 Wrapping Machine Learning Techniques Within AI-JACK Library in R
Wrapping Machine Learning Techniques Within AI-JACK Library in R
 Wrapping Machine Learning Techniques Within AI-JACK Library in R
Wrapping Machine Learning Techniques Within AI-JACK Library in RThe article shows an approach to solving problem of selecting best technique in machine learning. This can be done in R using just one library called AI-JACK and the article shows how to use this tool.
By Jędrzej Furmann, AI-JACK Co-developer
Nowadays, AI state-of-the-art techniques includes, among other things, comparing multiple machine learning models within one tool/library. However, it’s still very common to try different techniques manually, which – when done over and over – is both boring and prone to mistakes. Diminishing risk of failures gets even more important when having large amounts of code, as debugging and testing gets laborious. With this in mind, AI-JACK was created. It’s a machine learning pipeline accelerator, designed as R library to solve problems quicker and better.

What is it?
AI-JACK is written as a library in R, although it doesn’t require any coding from the user unless they want to add custom features. It contains multiple functions built in to help in going through the whole pipeline. There are modules for data loading, preprocessing, model training and versioning, as well as deployment, and all of those can be controlled with just few parameters within one configuration file. The modelling is done mostly using H2O API, a state-of-the-art ML framework, with many algorithms available, such as XGBoost, random forests, linear models, deep learning, EM clustering, isolation forests and more.
Although many features are in-built, the code can be modified in any way. Users can add other functions or models on top of AI-JACK. This is the strength of the tool: it can serve both as a full pipeline in many kinds of problems or can be just a step within a bigger process.
AI-JACK trains selected models on different sets of hyperparameters, chooses the best one according to selected metric and then saves its output – metadata, validation results, feature importance and the model itself – to given path. Results can also be in a form of web service, where you could access them via API.
How to use AI-JACK?
In order to work, you need to have R runtime installed. RStudio will also be handy as an IDE with most-used text editor to write R code, although as AI-JACK in its basic version doesn’t require coding, a simple notebook can be enough.
AI-JACK needs also a working installation of Java Runtime Environment.
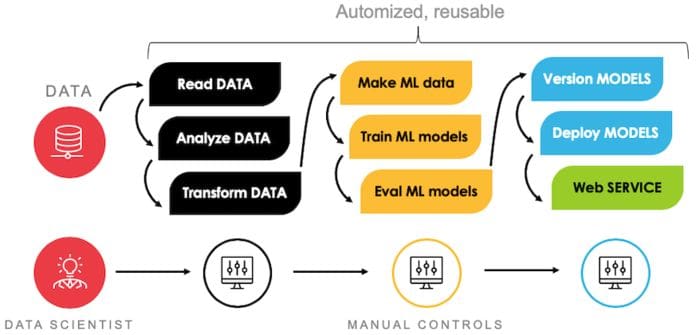
Your dataset should generally be pre-processed prior to using AI-JACK. The library supports only minor techniques: removing special characters, missing values, splitting into test/train/validation sets. It might be loaded either as a local csv file or connected to SQL database. Then all you need to do is to initialize your project in selected path with function `init_aijack` and specify parameters in newly-created configuration file – `config_model.R` or `config_clust_model.R`, depending if you wish to use supervised or unsupervised ML. After saving the config file, run `main_model.R` or `main_clust_model.R` and several models will be trained. All needed files are saved automatically to selected path.
If you are training a supervised model, csv outputs include information about feature importance over all techniques, as well as validation results, names of columns created (if, for example, the model used dummy variables), accuracy score of each execution, possible errors and metadata about the model.
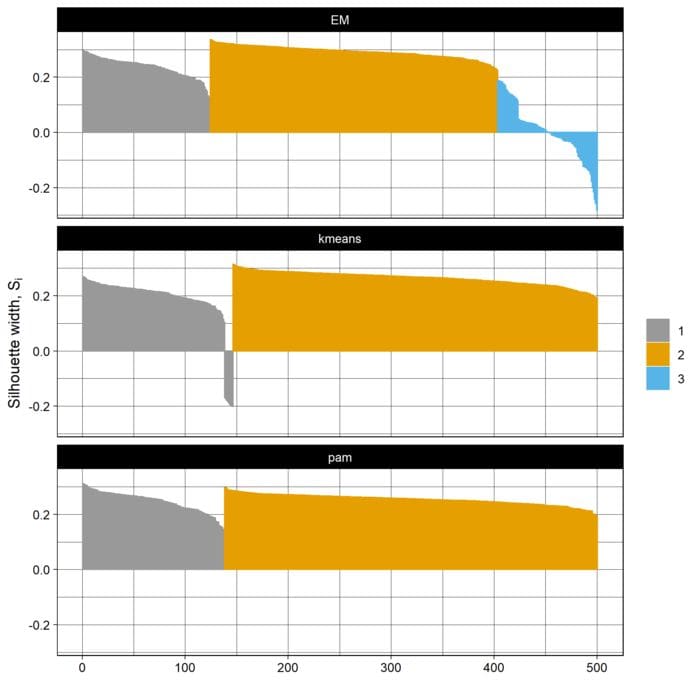
If you’re using clustering, AI-JACK automatically trains three techniques and saves png charts comparing those models according to silhouette score. The techniques are k-means, k-medoids and expectation-maximization, most-used ones among unsupervised techniques.
Detailed manual as well as contact details to developers can be found on GitHub page. AI-JACK is an open-source project, thus contributions are welcome! If you find the library useful and want to help and developing it, you are free to do so.
Bio: Jędrzej Furmann is a Junior Data Scientist and AI-JACK co-developer.
Related:
- Automated Machine Learning: The Free eBook
- modelStudio and The Grammar of Interactive Explanatory Model Analysis
- Practical Hyperparameter Optimization