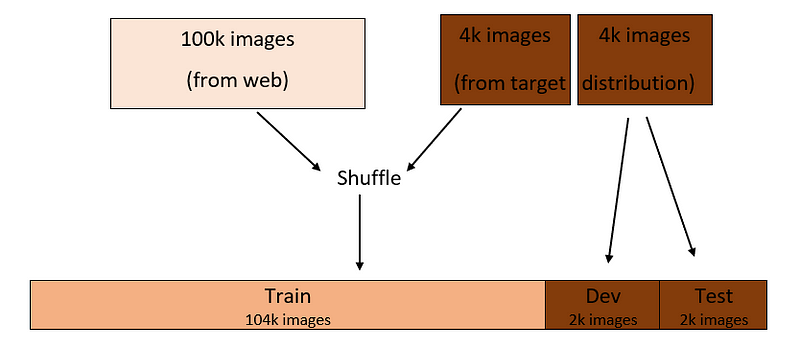
Using this split, you will be optimizing the classifier to perform well on the target distribution, which is what you care about. This is because the images of the dev set come solely from the target distribution.
However, the training distribution is now different from the dev/test distribution. This means that for the most part, you are training the classifier on web images. Thus, it will take longer and more effort to optimize the model.
More importantly, you will not be able to easily tell if the classifier error on the dev set relative to the error on the train set is a variance error, a data mismatch error, or a combination of both.
Let us consider this in more detail, and see what we can do about it.
Variance vs data mismatch
Consider the train/dev/test split from the second option above. Assume the human error is zero, for simplicity.
Also, let us assume you found that the training error to be 2% and the dev error 10%. How much of the 8% error between these two is due to the data mismatch between the two sets — given they are coming from different distributions? And how much is due to the variance of the model (overfitting)? We can’t tell.
Let us modify the train/dev/test split. Take out a small portion of the train set and call it the “bridge” set. The bridge set will not be used to train the classifier. It is instead an independent set. The split now has four sets belonging to two data distributions — as follows:

Variance error
With this split, let us assume you found training and dev errors to be 2% and 10%, respectively. You found the bridge error to be 9%, as shown below:

Now, how much of the 8% error between the train and dev set errors is a variance error, and how much of it is a data mismatch error?
Easy! The answer is 7% variance error and 1% data mismatch error. But why?
It’s because the bridge set comes from the same distribution as the train set, and the error difference between them is 7%. This means the classifier is overfitted to the train set. This tells us we have a high variance problem at hand.
Data mismatch error
Now, let us assume you found the error on the bridge set to be 3% and the rest as before as shown below:

How much of the 8% error between the train and dev sets is a variance error and how much of it is a data mismatch error?
The answer is 1% variance error and 7% data mismatch error. Why so?
This time, it is because the classifier performs well on a dataset it hasn’t seen before if it comes from the same distribution, such as the bridge set. It performs poorly if it comes from a different distribution, like the dev set. Thus, we have a data mismatch problem.
Reducing the variance error is a common task in ML. For example, you can use regularization methods, or allocate a larger train set.
However, mitigating the data mismatch error is a more interesting problem. So, let us talk bout it.
Mitigating data mismatch
To reduce the data mismatch error, you would need to somehow incorporate the characteristics of the dev/test datasets — the target distribution — into the train set.
Collecting more data from the target distribution to add to the train set is always the best option. But, if that is not possible (as we assumed at the beginning of our discussion), you can try the following approaches:
Error analysis
Analyzing the errors on the dev set and how they are different from the errors on the train set could give you ideas to address the data mismatch problem.
For example, if you find many of the errors on the dev set occur when the background of the animal’s image is rocky, you can mitigate such errors by adding animal images with rocky background to the train set.
Artificial data synthesis
Another way to incorporate the characteristics of the dev/test sets into the train set is to synthesize data with similar characteristics.
For example, we mentioned before that the images in our dev/test sets are mostly blurry in contrast to the clear images from the web that make most of our train set. You can artificially add blurriness to the images of the train set to be more similar to the dev/test sets as in the following image:

Image from the train set before and after blurring.
However, there is an important point to notice here!
You could end up overfitting your classifier to the artificial characteristics you made.
In our example, the blurriness you artificially made by some mathematical function might only be a small sub-set of the blurriness that exists in the images of the target distribution.
In other words, the blurriness in the target distribution could be due to many reasons. For example, fog, low resolution camera, subject movement could all be causes. But your synthesized blurriness may not represent all of these causes.
More generally, when synthesizing data for the training set for any type of problem (such as computer vision, or speech recognition), you could overfit your model to the synthesized dataset.
This dataset may look representative enough of the target distribution to the human eye. But in fact, it is only a small set of the target distribution. So, just keep this in mind while using this powerful tool — data synthesis.
In Summary
When developing an ML model, ideally the trian/dev/test datasets should all come from the same data distribution — that of the data which the model will encounter when used by the userbase.
However, sometimes it is not possible to collect enough data from the target distribution to build the trian/dev/test sets, while similar data from other distributions is readily available.
In such cases, the dev/test sets should come from the target distribution while the data from the other distributions can be used to build (most of) the train set. Data mismatch techniques can then be used to mitigate the the data distribution differences between the train set vs the dev/test sets.
Bio: Nezar Assawiel is a Machine Learning Developer and Founder at Clinical AI.
Original. Reposted with permission.
Related: