Customer Segmentation Using K Means Clustering
Customer Segmentation can be a powerful means to identify unsatisfied customer needs. This technique can be used by companies to outperform the competition by developing uniquely appealing products and services.
Customer Segmentation is the subdivision of a market into discrete customer groups that share similar characteristics. Customer Segmentation can be a powerful means to identify unsatisfied customer needs. Using the above data companies can then outperform the competition by developing uniquely appealing products and services.
The most common ways in which businesses segment their customer base are:
- Demographic information, such as gender, age, familial and marital status, income, education, and occupation.
- Geographical information, which differs depending on the scope of the company. For localized businesses, this info might pertain to specific towns or counties. For larger companies, it might mean a customer’s city, state, or even country of residence.
- Psychographics, such as social class, lifestyle, and personality traits.
- Behavioral data, such as spending and consumption habits, product/service usage, and desired benefits.
Advantages of Customer Segmentation
- Determine appropriate product pricing.
- Develop customized marketing campaigns.
- Design an optimal distribution strategy.
- Choose specific product features for deployment.
- Prioritize new product development efforts.
K Means Clustering Algorithm
- Specify number of clusters K.
- Initialize centroids by first shuffling the dataset and then randomly selecting K data points for the centroids without replacement.
- Keep iterating until there is no change to the centroids. i.e assignment of data points to clusters isn’t changing.
The Challenge
You are owing a supermarket mall and through membership cards, you have some basic data about your customers like Customer ID, age, gender, annual income and spending score. You want to understand the customers like who are the target customers so that the sense can be given to marketing team and plan the strategy accordingly.
Data
This project is a part of the Mall Customer Segmentation Data competition held on Kaggle.
The dataset can be downloaded from the kaggle website which can be found here.
Environment and tools
- scikit-learn
- seaborn
- numpy
- pandas
- matplotlib
Where is the code?
Without much ado, let’s get started with the code. The complete project on github can be found here.
I started with loading all the libraries and dependencies. The columns in the dataset are customer id, gender, age, income and spending score.

I dropped the id column as that does not seem relevant to the context. Also I plotted the age frequency of customers.

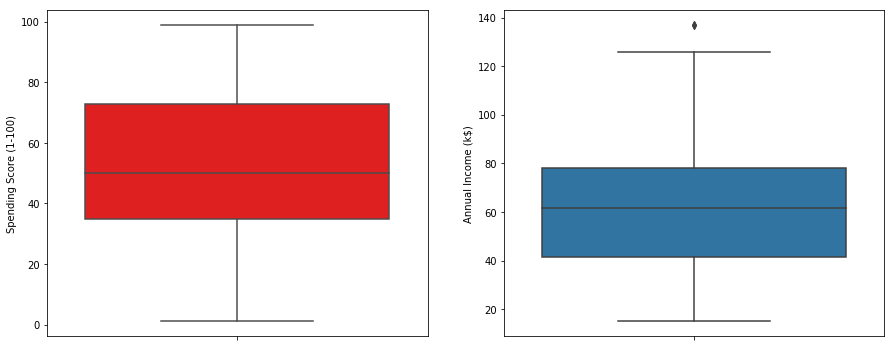
Next I made a box plot of spending score and annual income to better visualize the distribution range. The range of spending score is clearly more than the annual income range.
I made a bar plot to check the distribution of male and female population in the dataset. The female population clearly outweighs the male counterpart.

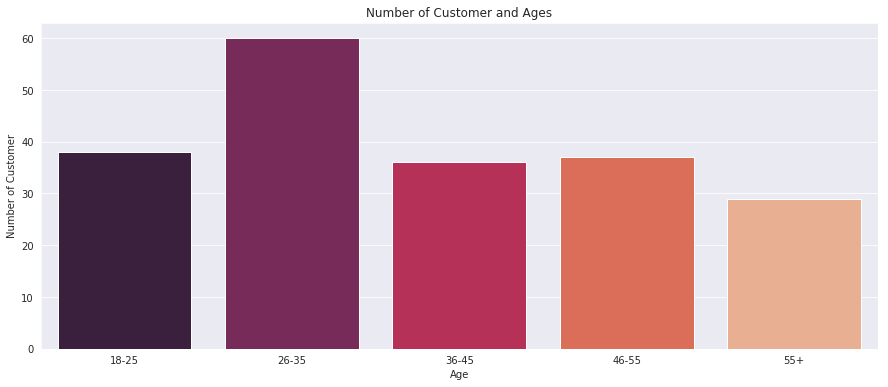
Next I made a bar plot to check the distribution of number of customers in each age group. Clearly the 26–35 age group outweighs every other age group.
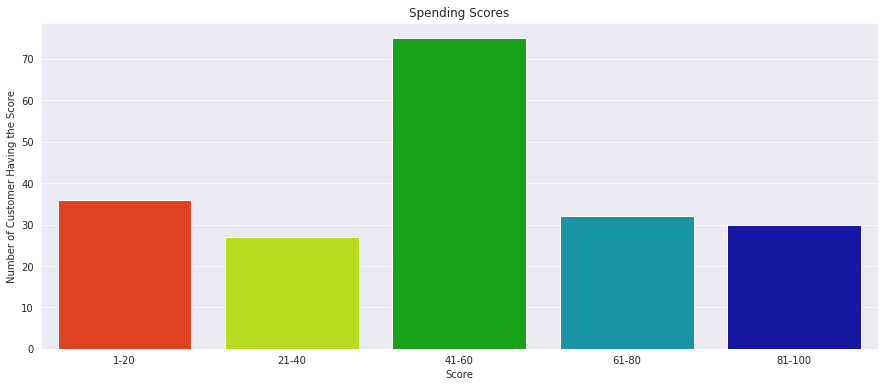
I continued with making a bar plot to visualize the number of customers according to their spending scores. The majority of the customers have spending score in the range 41–60.
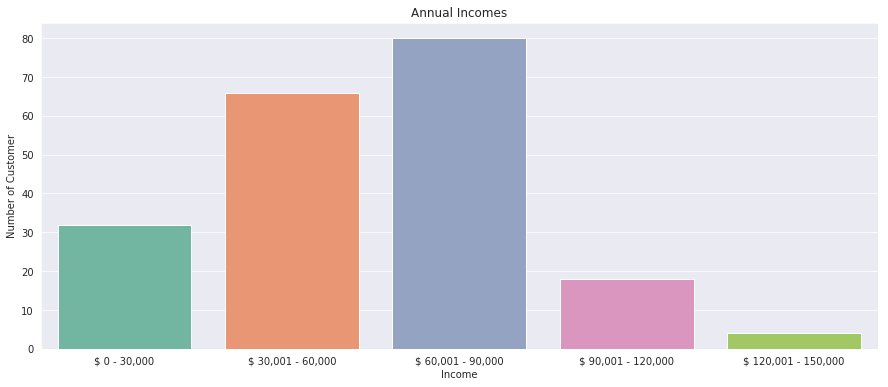
Also I made a bar plot to visualize the number of customers according to their annual income. The majority of the customers have annual income in the range 60000 and 90000.
Next I plotted Within Cluster Sum Of Squares (WCSS) against the the number of clusters (K Value) to figure out the optimal number of clusters value. WCSS measures sum of distances of observations from their cluster centroids which is given by the below formula.
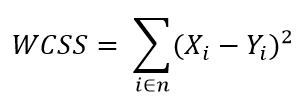
where Yi is centroid for observation Xi. The main goal is to maximize number of clusters and in limiting case each data point becomes its own cluster centroid.

The Elbow Method
Calculate the Within Cluster Sum of Squared Errors (WSS) for different values of k, and choose the k for which WSS first starts to diminish. In the plot of WSS-versus k, this is visible as an elbow.
The optimal K value is found to be 5 using the elbow method.
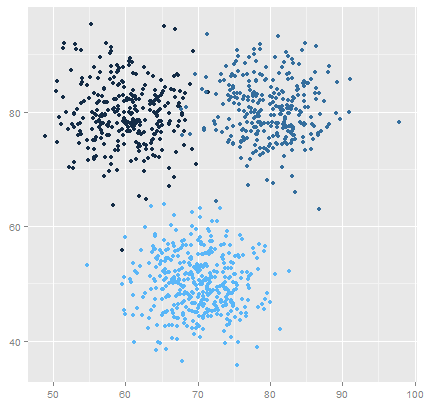
Finally I made a 3D plot to visualize the spending score of the customers with their annual income. The data points are separated into 5 classes which are represented in different colours as shown in the 3D plot.
Results

Conclusions
K means clustering is one of the most popular clustering algorithms and usually the first thing practitioners apply when solving clustering tasks to get an idea of the structure of the dataset. The goal of K means is to group data points into distinct non-overlapping subgroups. One of the major application of K means clustering is segmentation of customers to get a better understanding of them which in turn could be used to increase the revenue of the company.
References/Further Readings
Before You Go
The corresponding source code can be found here.
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium. These are some of my contacts details:
Happy reading, happy learning and happy coding.
Bio: Abhinav Sagar is a senior year undergrad at VIT Vellore. He is interested in data science, machine learning and their applications to real-world problems.
Original. Reposted with permission.
Related:
- Customer Segmentation for R Users
- How to Easily Deploy Machine Learning Models Using Flask
- How to Build Your Own Logistic Regression Model in Python