Survey Segmentation Tutorial
Learn the basics of verifying segmentation, analyzing the data, and creating segments in this tutorial. When reviewing survey data, you will typically be handed Likert questions (e.g., on a scale of 1 to 5), and by using a few techniques, you can verify the quality of the survey and start grouping respondents into populations.
By Jason Wittenauer, Huron Consulting Group.
When reviewing survey data, you will typically be handed Likert questions (ex: answers with a scale of 1 to 5 with 1 being bad and 5 being good). Using a few techniques, you can verify the quality of the survey and start grouping respondents into populations. The steps we will be following are listed below:
- Analyzing our data set for scale.
- Using Principle Component Analysis (PCA) to verify that the survey is sound and grouping data.
- Checking for correlated questions.
- Setting up the Exploratory Factor Analysis (EFA) to create the final segments.
Data Review
The data set we will be using consists of 90 respondents answering questions based on how they like to shop for cars. This data was originally sourced from PromptCloud here, but can be found in this repository under the data folder. There are 14 options that respondents are considering when they buy a car: price, safety, exterior looks, etc. You will notice that there is a Respondent ID column added to the file placed in this repository. We will want to be able to tie the respondents to their segments for future reporting, so there should always be an ID included in your data set.
Setup Library
The first step is to set up all the packages that will be used in this analysis. The two main packages for the analysis are PCA and Factor Analyzer to generate all the modeling statistics we need to create our survey groupings.
In [1]:
import pandas as pd import numpy as np from sklearn.decomposition import PCA import matplotlib.pyplot as plt from factor_analyzer import FactorAnalyzer import os
Import Data
Next, we will read in our data set.
In [2]:
os.chdir('C:\\Projects\\Survey Segmentation')
df = pd.read_csv('Data\\CarPurchaseSurvey.csv')
df.head(10)
Out [2]:

As you can see, the data set has already been converted to numbers. If this has not been done on your data set, you will need to convert any text like "Good", "Neutral", "Bad", etc. into a numeric format. In this data set, 1 is very low, and 5 is very high.
Confirm Answer Scale
In case you don't know much about the survey data that is being analyzed, you can always check the scale of all the columns by looking for the min, max, and unique value counts. This will let you know if you need to rescale the data or not.
In [3]:
columnStatistics = pd.DataFrame(df.max(axis=0)) # will return max value of each column
columnStatistics.columns = ['MaxValues']
columnStatistics['MinValues'] = df.min(axis=0) # will return min value of each column
uniqueCounts = pd.DataFrame(columnStatistics.index)
uniqueCounts.set_index(0, inplace=True)
uniqueCounts['UniqueValues'] = np.nan
for col in df:
uniqueCounts.loc[col]['UniqueValues'] = df[col].nunique() # will return min value of each column
columnStatistics['UniqueValues'] = uniqueCounts['UniqueValues']
columnStatistics
Out [3]:
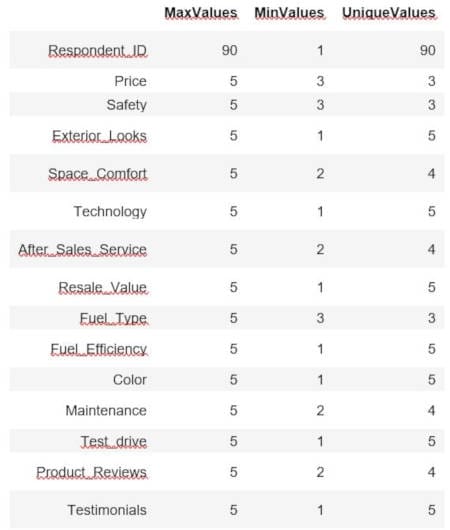
It appears we have a scale of 1 to 5 for all these questions. Be careful with assuming the scale, though, and you could end up with a question that just didn't have responses at the top or low end. This would make it appear to be on the same scale when it is not. The best option is always to review the original survey to verify all question scales. For our purposes, these questions were all on the same scale.
Prepare Data
When we analyze the data set in PCA and EFA, we do not want to include the ID column as part of the analysis. However, we do want to keep it around for reference purposes. Let's make it the dataframe index.
In [4]:
df.set_index('Respondent_ID', inplace=True)
Check Survey Validity Using PCA
Now we can run PCA to determine if the survey was written well enough to put respondents into various segments. First, we will set up our covariance matrix.
In [5]:
covar_matrix = PCA(n_components = len(df.columns)) #components are equal to the number of features we have covar_matrix.fit(df)
Out [5]:
PCA(copy=True, iterated_power='auto', n_components=14, random_state=None,
svd_solver='auto', tol=0.0, whiten=False)
Next, we will plot the eigenvalues of our features to verify that there are at a minimum of 2-3 features that have a value greater than 1.
In [6]:
plt.ylabel('Eigenvalues')
plt.xlabel('# of Features')
plt.title('PCA Eigenvalues')
plt.ylim(0,max(covar_matrix.explained_variance_))
plt.style.context('seaborn-whitegrid')
plt.axhline(y=1, color='r', linestyle='--')
plt.plot(covar_matrix.explained_variance_)
plt.show()
Out [6]:
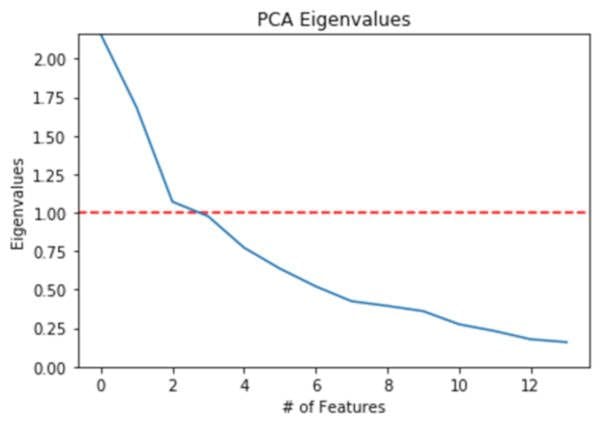
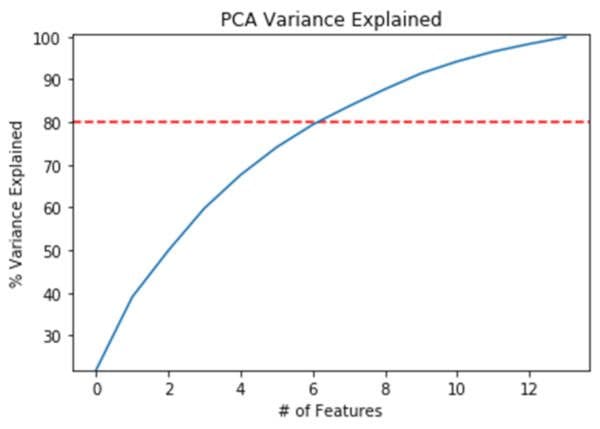
After confirming the eigenvalues, we can check to see that something less than the total number of features explains a large portion of the variance. In this case, we set the threshold at 80% and it looks like 6 features (less than 14) are explaining at least 80% of the variance.
In [7]:
variance = covar_matrix.explained_variance_ratio_ #calculate variance ratios
var=np.cumsum(np.round(covar_matrix.explained_variance_ratio_, decimals=3)*100)
plt.ylabel('% Variance Explained')
plt.xlabel('# of Features')
plt.title('PCA Variance Explained')
plt.ylim(min(var),100.5)
plt.style.context('seaborn-whitegrid')
plt.axhline(y=80, color='r', linestyle='--')
plt.plot(var)
plt.show()
Out [7]:
The last part of our initial survey validation checks is to make sure that the components of the PCA are showing different types of populations. If all the populations show Safety and Resale_Value as their top 2 features, then the survey isn't segmenting the population very well. In our below code, we will be looking at the top 3 features for each component, which look like very different populations.
In [8]:
components = pd.DataFrame(covar_matrix.components_ ,columns = df.columns)
components.rename(index = lambda x: 'PC-' + str(x + 1), inplace=True)
# Top 3 positive contributors
pd.DataFrame(components.columns.values[np.argsort(-components.values, axis=1)[:, :3]],
index=components.index,
columns = ['1st Max','2nd Max','3rd Max'])
Out [8]:
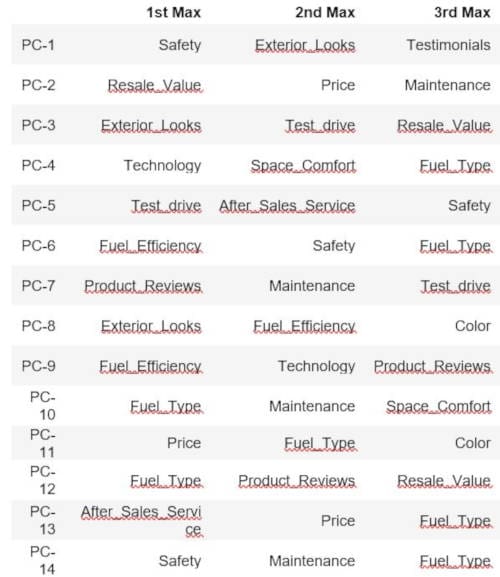
Correlating Questions
Survey questions can sometimes not produce different results. For example, everyone who rates Safety high might also rate Technology high. When that happens, having both questions will not necessarily help with doing a mathematical segmentation. This doesn't mean that they are invalid questions to have listed, though. There could be a lot of business value to knowing that Safety and Technology correlate highly. When you find correlating questions, it is a good idea to discuss with your business users which ones should be removed (if any!).
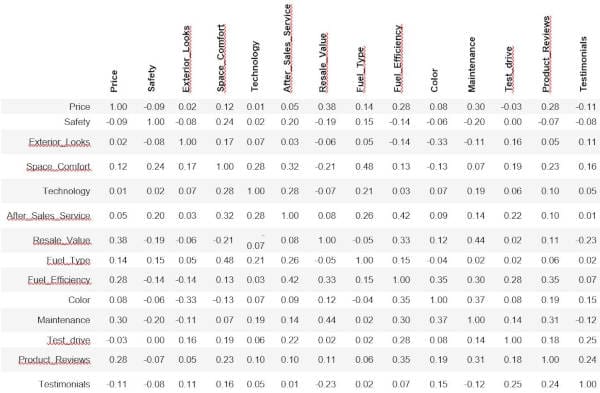
Our raw data output of correlating questions can be seen below (1 = perfect correlation and 0 = no correlation).
In [9]:
df.corr() #data output
Out [9]:
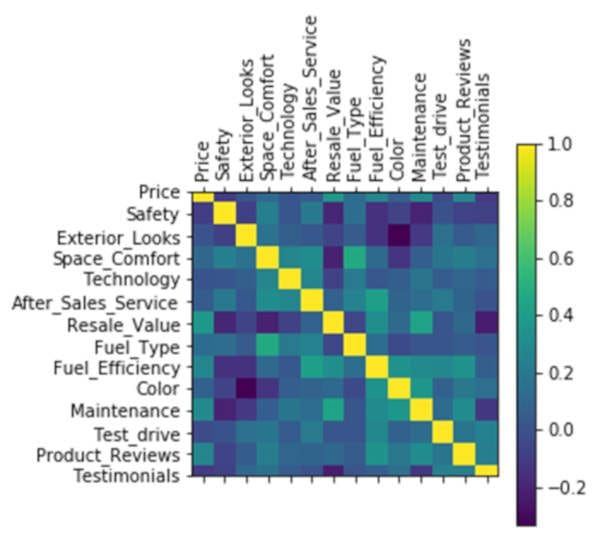
This can also be visually represented in a heat map. In this visualization, darker is good because the questions do not correlate.
In [10]:
plt.matshow(df.corr()) plt.xticks(range(len(df.columns)), df.columns, rotation='vertical') plt.yticks(range(len(df.columns)), df.columns) plt.colorbar() plt.show()
Out [10]:
Using EFA to Create Segments
Now that we have verified there is segmentation happening with the survey results, we can start analyzing how many segments we want. This is where it starts to mix between art and science. Sometimes you want more segments because it is important to include a feature that might not be captured with fewer segments. Other times, the business need might just be "create 4, and only 4 segments because we have 4 flavors of this new food being marketed". Regardless of the situation, we can use EFA to create our segments and verify that the segments are what we want.
Review the Scree Plot
To start the analysis, we need to create a scree plot. To do this, we need to look at the eigenvalues.
In [11]:
fa = FactorAnalyzer(rotation=None, n_factors=len(df.columns)) fa.fit(df) # Check Eigenvalues ev, v = fa.get_eigenvalues() ev
Out [11]:
array([2.75506068, 2.1640701 , 1.46454689, 1.32990296, 1.04029066,
0.99198697, 0.80634535, 0.68102944, 0.60136568, 0.5536899 ,
0.51364695, 0.46653069, 0.35660717, 0.27492656])
Now that we have a list of the eigenvalues, we can map them to our factors.
In [12]:
plt.scatter(range(1,df.shape[1]+1),ev)
plt.plot(range(1,df.shape[1]+1),ev)
plt.title('Scree Plot')
plt.xlabel('Factors')
plt.ylabel('Eigenvalue')
plt.axhline(y=1, color='r', linestyle='--')
plt.grid()
plt.show()
Out [12]:
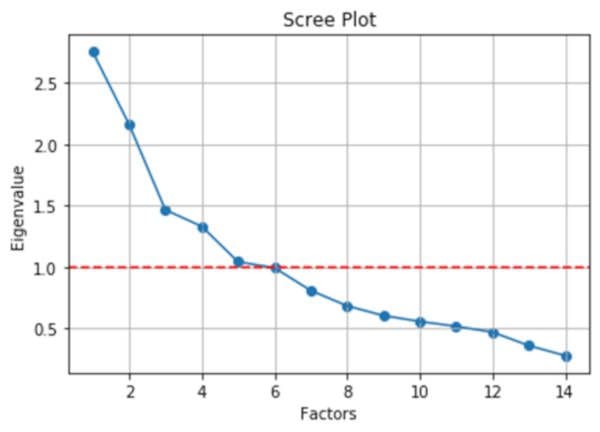
This plot should look very familiar, as we used a similar plot above with the PCA. And just like that previous analysis, we are going to look for the number of factors that are above one to determine how many initial segments we would like to create. In this case, we will be creating 5 segments. Ideally, we would like to map the VSS Complexity and Parallel Analysis lines to give us a range of segments to test out. While this is built into packages in R, with Python, there doesn't seem to be an easy way to do this. So, we will just need to rely on trial and error to do our segmentation.
Create Segments and Review Loadings
Now that we know there are 5 segments for the initial analysis, we can create a new model with those segments and see how each feature is positively or negatively reflected in each segment.
In [13]:
fa = FactorAnalyzer(rotation="varimax", n_factors=5) fa.fit(df) # Check loadings loadings = pd.DataFrame(fa.loadings_) loadings.rename(columns = lambda x: 'Factor-' + str(x + 1), inplace=True) loadings.index = df.columns loadings
Out [13]:
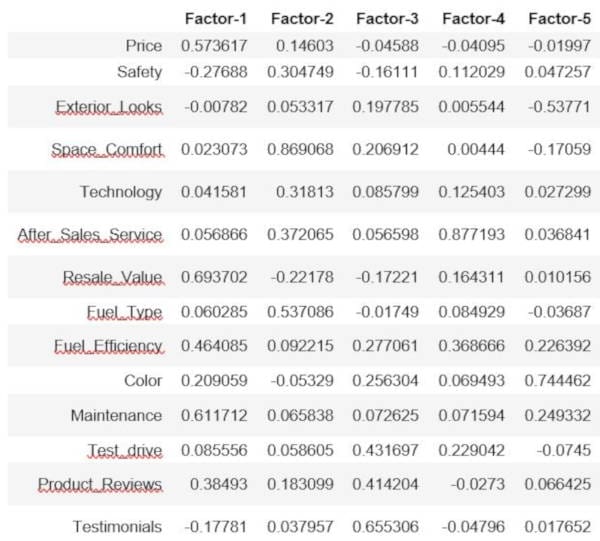
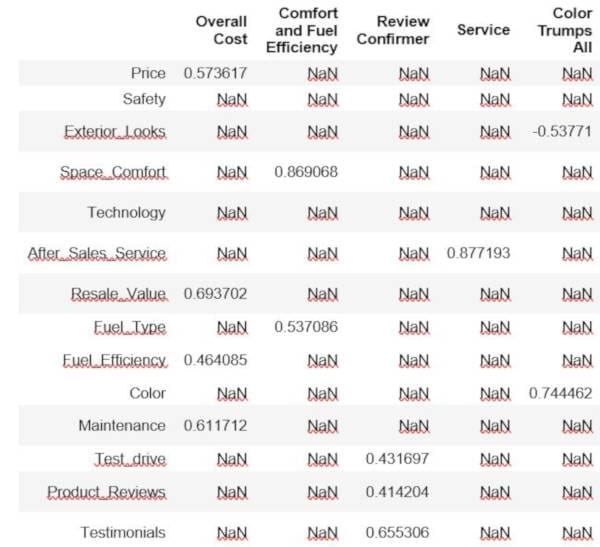
In the above table, each factor can be considered a segment. You might want to combine these for business purposes into super segments, but they do represent distinct populations. When we analyze the segments, it helps to put a limitation on the numbers/relationship strength. For example, if we remove everything that is less than .4 (positively or negatively), we end up with the below table.
In [14]:
segments = loadings[loadings >= .4].fillna(loadings[loadings <= -.4]) segments
Out [14]:

Now we can start naming the segments based on the features that are within each factor. To do this, we just name the columns.
In [15]:
segment_names = ['Overall Cost', 'Comfort and Fuel Efficiency', 'Review Confirmer', 'Service', 'Color Trumps All'] segments.columns = segment_names segments
Out [15]:
Check Variance and Do Adequacy Checks
In [16]:
# Check variance factorVariance = pd.DataFrame(fa.get_factor_variance()) factorVariance.rename(columns = lambda x: 'Factor-' + str(x + 1), inplace=True) factorVariance.index = ['SS Loadings', 'Proportion Variance', 'Cumulative Variance'] factorVariance
Out [16]:
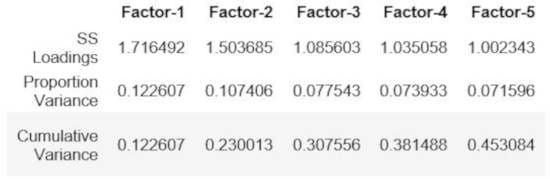
It looks like 5 factors can explain 45% of our variance. We probably want to shoot for something over 50%, so we need to increase the factor count. However, what really matters is the business case involved.
Decision Time
We have validated our survey and come up with some initial segments. There is a catch, though, as our segments didn't use all the survey questions (Safety and Technology were not used). If it is important to find people to sell Safety or Technology features too, then we would need to increase the segments from 5 to 6 and re-run the EFA portion of our analysis. Another requirement might be we can only have 3 segments, so we need to either reduce the factors for the EFA (which would reduce the features used) or combine the 5 segments into 3 segments. Just knowing how to do a mathematically correct segmentation does not necessarily translate into something usable by a business.
Export for Reporting
Once the segments are approved, it is time to prepare the data for exporting. We will apply our segments to the original data, unpivot the correlation matrix, and unpivot the loadings for the report that can be found here: Dashboard
In [17]:
# Data mapped to factors
factor_scores = pd.DataFrame(fa.transform(df))
factor_scores.columns = segment_names
factor_scores['Respondent_ID'] = df.index
df_export = pd.merge(df, factor_scores, on='Respondent_ID')
df_export['Primary Segment'] = df_export[segment_names].idxmax(axis=1)
df_export.to_csv('Data\\Data_Scored.csv', index=False)
# Correlation matrix
correlation_export = df.corr().unstack().reset_index(name='value')
correlation_export.columns = ['Feature 1', 'Feature 2', 'Value']
correlation_export.to_csv('Data\\Correlations.csv', index=False)
# Loadings
loadings.columns = segment_names
loadings_export = loadings.unstack().reset_index(name='value')
loadings_export.columns = ['Segment', 'Feature', 'Value']
loadings_export.to_csv('Data\\Loadings.csv', index=False)
Conclusion
In this tutorial, you learned how to create a segmentation analysis based on Likert survey questions. Hopefully, you feel empowered to generate your own analysis based on new data.
Bio: Jason Wittenauer is a Lead Data Scientist specializing in the healthcare industry, and leads development of new analytics tools that incorporate data science technology in an easy-to-understand format. Jason graduated from Brigham Young University and is a data science developer, researcher, practitioner, and educator with over 12 years of industry experience. He has created many healthcare enabling technologies that include predicting denials, automating rule pattern discovery for care variation, and creating a host of tools to enable healthcare professionals to work more efficiently.
Related: