 Five Cognitive Biases In Data Science (And how to avoid them)
Five Cognitive Biases In Data Science (And how to avoid them)
 Five Cognitive Biases In Data Science (And how to avoid them)
Five Cognitive Biases In Data Science (And how to avoid them)Everyone is prey to cognitive biases that skew thinking, but data scientists must prevent them from spoiling their work. Learn more about five biases that can all too easily make your seemingly objective work become surprisingly subjective.

Retrain your mind. Image by John Hain from Pixabay.
Recently, I was reading Rolf Dobell’s The Art of Thinking Clearly, which made me think about cognitive biases in a way I never had before. I realized how deeply seated some cognitive biases are. In fact, we often don’t even consciously realize when our thinking is being affected by one. For data scientists, these biases can really change the way we work with data and make our day-to-day decisions, and generally not for the better.
Data science is, despite the seeming objectivity of all the facts we work with, surprisingly subjective in its processes.
As data scientists, our job is to make sense of the facts. In carrying out this analysis, we have to make subjective decisions, though. So even though we work with hard facts and data, there’s a strong interpretive component to data science.
As a result, we data scientists need to be extremely careful, because all humans are very much susceptible to cognitive biases. We’re no exception. In fact, I have seen many instances where data scientists ended up making decisions based on pre-existing beliefs, limited data or just irrational preferences.
In this piece, I want to point out five of the most common types of cognitive biases. I also offer some suggestions on how data scientists can work to avoid them and make better, more reasoned decisions.
1. Survivorship Bias

During World War II, researchers from the non-profit research group the Center for Naval Analyses were tasked with a problem. They needed to reinforce the military’s fighter planes at their weakest spots. To accomplish this, they turned to data. They examined every plane that came back from a combat mission and made a note of where bullets had hit the aircraft. Based on that information, they recommended that the planes be reinforced at those precise spots.
Do you see any problems with this approach?
The problem, of course, was that they only looked at the planes that returned and not at the planes that didn’t. Of course, data from the planes that had been shot down would almost certainly have been much more useful in determining where fatal damage to a plane was likely to have occurred, as those were the ones that suffered catastrophic damage.
The research team suffered from survivorship bias: they just looked at the data that was available to them without analyzing the larger situation. This is a form of selection bias in which we implicitly filter data based on some arbitrary criteria and then try to make sense out of it without realizing or acknowledging that we’re working with incomplete data.
Let’s think about how this might apply to our work in data science. Say you begin working on a data set. You have created your features and reached a decent accuracy on your modelling task. But maybe you should ask yourself if that is the best result you can achieve. Have you tried looking for more data? Maybe adding weather forecast data to the regular sales variables that you use in your ARIMA models would help you to forecast your sales better. Or perhaps some features around holidays can tell your model why your buyers are behaving in a particular fashion around Thanksgiving or Christmas.
Recommendation to Overcome: One way to mitigate this bias is by thinking in a rigorous, scientific way about the problem at hand and then brainstorming about any type of data that could help solve it (rather than just starting with the data). These approaches may seem similar, but the second method restricts your vision because you don’t know what’s missing from your work. By using the first approach, you will know what data you were not able to get, and you will end up factoring that into your conclusions.
2. Sunk Cost Fallacy

Source: Pixabay.
We all have seen the sunk cost fallacy in action at some point, whether it be sitting through that bad movie because we have already paid for it or finishing that awful book because we were already halfway through. Everyone has been in a situation where they ended up wasting more time because they were trying to salvage the time they had already invested.
A sunk cost, also known as a retrospective cost, is one that has already been incurred and cannot be recovered by any additional action. The sunk cost fallacy refers to the tendency of human beings to make decisions based on how much of an investment they have already made, which leads to even more investment but no returns whatsoever.
Sometimes, hard as it is, the best thing to do is to let go.
This often happens with data science projects. A project might run for more than two years without results, but an investigator continues running it because so much time, money and effort have already been invested. Or a data scientist might defend her project wholeheartedly because she has invested so much in it, failing to realize that putting in more work won’t help her or the company in the long run and that it is best if the project is scrapped.
Recommendation to Overcome: A way to save yourself from this cognitive bias is by focusing on future benefits and costs rather than the already lost past costs. You have to develop the habit, hard as it is, of ignoring the previous cost information. Of course, it is never easy for us data scientists to just disregard data. For myself, I have found that a methodical way works best in this case. I take a pen and paper to get away from all the distractions and try to come up with all the additional costs required to do a project along with the benefits I might get in the future. If the cost part of the task seems overly significant, then it is time to move on.
3. False Causality
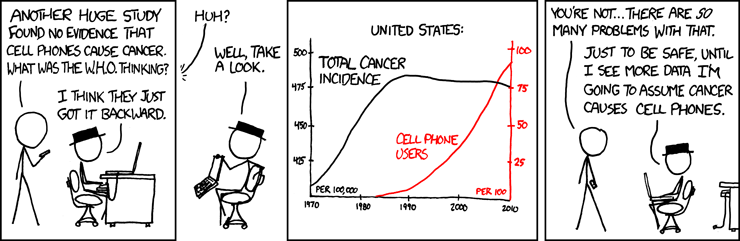
As data scientists, we are always in search of patterns. The tendency means that sometimes we even find patterns where none really even exist. Our brains are so trained in this way that we will even make sense of chaos to the extent that we can.
Because our training wires us to seek out patterns, it’s crucial to remember the simple maxim that correlation does not imply causation. Those five words are like the hammer of the data science toolbox without which you can’t accomplish anything. Just because two variables move in tandem doesn’t necessarily mean that one causes the other.
This principle has been hilariously demonstrated by numerous examples. For instance,
- By looking at fire department data, you notice that, as more firefighters are dispatched to a fire, the more damage is ultimately done to a property. Thus, you might infer that more firefighters are causing more damage.
- In another famous example, an academic who was investigating the cause of crime in New York City in the 1980s found a strong correlation between the number of serious crimes committed and the amount of ice cream sold by street vendors.But should we conclude that eating ice cream drives people to crime? Since this makes little sense, we should obviously suspect that there was an unobserved variable causing both. During the summer, crime rates are the highest, and this is also when most ice cream is sold. Ice cream sales don’t cause crime, nor does crime increase ice cream sales.
In both of these instances, looking at the data too superficially leads to incorrect assumptions.
Recommendation to Overcome: As data scientists, we need to be mindful of this bias when we present findings. Often, variables that might seem causal might not be on closer inspection. We should also take special care to avoid this type of mistake when creating variables of our models. At each step of the process, it’s important to ask ourselves if our independent variable is possibly just correlated to the dependent variable.
4. Availability Bias
Have you ever said something like, “I know that [insert a generic statement here] because [insert one single example].” For example, someone might say, “You can’t get fat from drinking beer, because Bob drinks a lot of it, and he’s thin.” If you have, then you’ve suffered from availability bias. You are trying to make sense of the world with limited data.
People naturally tend to base decisions on information that is already available to us or things we hear about often without looking at alternatives that might be useful. As a result, we limit ourselves to a very specific subset of information.
This often happens in the data science world. Data scientists tend to get and work on data that’s easier to obtain rather than looking for data that is harder to gather but might be more useful. We make do with models that we understand and that are available to us in a neat package rather than something more suitable for the problem at hand but much more difficult to come by.
Recommendation to Overcome: A way to overcome availability bias in data science is to broaden our horizons. Commit to lifelong learning. Read. A lot. About everything. Then read some more. Meet new people. Discuss your work with other data scientists at work or in online forums. Be more open to suggestions about changes that you may have to take in your approach. By opening yourself up to new information and ideas, you can make sure that you’re less likely to work with incomplete information.
5. Confirmation Bias
An old joke says that if you torture the data long enough, it will confess. With enough work, you can distort data to make it say what you want it to say.
We all hold some beliefs, and that’s fine. It’s all part of being human. What’s not OK, though, is when we let those beliefs inadvertently come into the way we form our hypotheses.
We can see this tendency in our everyday lives. We often interpret new information in such a way that it becomes compatible with our own beliefs. We read the news on the site that conforms most closely to our beliefs. We talk to people who are like us and hold similar views. We don’t want to get disconcerting evidence because that might lead us to change our worldview, which we might be afraid to do.
For example, I have seen confirmation bias in action in data science during the cost-benefit analysis stage of a project. I’ve seen people clinging to the data that confirms their hypothesis while ignoring all the contradictory evidence. Obviously, doing this could have a negative impact on the benefits section of the project.
Recommendation to Overcome: One way to fight this bias is to critically examine all your beliefs and try to find disconcerting evidence about each of your theories. By that, I mean actively seeking out evidence by going to places where you don’t normally go, talking to people you don’t normally talk to, and generally keeping an open mind.
Conclusion
In our age of information overload, we are surrounded by so much data that our brains try desperately to make sense of the noise.
Sometimes it is useful to be able to make some sense out of the world based on limited information. In fact, we make most of our decisions without thinking much, going with our gut feelings. The potential harm of most of our day-to-day actions is pretty small. Allowing our biases to influence our work, though, can leave us in an unfortunate situation. We may end up losing money or credibility if we make a vital decision that turns out to be wrong.
Knowing how our brain works will help us avoid these mistakes.
Original. Reposted with permission.
Related: