 Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning
Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning
 Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning
Uber’s Ludwig is an Open Source Framework for Low-Code Machine LearningThe new framework allow developers with minimum experience to create and train machine learning models.

Training and testing deep learning models is a difficult process that requires sophisticated knowledge of machine learning and data infrastructures. From feature modeling to hyperparameter optimization, the processes for training and testing deep learning models are one of the biggest bottlenecks in data science solutions in the real world. Simplifying this element could help to streamline the adoption of deep learning technologies. While the low-code training of deep learning models is a nascent space, we are already seeing relevant innovations. One of the most complete solutions to tackle that problem came from Uber AI Labs. Ludwig, is a framework for training and testing machine learning models without the need to write code. Recently, Uber released a second version of Ludwig that includes major enhancements in order to enable mainstream no-code experiences for machine learning developers.
The goal of Ludwig is to simplify the processes of training and testing machine learning models using a declarative, no-code experience. Training is one of the most developer intensive aspects of deep learning applications. Typically, data scientists spend numerous hours experimenting with different deep learning models to better perform about a specific training datasets. This process involves more than just training including several other aspects such as model comparison, evaluation, workload distribution and many others. Given its highly technical nature, the training of deep learning models is an activity typically constrained to data scientists and machine learning experts and includes a significant volume of code. While this problem can be generalized for any machine learning solution it has gotten way worse in deep learning architectures as they typically involve many layers and levels. Ludwig’s abstracts the complexity of training and testing machine learning programs using declarative models that are easy to modify and version.
Ludwig
Functionally, Ludwig is a framework for simplifying the processes of selecting, training and evaluating machine learning models for a given scenario. Ludwig provides a set of model architectures that can be combined together to create an end-to-end model optimized for a specific set of requirements. Conceptually, Ludwig was designed based on a series of principles:
- No Coding Required: Ludwig enables the training of models without requiring any machine learning expertise.
- Generality: Ludwig can be used across many different machine learning scenarios.
- Flexibility: Ludwig is flexible enough to be used by experienced machine learning practitioners as well as by non-experienced developers.
- Extensibility: Ludwig was designed with extensibility in mind. Every new version has included new capabilities without changing the core model.
- Interpretability: Ludwig includes visualizations that help data scientists understand the performance of machine learning models.
Using Ludwig, a data scientist can train a deep learning model by simply providing a CSV file that contains the training data as well as a YAML file with the inputs and outputs of the model. Using those two data points, Ludwig performs a multi-task learning routine to predict all outputs simultaneously and evaluate the results. This simple structure is key to enable rapid prototyping. Under the covers, Ludwig provides a series of deep learning models that are constantly evaluated and can be combined in a final architecture.
The main innovation behind Ludwig is based on the idea of data-type specific encoders and decoders. Ludwig uses specific encoders and decoders for any given data type supported. Like in other deep learning architectures, encoders are responsible for mapping raw data to tensors while decoders map tensors to outputs. The architecture of Ludwig also includes the concept of a combiner which is a component that combine the tensors from all input encoders, process them, and return the tensors to be used for the output decoders.
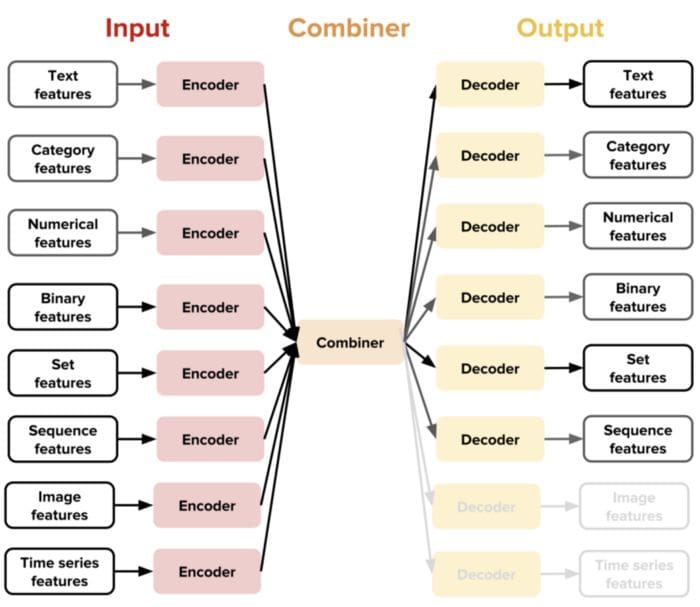
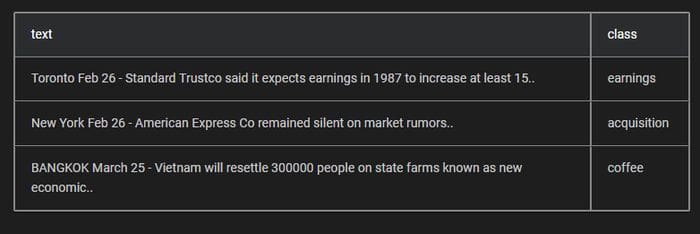
Data scientists will use Ludwig for two main functionalities: training and predictions. Suppose that we are working on a text classification scenario with the following dataset.
We can get started with Ludwig by installing it using the following command:
pip install ludwig
python -m spacy download enThe next step would be to configure a model definition YAML file that specifies the input and output features of the model.
input_features:
-
name: text
type: text
encoder: parallel_cnn
level: wordoutput_features:
-
name: class
type: categoryWith those two inputs(training data and YAML configuration), we can train a deep learning model using the following command:
ludwig experiment \
--data_csv reuters-allcats.csv \
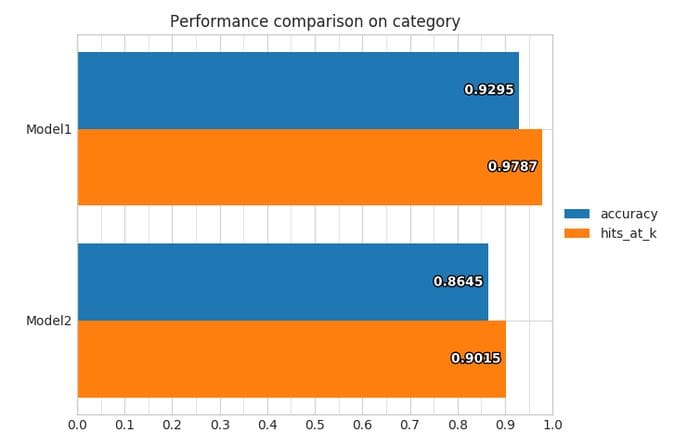
--model_definition_file model_definition.yamlLudwig provides a series of visualizations that can be used during training and predictions. For instance, the learning curve visualization give us an idea of the training and testing performance of the model.

After training we can evaluate the predictions of the model using the following command:
ludwig predict --data_csv path/to/data.csv --model_path /path/to/modelOther visualizations can be used to evaluate the performance of the model.
New Additions to Ludwig
Recently, Uber released a second version of Ludwig expands its core architectures with a series of new features designed to improve the no-code experience to training and testing models. A lot of the new Ludwig features are based on integration with other machine learning stacks or frameworks. Here are some of the key features:
- Comet.ml Integration: Comet.ml is one of the most popular platforms in the market for hyperparameter optimization and machine learning experimentation. Ludwig’s new integration with Comet.ml enables capabilities such as hyperparameter analysis or live performance evaluation which are essential parts of a the data scientist toolbox.
- Model Serving: Model serving is a key component of the lifecycle of machine learning programs. The new version of Ludwig provides an API endpoint to serve trained models and query predictions using simple REST queries.
- Audio/Speech Features: One of the most important additions of Ludwig 0.2 is the support for audio features. This allow data scientists to build audio analysis models with minimum code.
- BERT Encoder: BERT is one of the most popular language models in the history of deep learning. Based on a Transformer architecture, BERT can perform a number of language tasks such as question-answering or text generation. Ludwig now supports BERT as a native building block for text classification scenarios.
- H3 Features: H3 is a very popular spatial index that is used to encode location into 64-bit integers. Ludwig 0.2 natively supports H3 allowing the implementation of machine learning models using spatial datasets.
Other additions to Ludwig include improvement in the visualization APIs, new date features, better support for non-English languages for text tokenization as well as better data pre-processing capabilities. Data injection in particular seems to be a key area of focus for the next version of Ludwig.
Ludwig remains relatively new framework that still needs a lot of improvements. However, its support for low-code models is a key building block to streamline the adoption of machine learning across a wider class of developers. Furthermore, Ludwig abstracts and simplifies the usage of some of the topn machine learning frameworks in the market.
Original. Reposted with permission.
Related:
- LinkedIn Open Sources a Small Component to Simplify the TensorFlow-Spark Interoperability
- Facebook Open Sources Blender, the Largest-Ever Open Domain Chatbot
- Microsoft Research Unveils Three Efforts to Advance Deep Generative Models