Using Caret in R to Classify Term Deposit Subscriptions for a Bank
This article uses direct marketing campaign data from a Portuguese banking institution to predict if a customer will subscribe for a term deposit. We’ll be working with R’s Caret package to achieve this.

In this article, we’ll use direct marketing campaign data from a Portuguese banking institution to predict if a customer will subscribe for a term deposit. We’ll be working with R’s Caret package to achieve this.
While it’s not advisable to lift this example and apply it to a real-world business scenario, it will serve as a guide for how to approach solving such a problem. Applying it to real scenario will require a few tweaks and domain expertise in the marketing and banking sectors.
Before we dive in further, let’s look at what the official docs say about the Caret package:
The
caretpackage (short for _C_lassification _A_nd _RE_gression _T_raining) is a set of functions that attempt to streamline the process for creating predictive models. The package contains tools for:* data splitting
* pre-processing
* feature selection
* model tuning using resampling
* variable importance estimationas well as other functionality.
There are many different modeling functions in R. Some have different syntax for model training and/or prediction. The package started off as a way to provide a uniform interface the functions themselves, as well as a way to standardize common tasks (such parameter tuning and variable importance).
The current release version can be found on CRAN and the project is hosted on GitHub.
This package is similar to the Scikit-learn package that wraps machine learning functions in Python. Working without these packages in R and Python is possible. However, Caret and Scikit-learn streamline the process of applying machine learning algorithms.
Loading the Data
We shall use the read_table utility from the Tidyverse to load in our dataset. We specify the header and a semicolon as the separator.
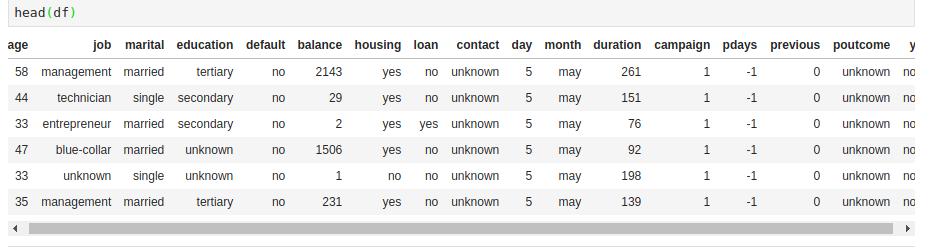
A complete description of the columns can be found here. We can quickly check the head of the dataset. One important thing to note is the y column that we’re going to predict. The column indicates whether or not a customer subscribed for a term deposit.
R has a package known as DataExplorer that will enable us to quickly explore the dataset. If you don’t have any of the packages mentioned in this article, just install them using the install.packages(“package name”) command.
Using the introduce function, we see the number of columns, rows, and missing values:

Before diving into machine learning, we sometimes want to plot a few graphs to give us a glimpse into our dataset. DataExplorer provides one function to plot all these graphs.
A quick look at the graphs shows us that most of the customers are blue-collar workers and are married.

One-Hot Encoding
We noticed earlier that some of our columns are categorical. In order to use them in our machine learning model, we have to convert them to dummy variables. This will involve converting them into zeros and ones.
We also have to be keen to drop the first dummy variable in order to avoid the dummy variable trap. So we usually remain with N-1 dummy variables. For example, instead of having a column for both male and female, we want to have one column that will have 1 for male and 0 for female, or vice versa.
R has several packages that one can use to convert columns into dummy variables. In this case, we’ll use the fastDummies package. We utilize the dummy_cols for the conversion and specify remove_first_dummy to TRUE in order to avoid the dummy variable trap.
Next, we select the columns that we’ll use in our machine learning model. We achieve this by specifying the columns to keep in a variable and then use that to make the selection.
If we check the head of our dataset, we notice that every column is now numerical. We’re now ready to move on to the next step where we’ll use Caret to build our machine learning model.
Using Caret to Build the Model
We start by importing the Caret library in order to access its functions. As we saw at the beginning, Caret is the library in R that wraps most of the machine learning functionalities, hence making it much easier to apply them.
We now need to split our dataset into a training and test set. Caret enables us to do this using the createDataPartition function. This function creates a series of training and testing partitions. We first create an index that will split the dataset based on the labels. We specify a training set of 70% and a test set of 30%. list specifies whether the results should be a list or a matrix.
The next step is to use this index to subset the data in order to obtain the training and test set.
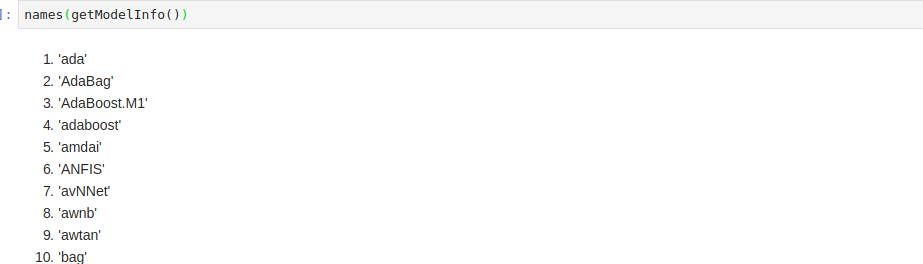
Just like the Scikit-learn package in Python, the Caret library in R makes it very easy to fit data to machine learning models. All you have to do is call the train function and specify the machine learning method. To see all the available methods, we can run this command names(getModelInfo())
Let’s now proceed to the training section. Since this is a classification problem, we have to use a classification algorithm. In this case, we’re using a boosted logistic regression. However, we can experiment with other algorithms by simply changing the method. After trying out a few algorithms, we can then settle on the one that gives us the highest accuracy. We preprocess the data by scaling and centering it using the preProcess attribute.
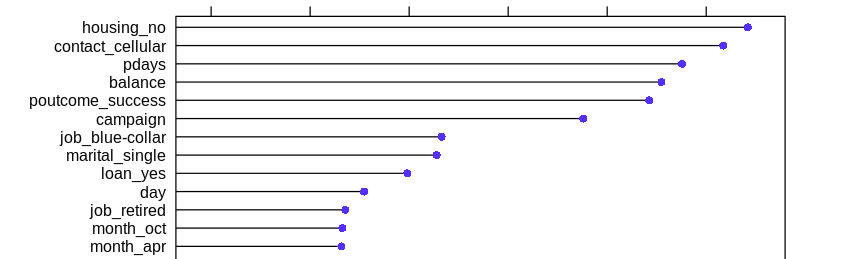
It would be nice if we could see the most important features in our model. Caret makes this easy by providing a varImp function, whose output is used to plot the feature importance graph.
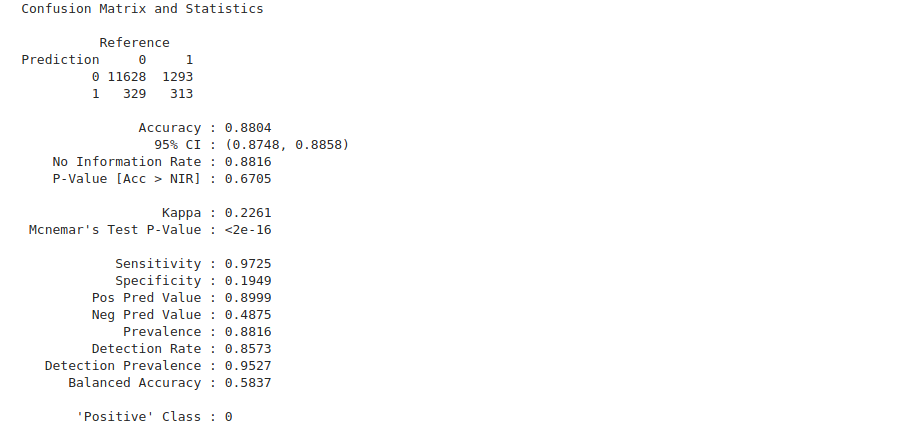
Let’s now move on to make predictions using the model we’ve defined above. Predicting is a straightforward task done by calling the predict function from Caret. Once the predictions are ready, we use the confusionMatrixfunction to compute the confusion matrix. This will also show us the model’s accuracy.
Clearly applying machine in R is as straightforward as it is using Python’s Scikit-learn. You can learn about Caret from its documentation, available here:
The caret Package
Documentation for the caret package.
Bio: Derrick Mwiti is a data analyst, a writer, and a mentor. He is driven by delivering great results in every task, and is a mentor at Lapid Leaders Africa.
Original. Reposted with permission.
Related:
- 2018’s Top 7 R Packages for Data Science and AI
- Automated Web Scraping in R
- Sales Forecasting Using Facebook’s Prophet