PyTorch LSTM: Text Generation Tutorial
Key element of LSTM is the ability to work with sequences and its gating mechanism.
By Domas Bitvinskas, Closeheat
Long Short Term Memory (LSTM) is a popular Recurrent Neural Network (RNN) architecture. This tutorial covers using LSTMs on PyTorch for generating text; in this case - pretty lame jokes.
For this tutorial you need:
- Basic familiarity with Python, PyTorch, and machine learning
- A locally installed Python v3+, PyTorch v1+, NumPy v1+
What is LSTM?
LSTM is a variant of RNN used in deep learning. You can use LSTMs if you are working on sequences of data.
Here are the most straightforward use-cases for LSTM networks you might be familiar with:
- Time series forecasting (for example, stock prediction)
- Text generation
- Video classification
- Music generation
- Anomaly detection
RNN
Before you start using LSTMs, you need to understand how RNNs work.
RNNs are neural networks that are good with sequential data. It can be video, audio, text, stock market time series or even a single image cut into a sequence of its parts.
Standard neural networks (convolutional or vanilla) have one major shortcoming when compared to RNNs - they cannot reason about previous inputs to inform later ones. You cannot solve some machine learning problems without some kind of memory of past inputs.
For example, you might run into a problem when you have some video frames of a ball moving and want to predict the direction of the ball. The way a standard neural network sees the problem is: you have a ball in one image and then you have a ball in another image. It does not have a mechanism for connecting these two images as a sequence. Standard neural networks cannot connect two separate images of the ball to the concept of “the ball is moving.” All it sees is that there is a ball in the image #1 and that there's a ball in the image #2, but network outputs are separate.
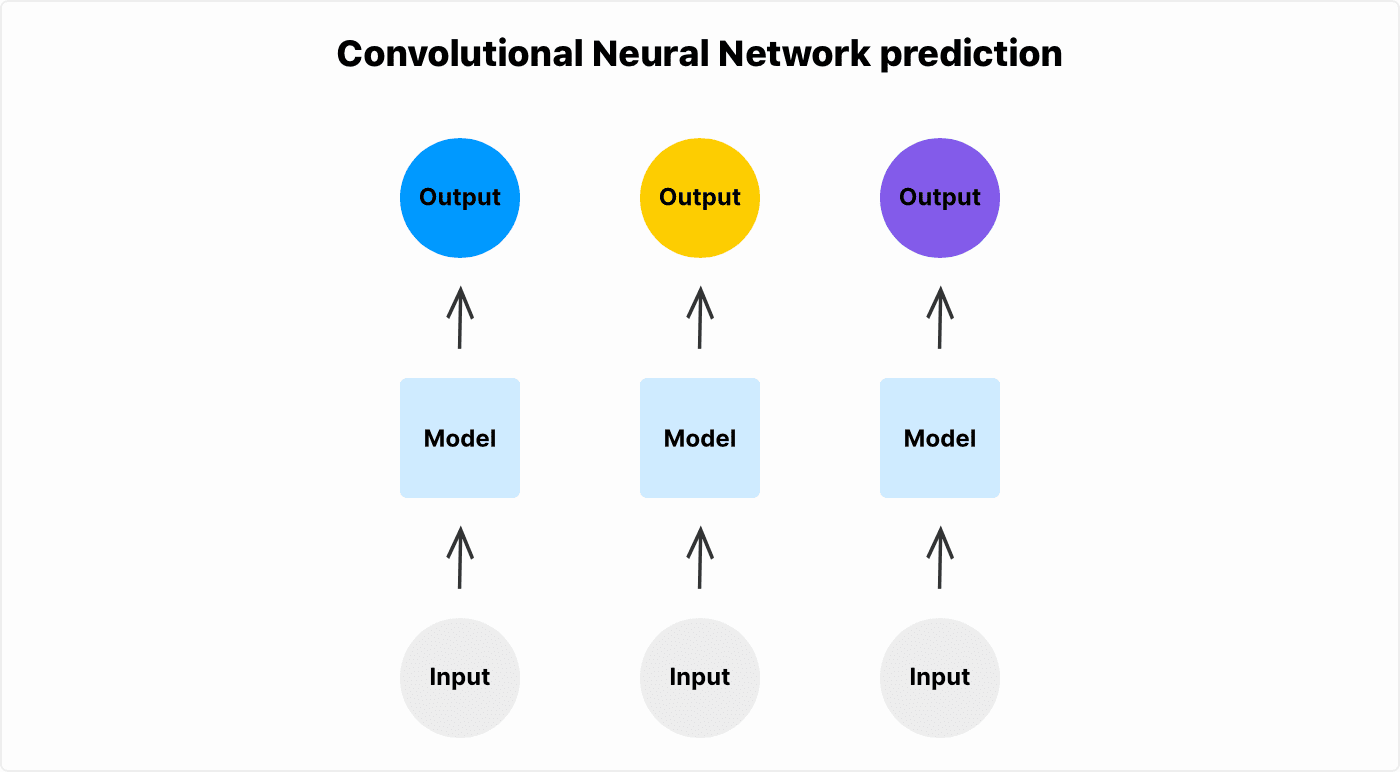
Compare this to the RNN, which remembers the last frames and can use that to inform its next prediction.
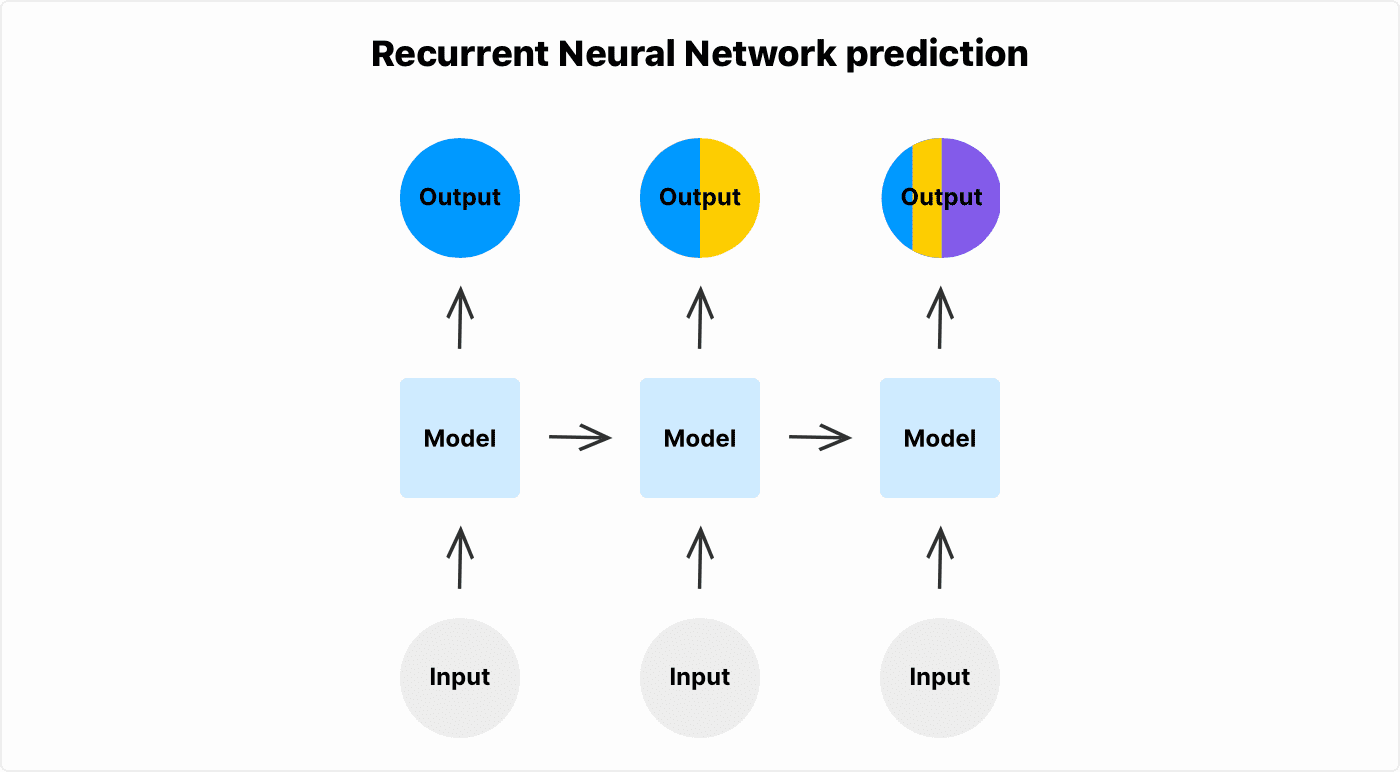
LSTM vs RNN
Typical RNNs can't memorize long sequences. The effect called “vanishing gradients” happens during the backpropagation phase of the RNN cell network. The gradients of cells that carry information from the start of a sequence goes through matrix multiplications by small numbers and reach close to 0 in long sequences. In other words - information at the start of the sequence has almost no effect at the end of the sequence.
You can see that illustrated in the Recurrent Neural Network example. Given long enough sequence, the information from the first element of the sequence has no impact on the output of the last element of the sequence.
LSTM is an RNN architecture that can memorize long sequences - up to 100 s of elements in a sequence. LSTM has a memory gating mechanism that allows the long term memory to continue flowing into the LSTM cells.
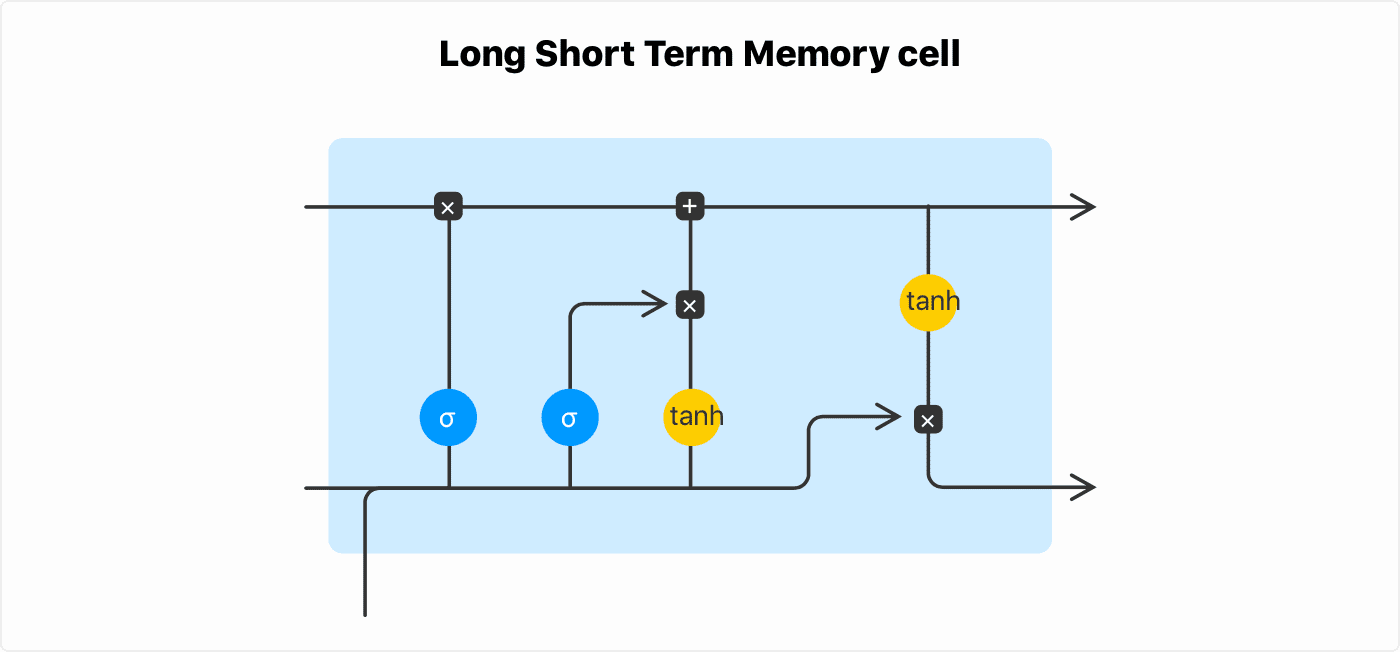
Text generation with PyTorch
You will train a joke text generator using LSTM networks in PyTorch and follow the best practices. Start by creating a new folder where you'll store the code:
$ mkdir text-generation
Model
To create an LSTM model, create a file model.py in the text-generation folder with the following content:
import torch
from torch import nn
class Model(nn.Module):
def __init__(self, dataset):
super(Model, self).__init__()
self.lstm_size = 128
self.embedding_dim = 128
self.num_layers = 3
n_vocab = len(dataset.uniq_words)
self.embedding = nn.Embedding(
num_embeddings=n_vocab,
embedding_dim=self.embedding_dim,
)
self.lstm = nn.LSTM(
input_size=self.lstm_size,
hidden_size=self.lstm_size,
num_layers=self.num_layers,
dropout=0.2,
)
self.fc = nn.Linear(self.lstm_size, n_vocab)
def forward(self, x, prev_state):
embed = self.embedding(x)
output, state = self.lstm(embed, prev_state)
logits = self.fc(output)
return logits, state
def init_state(self, sequence_length):
return (torch.zeros(self.num_layers, sequence_length, self.lstm_size),
torch.zeros(self.num_layers, sequence_length, self.lstm_size))
This is a standard looking PyTorch model. Embedding layer converts word indexes to word vectors. LSTM is the main learnable part of the network - PyTorch implementation has the gating mechanism implemented inside the LSTM cell that can learn long sequences of data.
As described in the earlier What is LSTM? section - RNNs and LSTMs have extra state information they carry between training episodes. forward function has a prev_state argument. This state is kept outside the model and passed manually.
It also has init_state function. Calling this at the start of every epoch to initializes the right shape of the state.
Dataset
For this tutorial, we use Reddit clean jokes dataset to train the network. Download (139KB) the dataset and put it in the text-generation/data/ folder.
The dataset has 1623 jokes and looks like this:
ID,Joke 1,What did the bartender say to the jumper cables? You better not try to start anything. 2,Don't you hate jokes about German sausage? They're the wurst! 3,Two artists had an art contest... It ended in a draw …
To load the data into PyTorch, use PyTorch Dataset class. Create a dataset.py file with the following content:
import torch
import pandas as pd
from collections import Counter
class Dataset(torch.utils.data.Dataset):
def __init__(
self,
args,
):
self.args = args
self.words = self.load_words()
self.uniq_words = self.get_uniq_words()
self.index_to_word = {index: word for index, word in enumerate(self.uniq_words)}
self.word_to_index = {word: index for index, word in enumerate(self.uniq_words)}
self.words_indexes = [self.word_to_index[w] for w in self.words]
def load_words(self):
train_df = pd.read_csv('data/reddit-cleanjokes.csv')
text = train_df['Joke'].str.cat(sep=' ')
return text.split(' ')
def get_uniq_words(self):
word_counts = Counter(self.words)
return sorted(word_counts, key=word_counts.get, reverse=True)
def __len__(self):
return len(self.words_indexes) - self.args.sequence_length
def __getitem__(self, index):
return (
torch.tensor(self.words_indexes[index:index+self.args.sequence_length]),
torch.tensor(self.words_indexes[index+1:index+self.args.sequence_length+1]),
)
This Dataset inherits from the PyTorch's torch.utils.data.Dataset class and defines two important methods __len__ and __getitem__. Read more about how Dataset classes work in PyTorch Data loading tutorial.
load_words function loads the dataset. Unique words are calculated in the dataset to define the size of the network's vocabulary and embedding size. index_to_word and word_to_index converts words to number indexes and visa versa.
This is part of the process is tokenization. In the future, torchtext team plan to improve this part, but they are re-designing it and the new API is too unstable for this tutorial today.
Training
Create a train.py file and define a train function.
import argparse
import torch
import numpy as np
from torch import nn, optim
from torch.utils.data import DataLoader
from model import Model
from dataset import Dataset
def train(dataset, model, args):
model.train()
dataloader = DataLoader(dataset, batch_size=args.batch_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(args.max_epochs):
state_h, state_c = model.init_state(args.sequence_length)
for batch, (x, y) in enumerate(dataloader):
optimizer.zero_grad()
y_pred, (state_h, state_c) = model(x, (state_h, state_c))
loss = criterion(y_pred.transpose(1, 2), y)
state_h = state_h.detach()
state_c = state_c.detach()
loss.backward()
optimizer.step()
print({ 'epoch': epoch, 'batch': batch, 'loss': loss.item() })
Use PyTorch DataLoader and Dataset abstractions to load the jokes data.
Use CrossEntropyLoss as a loss function and Adam as an optimizer with default params. You can tweak it later.
In his famous post Andrew Karpathy also recommends keeping this part simple at first.
Text generation
Add predict function to the train.py file:
def predict(dataset, model, text, next_words=100):
model.eval()
words = text.split(' ')
state_h, state_c = model.init_state(len(words))
for i in range(0, next_words):
x = torch.tensor([[dataset.word_to_index[w] for w in words[i:]]])
y_pred, (state_h, state_c) = model(x, (state_h, state_c))
last_word_logits = y_pred[0][-1]
p = torch.nn.functional.softmax(last_word_logits, dim=0).detach().numpy()
word_index = np.random.choice(len(last_word_logits), p=p)
words.append(dataset.index_to_word[word_index])
return words
Execute predictions
Add the following code to train.py file to execute the defined functions:
parser = argparse.ArgumentParser()
parser.add_argument('--max-epochs', type=int, default=10)
parser.add_argument('--batch-size', type=int, default=256)
parser.add_argument('--sequence-length', type=int, default=4)
args = parser.parse_args()
dataset = Dataset(args)
model = Model(dataset)
train(dataset, model, args)
print(predict(dataset, model, text='Knock knock. Whos there?'))
Run the train.py script with:
$ python train.py
You can see the loss along with the epochs. The model predicts the next 100 words after Knock knock. Whos there? when the training finishes. By default, it runs for 10 epochs and takes around 15 mins to finish training.
{'epoch': 9, 'batch': 91, 'loss': 5.953955173492432}
{'epoch': 9, 'batch': 92, 'loss': 6.1532487869262695}
{'epoch': 9, 'batch': 93, 'loss': 5.531163215637207}
['Knock', 'knock.', 'Whos', 'there?', '3)', 'moostard', 'bird', 'Book,',
'What', 'when', 'when', 'the', 'Autumn', 'He', 'What', 'did', 'the',
'psychologist?', 'And', 'look', 'any', 'jokes.', 'Do', 'by', "Valentine's",
'Because', 'I', 'papa', 'could', 'believe', 'had', 'a', 'call', 'decide',
'elephants', 'it', 'my', 'eyes?', 'Why', 'you', 'different', 'know', 'in',
'an', 'file', 'of', 'a', 'jungle?', 'Rock', '-', 'and', 'might', "It's",
'every', 'out', 'say', 'when', 'to', 'an', 'ghost', 'however:', 'the', 'sex,',
'in', 'his', 'hose', 'and', 'because', 'joke', 'the', 'month', '25', 'The',
'97', 'can', 'eggs.', 'was', 'dead', 'joke', "I'm", 'a', 'want', 'is', 'you',
'out', 'to', 'Sorry,', 'the', 'poet,', 'between', 'clean', 'Words', 'car',
'his', 'wife', 'would', '1000', 'and', 'Santa', 'oh', 'diving', 'machine?',
'He', 'was']
If you skipped to this part and want to run the code, here's a Github repository you can clone.
Next steps
Congratulations! You've written your first PyTorch LSTM network and generated some jokes.
Here's what you can do next to improve the model:
- Clean up the data by removing non-letter characters.
- Increase the model capacity by adding more
LinearorLSTMlayers. - Split the dataset into train, test, and validation sets.
- Add checkpoints so you don't have to train the model every time you want to run prediction.
Bio: Domas Bitvinskas (@domasbitvinskas) leads machine learning and growth experiments at Closeheat.
Original. Reposted with permission.
Related:
- PyTorch for Deep Learning: The Free eBook
- Generating cooking recipes using TensorFlow and LSTM Recurrent Neural Network: A step-by-step guide
- The Most Important Fundamentals of PyTorch you Should Know