A Complete Guide To Survival Analysis In Python, part 2
Continuing with the second of this three-part series covering a step-by-step review of statistical survival analysis, we look at a detailed example implementing the Kaplan-Meier fitter theory as well as the Nelson-Aalen fitter theory, both with examples and shared code.
By Pratik Shukla, Aspiring machine learning engineer.
In the first article of this three-part series, we saw the basics of the Kaplan-Meier Estimator. Now, it’s time to implement the theory we discussed in the first part.
Example 1: Kaplan-Meier Estimator (Without any groups)
Let’s code:
(1) Import required libraries:
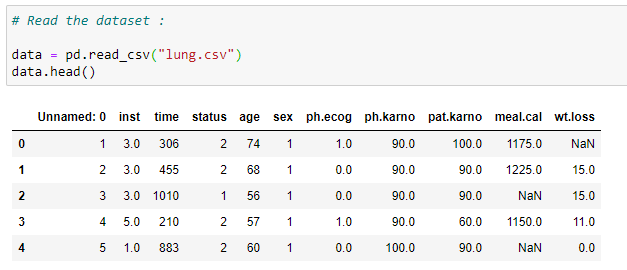
(2) Read the dataset:
(3) Columns of our dataset:
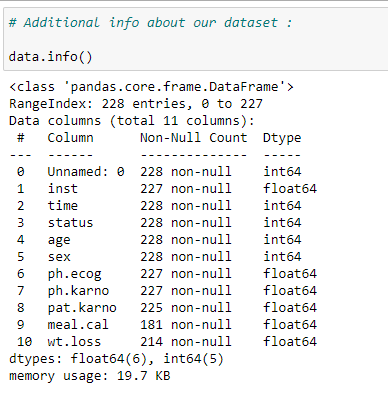
(4) Additional info about dataset:
It gives us information about the data types and the number of rows in each column that has null values. It’s very important for us to remove the rows with a null value for some of the methods in survival analysis.
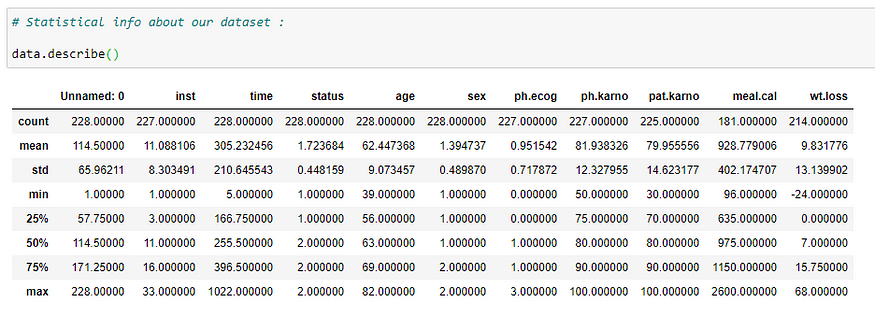
(5) Statistical info about dataset:
It gives us some statistical information like the total number of rows, mean, standard deviation, minimum value, 25th percentile, 50th percentile, 75th percentile, and maximum value for each column in our dataset.
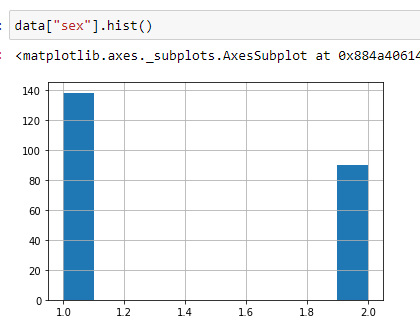
(6) Find out sex distribution using histogram:
This gives us a general idea about how our data is distributed. In the following graph, you can see that around 139 values have a status of 1, and around 90 values have a status of 2. It means that in our dataset, there are 139 males and around 90 females.
(7) Create an object for KaplanMeierFitter:
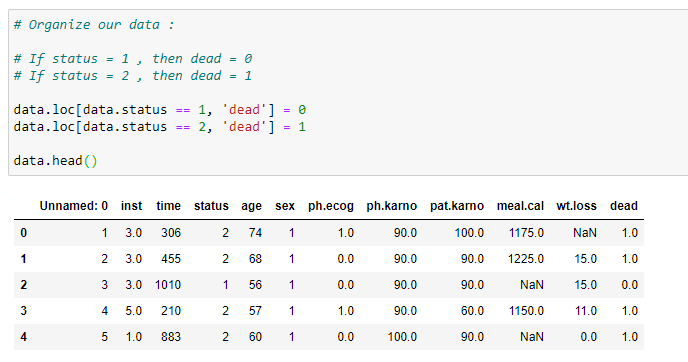
(8) Organize the data:
Now we need to organize our data. We’ll add a new column in our dataset that is called “dead”. It stores the data about whether a person that is a part of our experiment is dead or alive (based on the status value). If our status value is 1 then that person is alive, and if our status value is 2 then the person is dead. It’s a very crucial step for what we need to do in the next step. As we are going to store our data in columns called censored and observed. Where observed data stores the value of dead persons in a specific timeline and censored data stores the value of alive persons or persons that we’re not going to investigate at that timeline.
(9) Fitting our data into object:
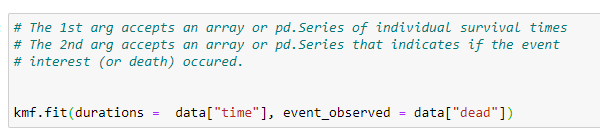
Here our goal is to find the number of days a patient survived before they died. So our event of interest will be “death”, which is stored in the “dead” column. The first argument it takes is the timeline for our experiment.
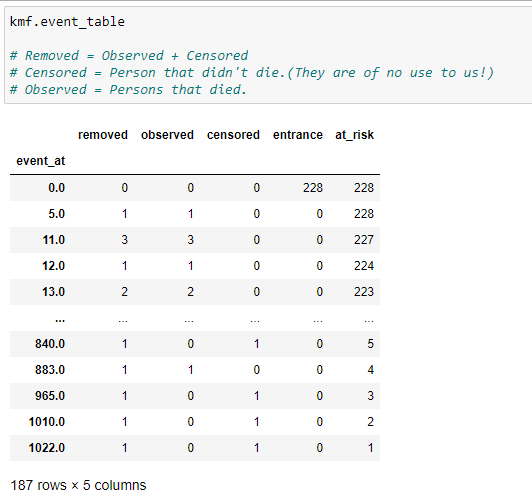
(10) Event table :
One most important method of kmf object is “event_table”. It gives us various information for our data fitted. Let’s have a look at it column-by-column.
(1) Event_at: It stores the value of the timeline for our dataset, i.e., when was the patient observed in our experiment or when was the experiment conducted. It can be the number of minutes, days, months, years etc. In our case, it’s going to be the number of days. It basically stores the value of survival days for a patient.
(2) At_risk: It stores the number of current patients. At the start, it will be the total number of patients we are going to observe in our experiment. If at a certain time, new patients are added, then we have to increase it’s value accordingly. Basically, we can say that:
at_risk = current patients at_risk + entrance — removed
(3) Entrance: It stores the value of new patients in a given timeline. It’ possible that while we have other patients, some new patients are also diagnosed with cancer. That’s why we add it here.
(4) Censored: Our ultimate goal is to find the survival probability for a patient. If at a specific timeline person under experiment is alive, then that person goes into the censored category. If we don’t have information about when a patient died, then we add it to the censored data. Other possibilities are if a patient chooses to shift to another town where the experiment can’t be conducted, then we add that patient into the censored category.
(5) Observed: The number of patients that died during the experiment.
(6) Removed: It stores the values of patients that are no longer part of our experiment. If a person died or is censored, then they fall into this category. In short,
Removed = Observed + Censored
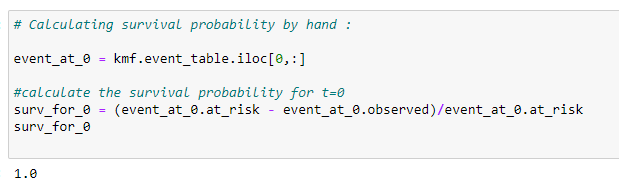
(11) Calculating the probability of survival for individual timelines:
Here we are going to use the following formula to count it by hand:
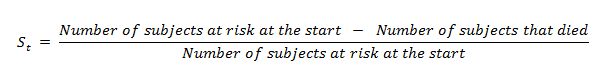
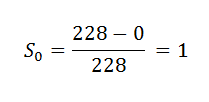
(12) Event_At_5:
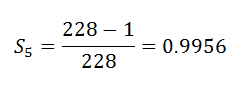

(13) Event_At_11:
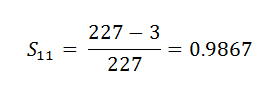

Now what we found here is the probability for a certain period of time only. What we want is the probability for the entire time period for a patient, i.e., the probability of the patient surviving all the rounds of experiment.
This seems confusing, right?
Let’s take a very simple example to understand the concept of conditional probability.
Let’ say we have a total of 15 balls in a non-transparent box. Out of the 15 balls, we have 7 black balls, 5 red balls, and 3 green balls. Here’s a pictorial view for that.

Now let’s find some probabilities!
Probability for choosing a red ball :
Notice that we have a total of 5 red balls out of 15 balls.
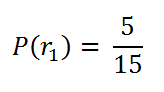
probability of choosing 2nd red ball:
Since we’ve removed a ball that was red, the total number of red balls we have is 4, and the total number of balls we have is 14.
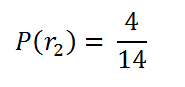
Now what my point here is: What if we want to find the probability of both the balls selected to be red. This is our case here. Like we want to find the probability that we know that a patient has survived the 1st time interval, and we want to find the probability of them surviving the 2nd time interval given that they have survived the 1st time interval. My point here is we just don’t want to find the probability of the 2nd time interval only. We want the total probability of them surviving the time period.
In the case of the balls, we want to find out what’s the probability that both of the selected balls are red?
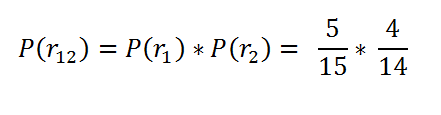
Probability of both red balls.
Here our goal is to find the probability for the entire timeline of that person. Like they survived the 1st, 2nd, and 3rd timeslines, then our survival probability will be:
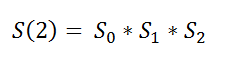
Getting back to our main example:
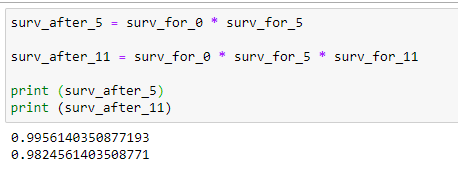
(14) Surv_After_probability:
We want to find the probability that a patient has survived through all the timeline till now. Now we need to find the actual survival probability for a patient.
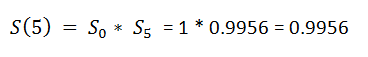
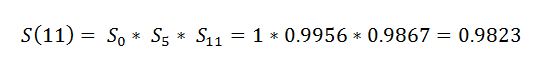
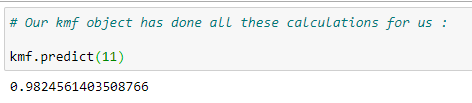
(15) Predict function:
Now the kmf object’s predict function does all of this work for us. But it’s always good to know the logic behind it.
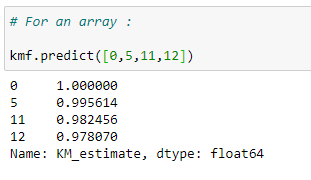
(16) Finding survival probability for an array of the timeline:
We can find the probability for an array of time.
(17) Get survival probability for the whole timeline:
The kmf object’s survival_function_ gives us the complete data for our timeline.
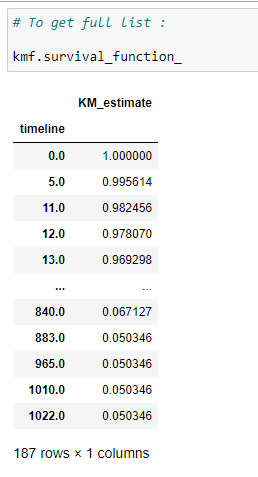
Explanation:
The survival probability for a patient at timeline 0 is 1. If you think it over, then you can understand that the probability that a person dies on the 1st day of diagnosis is nearly equal to 0. So we can say that the survival probability is as high as possible. As the timeline increases, the probability of survival decreases for a patient.
(18) Median:
It provides the number of days where on average, 50% of patients survived.

From the above code, we can say that, on average, a person lives 310 days after the day of diagnosis.
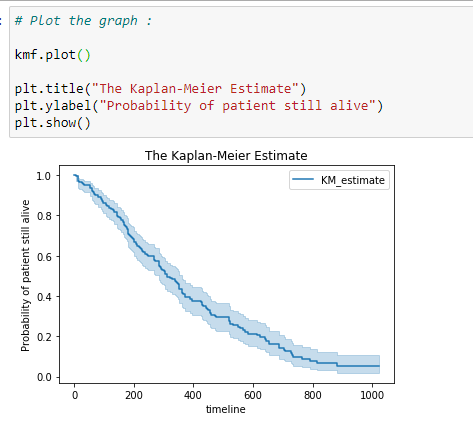
(19) Plot the graph:
Here we can plot the graph for survival probability.
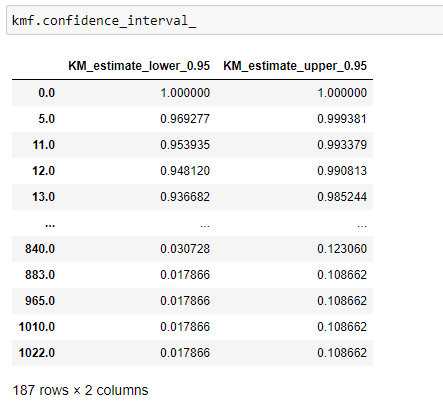
(20) Confidence interval:
The confidence interval gives us the range of values we are fairly sure our true values lie in. Here you can see in the above graph the light blue color shade represents the confidence interval of survival. From that, we can say that the probability at that timeline certainly lies between that confidence interval only.
Now all the information we have is for the survival of a person. Now we are going to see what is the probability for a person to die at a certain timeline. Here notice that a higher survival probability is good for a person, but higher cumulative density (probability of a person to die) is not so good!
(21) Probability of a person to die:
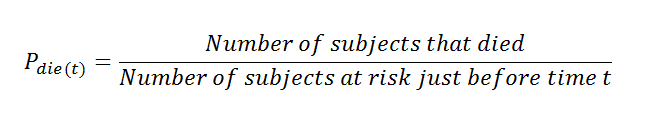
Here notice that the denominator value is the subjects at risk just before time (t). In a simple way, we can say that the person at_risk of the previous row.
The formula for cumulative density:
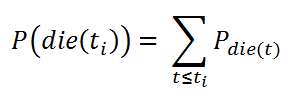
Cumulative Density.
Calculate the probability by hand:
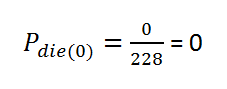
t = 0
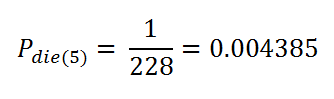
t = 5
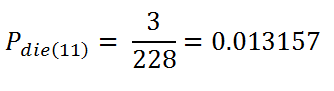
t = 11
Find the cumulative density:
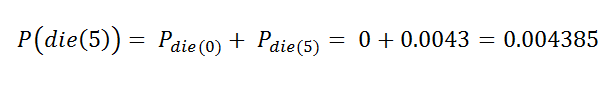
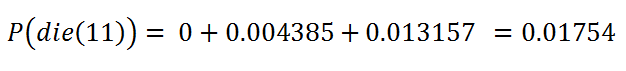
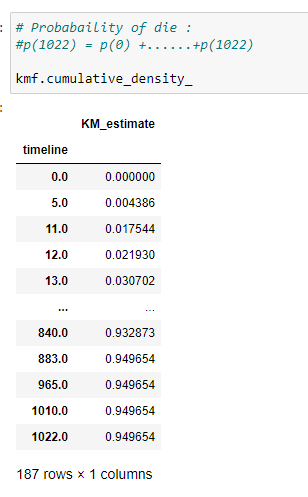
(22) Plot the graph:
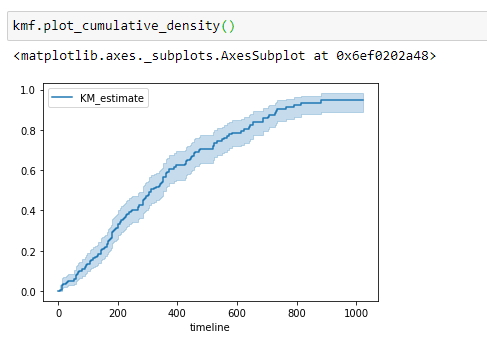
Notice that, as the number of survival days increases, the probability of a person dying increases.
Example 2: Estimating hazard rates using Nelson-Aalen
Hazard function:
The survival functions are a great way to summarize and visualize the survival dataset. However, it is not the only way. If we are curious about the hazard function h(t) of a population, we, unfortunately, can’t transform the Kaplan Meier estimate. For that, we use the Nelson-Aalen hazard function:
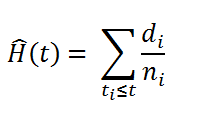
Hazard Function
Where,
di = number of deaths at time ti
ni = number of patients at the start.
(23) Import library:
(24) Fitting the data:

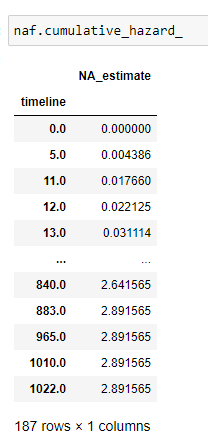
(25) Cumulative hazard:
Keep in mind we take at_risk of the current row:
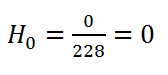
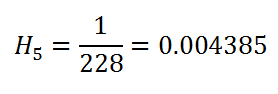
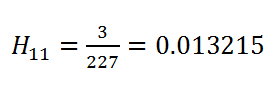
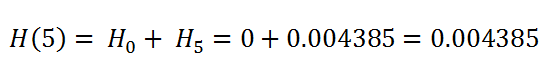
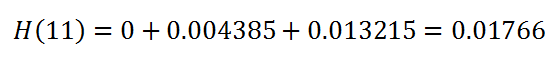
(26) Plot the data:
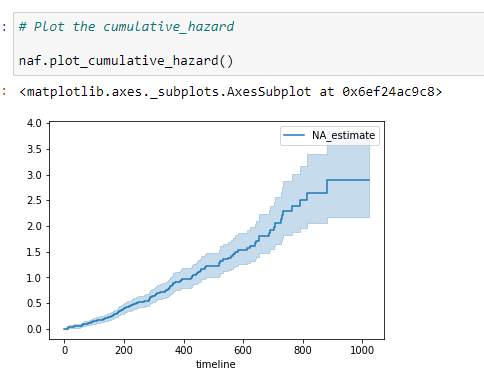
The cumulative hazard has less obvious understanding than the survival functions, but the hazard functions are the basis of more advanced techniques in survival analysis.
(27) Predict a value:
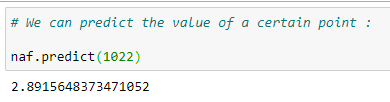
Putting it all together:
You can download the jupyter notebooks from here.
In the next article, we’ll discuss the log-rank test and cox regression with an example.
Original. Reposted with permission.
Bio: Pratik Shukla is an aspiring machine learning engineer who loves to put complex theories in simple ways. Pratik pursued his undergraduate in computer science and is going for a master's program in computer science at University of Southern California. “Shoot for the moon. Even if you miss it you will land among the stars. -- Les Brown”
Related: