Simplified Mixed Feature Type Preprocessing in Scikit-Learn with Pipelines
There is a quick and easy way to perform preprocessing on mixed feature type data in Scikit-Learn, which can be integrated into your machine learning pipelines.
Let's say we want to perform mixed feature type preprocessing in Python. For our purposes, let's say this includes:
- scaling of numeric values
- transforming of categorical values to one-hot encoded
- imputing all missing values
Let's further say that we want this to be as painless, automated, and integrated into our machine learning workflow as possible.
In a Python machine learning ecosystem, previously this could have been accomplished with a mix of directly manipulating Pandas DataFrames and/or using Numpy ndarray operations, perhaps alongside some Scikit-learn modules, depending on one's preferences. While these would still be perfectly acceptable approaches, this can now also all be done in Scikit-learn alone. With this approach, it can be almost fully automated, and it can be integrated into a Scikit-learn pipeline for seamless implementation and easier reproducibility.
So let's see how we can use Scikit-learn to accomplish all of the above with ease.
First, the imports of everything we will need throughout:
from sklearn.datasets import fetch_openml from sklearn.impute import SimpleImputer from sklearn.preprocessing import StandardScaler, OneHotEncoder from sklearn.compose import ColumnTransformer from sklearn.pipeline import Pipeline from sklearn.compose import make_column_selector as selector
For demonstration purposes, let's use the Titanic dataset. I know, I know... boring. But it has a mix of numeric and categorical variables, it is easy to understand, and most people have some familiarity with it. So let's fetch the data, read it in, and have a quick look at it to understand how our feature preprocessing relates to our specific data.
# Fetch Titanic dataset titanic = fetch_openml('titanic', version=1, as_frame=True) X = titanic.frame.drop('survived', axis=1) y = titanic.frame['survived']
Let's see the feature data types, as a refresher.
X.dtypes
name object address float64 sex category age float64 sibsp float64 parch float64 ticket object fare float64 cabin object embarked category boat object body float64 home.dest object dtype: object
Note the numeric and non-numeric feature types. We will perform our preprocessing on these different types seamlessly and in a somewhat automated manner.
Introduced in version 0.20, the ColumnTransformer is meant to apply Scikit-learn transformers to a single dataset column, be that column housed in a Numpy array or Pandas DataFrame.
This estimator allows different columns or column subsets of the input to be transformed separately and the features generated by each transformer will be concatenated to form a single feature space. This is useful for heterogeneous or columnar data, to combine several feature extraction mechanisms or transformations into a single transformer.
This means that you are able to apply individual transformers to individual columns. This could mean that, specific to the Titanic dataset, perhaps we would like to scale numeric columns and one-hot encode categorical columns. It might also make sense to fill missing numeric values with its column's median value and fill in categorical missing values with a constant immediately prior to our feature scaling and encoding.
To do this, let's crate a pair of Pipeline objects, one each for the numeric and categorical transformations described.
# Scale numeric values num_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='median')), ('scaler', StandardScaler())]) # One-hot encode categorical values cat_transformer = Pipeline(steps=[ ('imputer', SimpleImputer(strategy='constant', fill_value='missing')), ('onehot', OneHotEncoder(handle_unknown='ignore'))])
Now let's add these transformers to a ColumnTransfer object. We could either specify which columns to apply these transformations to specifically, or we could use a column selector to automate this process. Note the line
from sklearn.compose import make_column_selector as selector
from the imports above. In the code below, we are creating a num_transformer and a cat_transformer and directing them to be applied to all columns of type float64 all columns of type category, respectively.
preprocessor = ColumnTransformer( transformers=[ ('num', num_transformer, selector(dtype_include='float64')), ('cat', cat_transformer, selector(dtype_include='category'))])
If you want this added into a more complete machine learning pipeline which includes a classifier, try something like this:
clf = Pipeline(steps=[ ('preprocessor', preprocessor), ('classifier', LogisticRegression())])
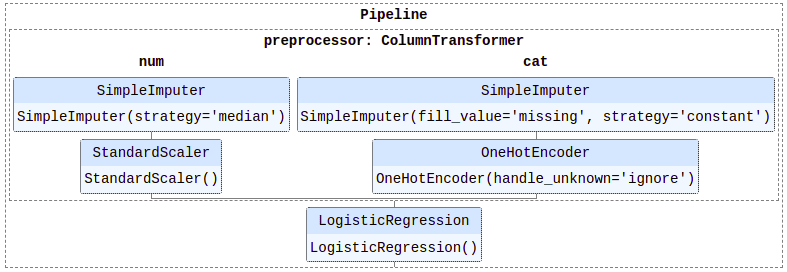
And off you go. Automated preprocessing in the form of feature scaling, one-hot encoding, and missing value imputation as part of your Scikit-learn pipeline with minimal effort. I leave the actual transformations and training of the classifier (the pipeline execution, if you will) as an exercise for the reader.
Aside from the easier reproducibility, automated application of preprocessing to training and subsequently testing data in the proper manner, and pipeline integration, this approach also allows for easy preprocessing tweaking and modification without having to redo earlier sections of a task outright.
This won't negate the necessity for thoughtful feature selection, extraction, and engineering, but the combination of column transformers and column selectors can help easily automate some of the more mundane aspects of your data preprocessing tasks.
You can find more here on the Scikit-learn website.
Related:
- Notes on Feature Preprocessing: The What, the Why, and the How
- Dataset Splitting Best Practices in Python
- Centroid Initialization Methods for k-means Clustering