How to Extend Scikit-learn and Bring Sanity to Your Machine Learning Workflow
In this post, learn how to extend Scikit-learn code to make your experiments easier to maintain and reproduce.
By Déborah Mesquita, Data Scientist
We usually hear (and say) that machine learning is just a commercial name for Statistics. That might be true, but if we're building models using computers what machine learning really comprehends is Statistics and Software Engineering.
To make great products: do machine learning like the great engineer you are, not like the great machine learning expert you aren't - Rules of Machine Learning: Best Practices for ML Engineering [1]
This combination of Statistics and Software Engineering brings new challenges to the Software Engineering world. Developing applications in the ML domain is fundamentally different from prior software application domains, as Microsoft researchers point out [2].
When you don't work in a large company or when you're just starting out in the field it's difficult to learn and apply Software Engineering best practices because finding this information is not easy. Fortunately, open-source projects can be a great source of knowledge and can help us address this need of learning from people that have more experience than us. One of my favorite ML libraries (and source of knowledge) is Scikit-learn.
The project does a great job of providing an easy-to-use interface while also providing solid implementations, being both a great way to start in the field of ML and also a tool used in the industry. Using scikit-learn tools and even reading maintainer's answers on the issue discussions on Github is a great way to learn from them. Scikit has a lot of contributors from industry and from academia, so as these people make contributions their knowledge gets “embedded” in the library. One rule of thumb of scikit-learn's project is that user code should not be tied to scikit-learn — which is a library, and not a framework [3]. This makes it easy to extend scikit functionalities to suit our needs.
Today we're going to learn how to do this, building a custom transformer and learning how to use it to build pipelines. By doing so our code becomes easy to maintain and reuse, two aspects of Software Engineering best practices.
The scikit-learn API
If you're familiar with scikit-learn you probably know how to use objects such as estimators and transformers, but it's good to formalize their definitions so we can build on top of them. The basic API consists of three interfaces (and once class can implement multiple interfaces):
- estimator - the base object, implements the fit() method
- predictor - an interface for making predictions, implements the predict() method
- transformer - interface for converting data, implements the transform() method
Scikit-learn has many out-of-the-box transformers and predictors, but we often need to transform data in different ways. Building custom transformers using the transformer interface makes our code maintainable and we can also use the new transformer with other scikit objects like Pipeline and RandomSearchCV or GridSearchCV. Let's see how to do that. All the code can be found here
Building a custom transformer
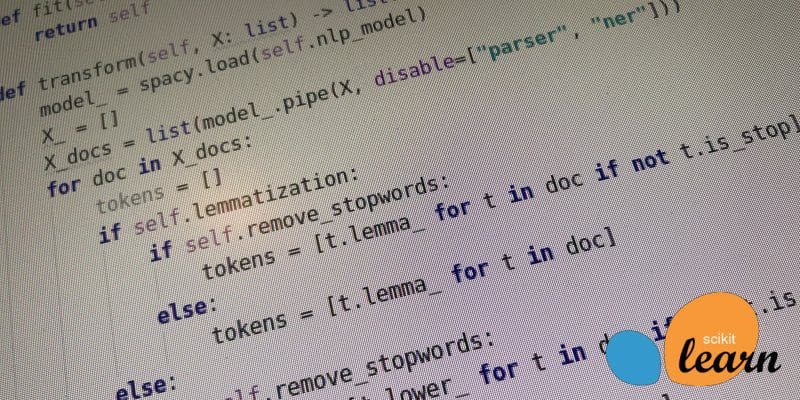
There are two kinds of transformers: stateless transformers and stateful transformers. Stateless transformers treat samples independently while stateful transformations depend on the previous data. If we need a stateful transformer the save the state on fit() method. Both stateless and stateful transformers should return self.
Most examples of custom transformers use numpy arrays, so let's try something different and build a transformer that uses spaCy models. Our goal is to create a model to classify documents. We want to know if lemmatization and stopword removal can increase the performance of the model. RandomSearchCV and GridSearchCV are great to experiment if different parameters can improve the performance of a model.
When we create a transformer class inheriting from the BaseEstimator class we get getparameters() and setparameters() methods for free, allowing us to use the new transformer in the search to find best parameter values. But to do that we need to follow some rules [4]:
- The name of the keyword arguments accepted by init() should correspond to the attribute on the instance
- All parameter should have sensitive defaults, so a user can instantiate an estimator simply calling EstimatorName()
- The validations should be done where the parameters are used; this means that should be no logic (not even input validation) on init()
The parameters we need are the spaCy language model, lemmatization and remove_stopwords.
Using scikit-learn pipelines
In machine learning many tasks are expressible as sequences or combinations of transformations to data [3]. Pipelines offer a clear overview of our preprocessing steps, turning a chain of estimators into one single estimator. Using pipelines is also a way to make sure that we are always performing the exactly same steps while training, doing cross-validation or making a prediction.
Each step of the pipeline should implement the transform() method. To create the model we'll use the new transformer, a TfidfVectorizer and a RandomForestClassifier. Each of these steps will turn into a pipeline step. The steps are defined as tuples, where the first element is the name of the step and the second element is the estimator object per se.
With that we can use the pipeline object to call fit() and predict() methods, like textpipeline.fit(train, labels and textclf.predict(data). We can use all methods the last step of the pipeline implements, so we can also call textclf.predictproba(data) to get the probability scores from the RandomForestClassifier for example.
Finding the best parameters with GridSearchCV
With GridSearchCV we can run an exhaustive search of the best parameters on a grid of possible values (RandomizedSearchCV is the non-exhaustive alternative). To do that we define a dict for the parameters, where the keys should be *name_of_pipeline_step*__*parameter_name* and the values should be lists with parameter values we want to try.
The RandomizedSaerchCV is also an estimator, so we can use all methods from the estimator used to create the RandomizedSaerchCV object (scikit API is indeed really consistent).
Takeaways
Machine Learning comes with challenges that the Software Engineering world is not familiar with. Building experiments represents a large part of our workflow, and doing that with messy code doesn't usually end up well. When we extend scikit-learn and use the components to write our experiments we make the task of maintaining our codebase easier, bringing sanity to our day-to-day tasks.
References
[1] https://developers.google.com/machine-learning/guides/rules-of-ml
[3] https://arxiv.org/pdf/1309.0238.pdf
[4] https://scikit-learn.org/stable/developers/contributing.html#apis-of-scikit-learn-objects
Bio: Déborah Mesquita (linkedin.com/in/deborahmesquita)is a data scientist who loves the craft of writing. She likes to think she's a polymath data scientist but the truth is that she still needs to learn a lot of Statistics.
Related:
- Train sklearn 100x Faster
- Data Science with Optimus Part 1: Intro
- 5 Step Guide to Scalable Deep Learning Pipelines with d6tflow