A Quick Guide to Feature Engineering
Feature engineering plays a key role in machine learning, data mining, and data analytics. This article provides a general definition for feature engineering, together with an overview of the major issues, approaches, and challenges of the field.
By Guozhu Dong, Wright State University
Feature engineering plays a key role in big data analytics. Machine learning and data mining algorithms cannot work without data. Little can be achieved if there are few features to represent the underlying data objects, and the quality of results of those algorithms largely depends on the quality of the available features. Data often exist in various forms such as image, text, graph, sequence, and time-series. A common way to represent data objects for data analytics is to use feature vectors. Data in raw forms such as those discussed above are not descried by informative features. Even data represented by feature vectors may still be in need of new effective features. Feature engineering is concerned with meeting the needs in generating and selecting an effective feature-vector based representation of data.

Figure 1: Feature Engineering Makes Data Analytics Possible and More Powerful
What is Feature Engineering: The feature engineering field contains a variety of issues and tasks. The most representative issues and tasks are feature transformation, feature generation and extraction, feature selection, automatic feature engineering, and feature analysis and evaluation.
- Feature transformation is about constructing new features from existing features; this is often achieved using mathematical mappings. For example, the BMI index is a feature obtained through feature transformation using a mathematic formula.
- Feature generation is about generating new features that are often not the result of feature transformation. For example, one generates new usable features for images from the pixels of the images (as the pixels are not usable features). Many domain specific ways for defining features also belong in the feature generation category. Feature generation methods can be generic automatic ones, in addition to domain specific ones. Patterns mined from given data can also be used to generate new features [2]. Sometimes the terms ``feature extraction” and “feature construction” are used for feature generation.
- Feature selection is about selecting a small set of features from a very large pool of features. The reduced feature set size makes it computationally feasible to use certain machine learning and data analytic algorithms. Feature selection may also lead to improved quality on the result of those algorithms. Feature selection has traditionally been focused on the classification problem [3], but it is also needed for other data analytic problems.
- Automatic feature engineering is about generic approaches for automatically generating a large number of features and selecting an effective subset of the generated features in the process.
- Feature analysis and evaluation is about evaluating the usefulness of features and feature sets. This is sometimes included as part of feature selection.
It should be emphasized that feature engineering is not just feature selection, and it is more than feature transformation.
A better sense on feature engineering can be gained by seeing what have been done on perhaps two of the most frequently used types of data, namely text data and image data. For text data, Reference [4] discussed the following topics: text as strings, the sequence of words representation, the bag of words representation, term weighting, beyond single words, structural representation of text, semantic structure features, latent semantic representation, explicit semantic representation, word embeddings for text representation, and context-sensitive text representation. For image data, Reference [5] discussed the following topics: classical visual feature representations (including color features, texture features, shape features), latent-feature extraction (including principal component analysis, kernel principal component analysis, multidimensional scaling, isomap, Laplacian eigenmaps), and deep image features (including convolutional neural networks).
Automatic feature construction is a popular approach to feature generation, with Word2vec [7] and DeepLearning based methods [8] being representative methods. We describe each briefly below.
(a) Word2vec is a group of methods that produce numerical feature vectors to represent words. They use shallow, two-layer neural networks to reconstruct linguistic contexts of words. Word2vec takes as its input a large corpus of text and produces a vector representation, typically of several hundred dimensions, for each unique word in the corpus. When words share common contexts, their word vectors are similar to each other. Figure 2 (from [7]) describes two architectures of Word2vec. The CBOW architecture trains a model to predict the current word based on the context described by Bag of Words, and the Skip-gram architecture trains a model to predict surrounding words given the current word. Word2vec has been generalized to image data, graph data and so on.
(b) DeepLearning methods convert high-dimensional data into a low-dimensional representation, and it does so by training a multilayer neural network with a small central layer to reconstruct high-dimensional input vectors [8]. The small central layer is used as low-dimensional representation. Many types of neural networks have been studied, including the autoencoder networks [6]. Figure 3 gives a high-level view of the autoencoder architecture [8].
New Challenges for Feature Engineering: Many effective feature generation methods, and many automatic feature engineering methods, remain to be discovered. Even traditional research topics such as feature selection and feature analysis need to be re-visited from new perspectives. Indeed, there are millions of ways to generate features, and hence feature selection and feature evaluation methods need to handle this high dimensionality. More importantly, traditional feature selection and evaluation methods are mostly limited to classification and regression problems. Clearly there is a need to develop new feature selection and evaluation methods for other data analytic tasks such as clustering, outlier detection, pattern mining, feature ranking, recommendation, and so on. Finally, much remains to be done to transform feature engineering from an art to a mature engineering discipline.
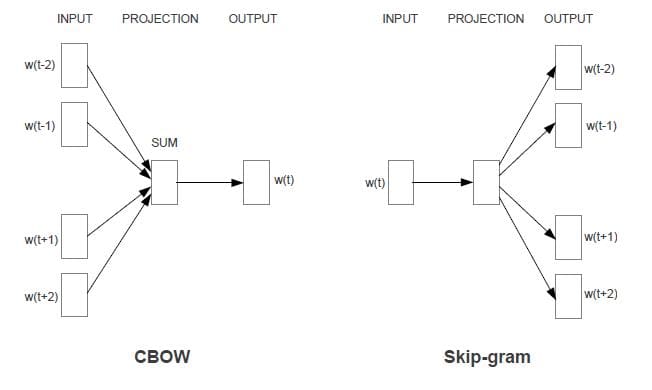
Figure 2: Two Architectures for Word2vec (from [7])
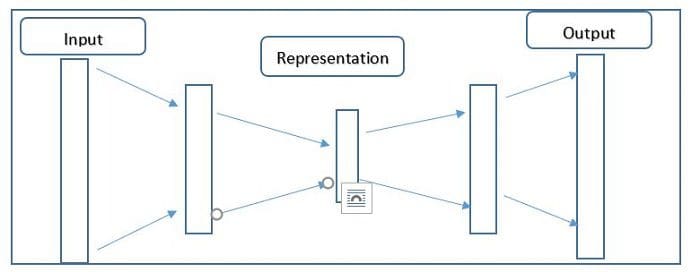
Figure 3: The Autoencoder Architecture
A Recent Book on Feature Engineering: In 2018 a new edited book on feature engineering [1] was published, with 12 contributed chapters from leading experts on different aspects of feature engineering.
As feature engineering is often data type specific and application dependent, this book contains chapters devoted to feature engineering for major data types such as text data, image data, sequence data, time series data, graph data, streaming data, software engineering data, Twitter data, and social media data. These chapters present methods for generating tried-and-tested, hand-crafted, domain-specific features, as well as automatic generic feature generation methods such as Word2Vec.
The book also contains chapters on feature selection, automatic approaches for feature transformation based feature engineering, automatic feature generation using deep learning approaches, and feature generation using frequent and contrast patterns. Several chapters are about using feature engineering in specific applications.
The book contains many useful feature engineering concepts and techniques, which are useful for multiple scenarios: (a) generate features to represent the data when there are no features, (b) generate effective features when (one may be concerned that) existing features are not good/competitive enough, (c) select features when there are too many features, (d) generate and select effective features for specific types of applications, and (e) understand the challenges associated with, and the needed approaches to handle, various data types.
In 2018 Guozhu Dong used the book to teach a well-received graduate level Feature Engineering Course, which was perhaps the first of its kind in the world (based on a search of the web). The course covered fundamental aspects of feature engineering, including feature generation for major dataset types, feature extraction, feature transformation, feature selection for different data analytic tasks, feature analysis and evaluation, and applications.
[1] Guozhu Dong and Huan Liu. Feature Engineering for Machine Learning and Data Analytics. CRC Press, 2018.
[2] Yunzhe Jia, James Bailey, Ramamohanarao Kotagiri, and Christopher Leckie. Pattern based Feature Generation. Chapter in Feature Engineering for Machine Learning and Data Analytics (edited by Dong and Liu). CRC Press, 2018.
[3] Yun Li and Tao Li. Feature Selection and Evaluation. Chapter in Feature Engineering for Machine Learning and Data Analytics (edited by Dong and Liu). CRC Press, 2018.
[4] Chase Geigle, Qiaozhu Mei, and ChengXiang Zhai. Feature Engineering for Text Data. Chapter in Feature Engineering for Machine Learning and Data Analytics (edited by Dong and Liu). CRC Press, 2018.
[5] Parag S. Chandakkar, Ragav Venkatesan, and Baoxin Li. Feature Extraction and Learning for Visual Data. Chapter in Feature Engineering for Machine Learning and Data Analytics (edited by Dong and Liu). CRC Press, 2018.
[6] Suhang Wang and Huan Liu. Deep Learning for Feature Representation. Chapter in Feature Engineering for Machine Learning and Data Analytics (edited by Dong and Liu). CRC Press, 2018.
[7] Tomas Mikolov, Kai Chen, Greg Corrado, Jeffrey Dean. Efficient Estimation of Word Representations in Vector Space. arXiv. 2013.
[8] Hinton, Geoffrey E., and Ruslan R. Salakhutdinov. Reducing the dimensionality of data with neural networks. Science 313.5786: 504-507. 2006.
Bio: Guozhu Dong is a professor at the Department of Computer Science and Engineering and the Knoesis Center at Wright State University.
Resources:
- On-line and web-based: Analytics, Data Mining, Data Science, Machine Learning education
- Software for Analytics, Data Science, Data Mining, and Machine Learning
Related: