DeepMind Unveils MuZero, a New Agent that Mastered Chess, Shogi, Atari and Go Without Knowing the Rules
The new model showed great improvements over the previous AlphaZero agent.

Games have become one of most efficient vehicles for evaluating artificial intelligence(AI) algorithms. For decades, games have built complex competition, collaboration, planning and strategic dynamics that are a reflection of the most sophisticated tasks that AI agents face in the real world. From Chess, to Go to StarCraft, games have become a great lab to evaluate the capabilities of AI agents in a safe and responsible manner. However, most of those great milestones started with agents that were trained on the rules of the game. There is a complementary subset of scenarios in which agents are presented with a new environment without prior knowledge of its dynamics. Recently, DeepMind published a research paper unveiling MuZero, an AI agent that mastered several strategy games by learning the rules from scratch.
The idea of AI agents that can learn the dynamics of a new environment is a resemblance of our cognition processes as humans. Imagine a kid who discovered a new game in his/her IPad. Without knowing the rules, the kid will begin playing and rolling back bad moves until getting a handle on the game. Those same dynamics can be extrapolated to scenarios like economic policy design, crisis management strategies or even warfare. In the AI camp, reinforcement learning has emerged as the most popular discipline to master strategy games. Within reinforcement learning, there is an approach known as model-based reinforcement learning that focuses precisely on scenarios in which the agents need to understand a new environment prior to mastering specific tasks within it.
Model Based Reinforcement Learning
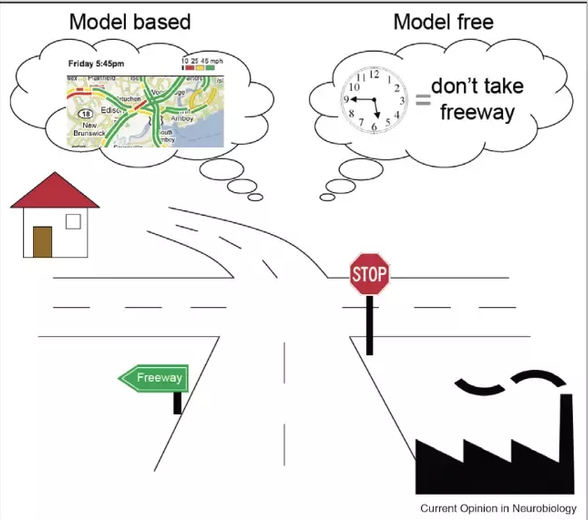
Modern reinforcement learning is divided in two main schools: model-free and model-based. Let’s illustrate these two approaches in a simple scenario in which you are trying to learn to ride a bike to take a quick trip to a friend’s house. The first step in your journey would be to learn to ride the bike itself. You can accomplish this by watching YouTube videos or reading books which might take a long time. Alternatively, you can follow your instincts and hope on the bike and try until you figure out how to ride. After that, you need to figure out how to get to your friend’s house. In this case, pure trial and error might not get you that far and you would need a bit of planning from your favorite map applications. This oversimplification illustrates a key difference between model-free and model-based reinforcement learning agents.
In model-free scenarios, the reinforcement learning agent operates knowing the dynamics of the environment. Technically, in model-free reinforcement learning, actions are sampled from some policy that is optimized indirectly through direct policy search (Policy gradients), a state-value function (Q-learning), or a combination of these (Actor-Critic). In real world scenarios it is challenging to deploy model-free methods because current state-of-the-art algorithms require millions of samples before any optimal policy is learned.
Model-based reinforcement learning scenarios focus on learning a predictive model of the real environment that is used to learn the controller of an agent. Model-Based reinforcement learning algorithms uses a reduced number of interactions with the real environment during the learning phase. Its aim is to construct a model based on these interactions, and then use this model to simulate the further episodes, not in the real environment but by applying them to the constructed model and get the results returned by that model. From the technical standpoint, a model-based reinforcement learning agent is represented by a Markov-decision process consisting of two components: a state transition model, predicting the next state, and a reward model, predicting the expected reward during that transition. The model is typically conditioned on the selected action, or a temporally abstract behavior such as an option. Model-based reinforcement learning has been the foundation behind major breakthroughs in reinforcement learning such as Open AI Dota2 agents as well as DeepMind’s Quake III, AlphaGo or AlphaStar.
In recent years, DeepMind has had several breakthroughs in strategy games including the famous AlphaZero, a model-free reinforcement learning agents that was able to master chess, shogi and go. AlphaZero had the advantage of knowing the rules of every game it was tasked with playing. Could the same performance be achieved with model-based reinforcement learning?
MuZero
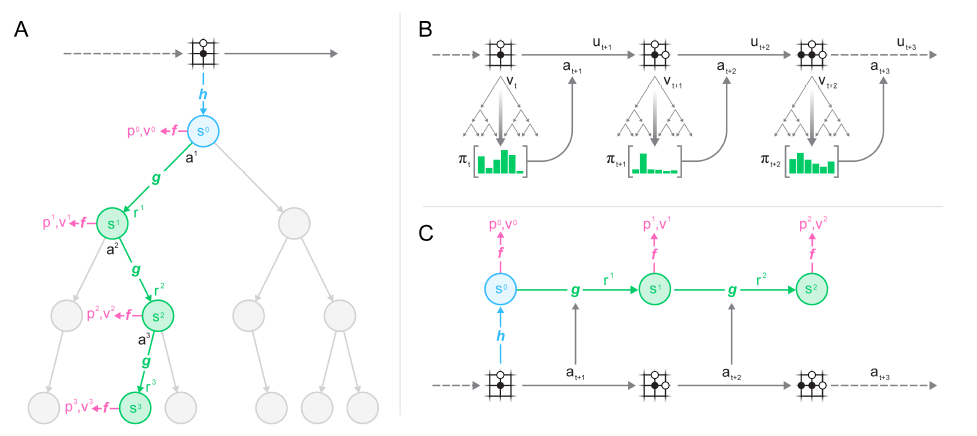
MuZero leverages model-based reinforcement learning to predict those aspects of the future that are directly relevant for planning. The model receives the observation (e.g. an image of the Go board or the Atari screen) as an input and transforms it into a hidden state. The hidden state is then updated iteratively by a recurrent process that receives the previous hidden state and a hypothetical next action. At every one of these steps the model predicts the policy (e.g. the move to play), value function (e.g. the predicted winner), and immediate reward (e.g. the points scored by playing a move). The model is trained end-to-end, with the sole objective of accurately estimating these three important quantities, so as to match the improved estimates of policy and value generated by search as well as the observed reward.
Similar to AlphaZero, MuZero’s planning process is based on two separate components: a simulator implements the rules of the game, which are used to update the state of the game while traversing the search tree; and a neural network jointly predicts the corresponding policy and value of a board position produced by the simulator. The entire knowledge of the environment is captured by the neural network and used in subsequent steps. The following figure illustrates how MuZero learns(A) and uses (B)the environment as well as how it trains(C) the model.
MuZero in Action
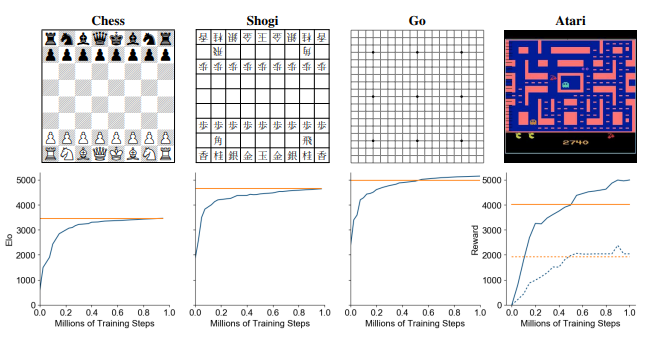
DeepMind trained MuZero in Go, Chess and Shogi as well as all 57 games in the Atari Learning Environment with remarkable results. For instance, in Go, MuZero slightly exceeded the performance of AlphaZero, despite using less computation per node in the search tree (16 residual blocks per evaluation in MuZero compared to 20 blocks in AlphaZero). This suggests that MuZero may be caching its computation in the search tree and using each additional application of the dynamics model to gain a deeper understanding of the position. Similarly, Atari, MuZero achieved a new state of the art for both mean and median normalized score across the 57 games of the Arcade Learning Environment, outperforming the previous state-of-the-art method R2D2.
The following figure shows the performance of MuZero in the four target environments. i. The x-axis shows millions of training steps. For chess, shogi and Go, the y-axis shows Elo rating, established by playing games against AlphaZero. Performance in Atari was evaluated using 50 simulations every fourth time-step, and then repeating the chosen action four times, as in prior work using 800 simulations per move for both players. MuZero’s Elo is indicated by the blue line, AlphaZero’s Elo by the horizontal orange line.
MuZero represents a major milestone for the reinforcement learning school as it showed that its possible to achieve superhuman performance in strategic tasks without having prior knowledge of the environment. MuZeo showed its efficiency across logically complex games such as chess, go and shogi as well as visually complex environments like Atari. The principles of MuZero can be applied to many mission critical AI tasks in real world environments.
Original. Reposted with permission.
Related:
- Recreating Imagination: DeepMind Builds Neural Networks that Spontaneously Replay Past Experiences
- DeepMind is Using This Old Technique to Evaluate Fairness in Machine Learning Models
- AlphaGo Zero: The Most Significant Research Advance in AI