Understanding How Neural Networks Think
A couple of years ago, Google published one of the most seminal papers in machine learning interpretability.

I recently started a new newsletter focus on AI education. TheSequence is a no-BS (meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

One of the challenging elements of any deep learning solution is to understand the knowledge and decisions made by deep neural networks. While the interpretation of decisions made by a neural networks has always been difficult, the issue has become a nightmare with the raise of deep learning and the proliferation of large scale neural networks that operate with multi-dimensional datasets. Not surprisingly, the interpretation of neural networks has become one of the most active areas of research in the deep learning ecosystem.
Try to imagine a large neural network with hundreds of millions of neurons that is performing a deep learning task such as image recognition. Typically, you would like to understand how the network arrives to specific decisions. Most of the current research has focused on detecting what neurons in the network have been activated. Knowing that neuron-12345 fired five times is relevant but not incredibly useful in the scale of the entire network. The research about understanding decisions in neural networks has focused on three main areas: feature visualization, attribution and dimensionality reduction. Google, in particular, has done a lot of work in the feature visualization space publishing some remarkable research and tools. Over a year ago, Google researchers published a paper titled “The Building Blocks of Interpretability” that became a seminal paper in the are of machine learning interpretability. The paper proposes some new ideas to understand how deep neural networks make decisions.
The main insight of Google’s research is to not see the different interpretability techniques in isolation but as composable building blocks of larger models that help understand the behavior of neural networks. For instance, feature visualization is a very effective technique to understand the information processed by individual neurons but fails to correlate that insight with the overall decision made by the neural network. Attribution is a more solid technique to explain the relationship between different neurons but not so much when comes to understand the decision made by individual neurons. Combining those building blocks, Google has created an interpretability models that does not only explains what a neural network detects, but it does answer how the network assembles these individual pieces to arrive at later decisions, and why these decisions were made.
How does the new Google model for interpretability works specifically? Well, the main innovation, in my opinion, is that it analyzes the decisions made by different components of a neural network at different levels: individual neurons, connected groups of neurons and complete layers. Google also uses a novel research technique called matrix factorization to analyze the impact that arbitrary groups of neurons can have in the final decision.
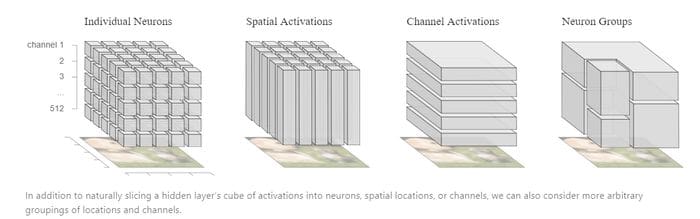
A good way to think about Google’s blocks of interpretability is as a model that detects insights about the decisions of a neural network at different levels of abstraction from the basic computation graph to the final decision.

Google research of deep neural network interpretability is not only a theoretical exercise. The research group accompanied the paper with the release of Lucid, a neural network visualization library that allow developers to make the sort lucid feature visualizations that illustrate the decisions made by individual segments of a neural network. Google also released colab notebooks. These notebooks make it extremely easy to use Lucid to create Lucid visualization in an interactive environment.
Original. Reposted with permission.
Related:
- Learning by Forgetting: Deep Neural Networks and the Jennifer Aniston Neuron
- Uber’s Ludwig is an Open Source Framework for Low-Code Machine Learning
- Google Unveils TAPAS, a BERT-Based Neural Network for Querying Tables Using Natural Language