Complex logic at breakneck speed: Try Julia for data science
We show a comparative performance benchmarking of Julia with an equivalent Python code to show why Julia is great for data science and machine learning.

NOTE: I am building a Github repo with Julia fundamentals and data science examples. Check it out here.
Introduction
“Walks like Python, runs like C” — this has been said about Julia, a modern programming language, focused on scientific computing, and having an ever-increasing base of followers and developers.
Julia, a general-purpose programming language, is made specifically for scientific computing. It is a flexible dynamically-typed language with performance comparable to traditional statically-typed languages.
Julia tries to provide a single environment productive enough for prototyping and efficient for industrial-grade applications. It is a multi-paradigm language encompassing both functional and object-oriented programming components, although the majority of the users like its functional programming aspects.
The inception of this programming language can be traced back to 2009. The lead developers Alan Edelman, Jeff Bezanson, Stefan Karpinski, and Viral Shah started working on creating a language that can be used for better and faster numerical computing. The developers were able to launch a commercial release in February 2012.
Why is it awesome for data science?
Julia is an excellent choice for data science and machine learning work, for much of the same reason, that it is a great choice for fast numerical computing. The advantages include,
- A smooth learning curve, and the extensive underlying functionality. Especially, if you are already familiar with the more popular data science languages like Python and R, picking up Julia will be a walk in the park.
- Performance: Originally, Julia is a compiled language, while Python and R are interpreted. This means that the Julia code is executed on the processor as a direct executable code.
- GPU Support: It is directly related to performance. GPU support is transparently controlled by some packages such as
TensorFlow.jlandMXNet.jl. - Distributed and Parallel Computing Support: Julia supports parallel and distributed computing transparently using many topologies. And there is also support for coroutines, like in Go programming language, which are helper functions that work in parallel on the Multicore architecture. Extensive support for threads and synchronization is primarily designed to maximize performance and reduce the risk of race conditions.
- Rich data science and visualization libraries: Julia community understands that it was conceived as a go-to language for data scientists and statisticians. Therefore, high-performance libraries focusing on data science and analytics are always in development.
- Teamwork (with other languages/frameworks): Julia plays really really well with other established languages and frameworks for data science and machine learning. Using
PyCallorRCallone can use native Python or R code inside a Julia script. ThePlotspackage works with various backend includingMatplotlibandPlotly. Popular machine learning libraries likeScikit-learnorTensorFlowalready have Julia equivalent or wrappers.
Julia is an excellent choice for data science and machine learning work, for much of the same reason, that it is a great choice for fast numerical computing.
Some benchmarking with Python scripting
There is a lot of controversy with regard to the question: “Is Julia faster than Python?”
Like almost anything else in life, the answer is: It depends.
The official Julia language portal has some data about it, although the benchmark tests were done with respect to various languages other than Python.
In fact, the question almost always assumes that one is talking about the comparison between Julia and some kind of optimized/vectorized Python code (like used by Numpy functions). Otherwise, native Julia is almost always faster than Python because of compiled code execution, and native Python is way slower than Numpy-type execution.
Numpy is seriously fast. It is a library with super-optimized functions (many of them pre-compiled), with a dedicated focus of giving Python users (particularly useful for data scientists and ML engineers) near-C speed. Simple Numpy functions like sum or standard deviation can match or beat equivalent Julia implementations closely (particularly for large input array size).
However, to take full advantage of Numpy functions, you have to think in terms of vectorizing your code. And it is not easy at all to write complex logic in a program in the form vectorized code all the time.
Therefore, the speed comparison with Julia should be done for situations where somewhat complex logic is applied to an array for some kind of processing.
In this article, we will show a couple of such examples to illustrate the point.
However, to take full advantage of Numpy functions, you have to think in terms of vectorizing your code
Julia for-loop beats Python for-loop handsomely
Let’s compute the sum of a million random integers to test this out.
Julia code is below. The function takes a little over 1 millisecond.
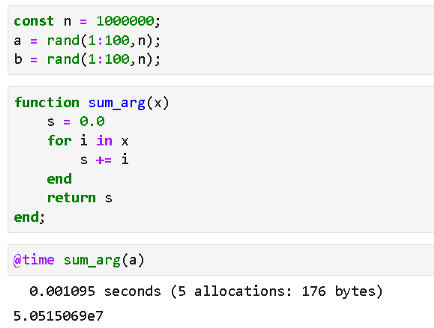
Python code is below. We kept the same functional nature of the code (Julia is a functional language) to keep the comparison fair and easy to verify. The for-loop takes over 200 milliseconds!

But how does a Julia array compare to Numpy array?
In the code above, we created an array variable. This is the most useful data structure in Julia for data science as it can be directly used for statistical computation or linear algebra operations, right out of the box.
No need for a separate library or anything. Julia arrays are order-of-magnitude faster than Python lists.
But, Numpy arrays are fast and let’s benchmark the same summing operation.
Julia code below using the sum() function on the array. It takes ~451 msec (faster than the for-loop approach but only half the time).
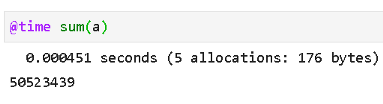
And here is Numpy execution,

Wow! 353 msec which beats the Julia speed and almost 628 times faster than naive Python for-loop code.
So, is the verdict settled in favor of Numpy array?
Not so fast. What if we wanted to sum up only the odd numbers in the array?
No need for a separate library. Julia arrays are order-of-magnitude faster than Python lists.
Here comes the logic
For Julia, the code change will be fairly straightforward. We will just use the for-loop, check if an element of the array is divisible by 2, and if not (odd number), then add it to the running sum. As pedantic as one can get!
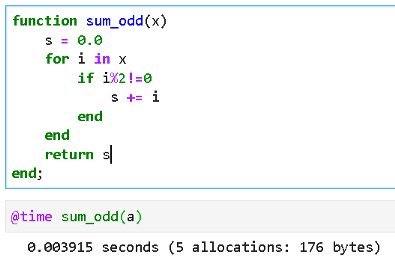
So, that ran in close to 4 milliseconds. Certainly slower than just the blind sum (using the for loop) but not too much (the for-loop plain sum too ~1.1 milliseconds).
Now, we certainly cannot compete with this speed with a Python for-loop! We know how that will turn out, don’t we? So, we have to use a Numpy vectorized code.
But how do we check for odd numbers and only then sum them up in case of a Numpy array? Fortunately, we have the np.where() method.
Here is the Python code. Not that straightforward (unless you know how to use the np.where (correctly), is it?

But look at the speed. Even with a single-line of vectorized code using Numpy method, that took 16.7 milliseconds on average.
Julia code was simpler and ran faster!
Another slightly complicated operation
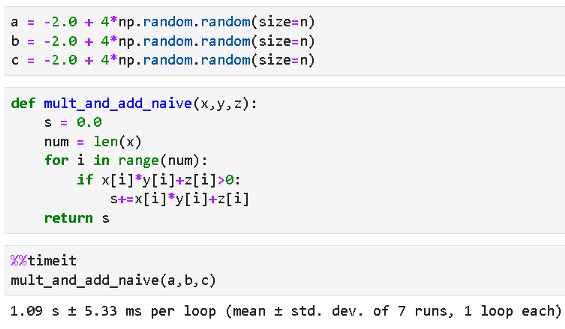
Let’s say we have three arrays (say W, X, and B) with random floating-point numbers ranging from -2 to 2 and we want to compute a special quantity: product of two of these arrays, added to the third i.e. A.X+B but the quantity will be added to the final sum only if the element-wise linear combination exceeds zero.
Does this logic look familiar to you? It is a variation on any densely connected neural network (or even a single perceptron), where the linear combination of weight, feature, and bias vector has to exceed a certain threshold to propagate to the next layer.
So, here is the Julia code. Again, simple and sweet. Took ~1.8 milliseconds. Note, it uses a special function called muladd() which multiplies two numbers and adds to a third.

We tried the Python using a similar code (using for-loop), and the result was terrible, as expected! It took more than a second on average.
Again, we tried to be creative and use a Numpy vectorized code and the result was much better than the for-loop case, but worse than the Julia case ~ 14.9 milliseconds.

So, how does it look like?
At this point, the trend is becoming clear. For numerical operations, where complex logic needs to be checked before some mathematical operation can happen, Julia beats Python (even Numpy) hands down because we can just write the logic in the simplest possible code in Julia and forget it. It will still run at breakneck speed, thanks to the just-in-time (JIT) compiler and internal type-related optimizations (Julia has an extremely elaborate type system to make programs runs fast with correct data types for each variable and optimizing code and memory correspondingly).
Writing the same code using native Python data structures and for-loop is hopelessly slow. Even with a Numpy vectorized code, the speed is slower than that of Julia as the complexity grows.
Numpy is great for the simple methods that an array already comes with such as sum() or mean() or std(), but using logic along with them is not always straightforward and it slows the operation down considerably.
In Julia, there is not much headache of thinking hard to vectorize your code. Even an apparently stupid-looking code, with a plain vanilla for-loop and element-by-element logic checking, runs amazingly fast!
For numerical operations, where complex logic needs to be checked before some mathematical operation can happen, Julia beats Python (even Numpy) hands down because we can just write the logic in the simplest possible code in Julia and forget it.
Summary
In this article, we showed some comparative benchmark of numerical computation between Julia and Python — both native Python code and optimized Numpy functions.
Although in the case of straightforward functions, Numpy is on par with Julia in terms of speed, Julia scores higher when complex logic is introduced in the computing problem. Julia code is inherently simple to write without the need to think hard about vectorizing the functions.
With many ongoing developments in the data science and machine learning support systems, Julia is one of the most exciting new languages to look forward to in the coming days. This is one tool, that budding data scientists should add to their repertoire.
I am building a Github repo with Julia fundamentals and data science examples. Check it out here.
Additional reading
- https://docs.julialang.org/en/v1/manual/performance-tips/#man-performance-tips-1
- https://agilescientific.com/blog/2014/9/4/julia-in-a-nutshell.html
- https://en.wikibooks.org/wiki/Introducing_Julia/Types
- https://dev.to/epogrebnyak/julialang-and-surprises---what-im-learning-with-a-new-programming-language--21df
If you have any questions or ideas to share, please contact the author at tirthajyoti[AT]gmail.com. Also, you can check the author’s GitHub repositories for code, ideas, and resources in machine learning and data science. If you are, like me, passionate about AI/machine learning/data science, please feel free to add me on LinkedIn or follow me on Twitter.
Bio: Tirthajyoti Sarkar is Sr Principal Engineer at ON Semiconductor.
Original. Reposted with permission.
Related:
- The Guerrilla Guide to Machine Learning with Julia
- The Whole Data Science World in Your Hands
- Introducing Gen: MIT’s New Language That Wants to be the TensorFlow of Programmable Inference