Content-Based Recommendation System using Word Embeddings
This article explores how average Word2Vec and TF-IDF Word2Vec can be used to build a recommendation engine.
By Dhilip Subramanian, Data Scientist and AI Enthusiast
In my previous article, I have written about a content-based recommendation engine using TF-IDF for Goodreads data. In this article, I am using the same Goodreads data and build the recommendation engine using word2vec.
Like the previous article, I am going to use the same book description to recommend books. The algorithm that we use always struggles to handle raw text data and it only understands the data in numeric form. In order to make it understand, we need to convert the raw text into numeric form. This can be achieved with the help of NLP by converting the raw text into vectors.
I used TF-IDF to convert the raw text into vectors in the previous recommendation engine. However, it does not capture the semantic meaning and also it gives a sparse matrix. Research and breakthroughs are happening in NLP at an unprecedented pace. Neural network architectures has become famous for understanding the word representations and this is also called word embeddings.
Word embedding features create a dense, low dimensional feature whereas TF-IDF creates a sparse, high dimensional feature. It also captures the semantic meaning very well.
One of the significant breakthroughs is word2vec embeddings which were introduced in 2013 by Google. Using embeddings word2vec outperforms TF-IDF in many ways. Another turning point in NLP was the Transformer network introduced in 2017. Followed by multiple research, BERT (Bidirectional Encoder Representations from Transformers) and many others were introduced which are considered state of art algorithms in NLP.
This article explores how average Word2Vec and TF-IDF Word2Vec can be used to build a recommendation engine. I will explore how BERT embeddings can be used in my next article.
What is Word2Vec?
Word2Vec is a simple neural network model with a single hidden layer. It predicts the adjacent words for each and every word in the sentence or corpus. We need to get the weights that are learned by the hidden layer of the model and the same can be used as word embeddings.
Let’s see how it works with the sentence below:

From the above, let’s assume the word “theorist” is our input word. It has a context window of size 2. This means we are considering only the 2 adjacent words on either side of the input word as the adjacent words.
Now, the task is to pick the nearby words (words in the context window) one-by-one and find the probability of every word in the vocabulary of being the selected adjacent word. Here, the context window can be changed as per our requirement.
Word2Vec has two model architectures variants: Continuous Bag-of-Words (CBoW) and SkipGram. The internet is literally flooded with a lot of articles about Word2Vec, hence I have not explained in detail. Please check here for more details on Word2Vec.
In simpler terms, Word2Vec takes the word and returns a vector in D-dimensional space.
Please note, Word2Vec provides the word embeddings in low dimensionality (50–500) which are dense (it’s not a sparse matrix, most values are non-zero). I used 300 dimension vectors for this recommendation engine. As I mentioned above, Word2Vec is good at capturing semantic meaning and relationships.
Training our own word embeddings is an expensive process and also requires a large dataset. I don’t have a large dataset as I scraped Goodreads data which only pertains to the genres of business and cooking. We will use Google pre-trained word embeddings which were trained on a large corpus, including Wikipedia, news articles and more.
The pre-trained embeddings helped to get the vectors for the words you want. It is a large collection of key-value pairs, where keys are the words in the vocabulary and values are their corresponding word vectors.
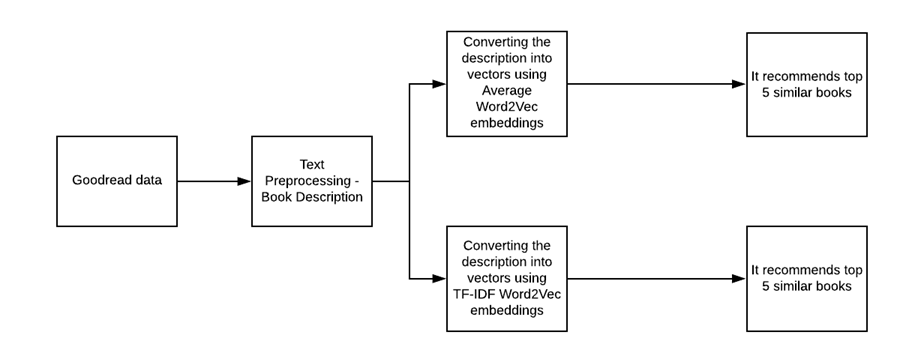
In our problem, we need to convert the book descriptions into a vector and finding the similarity between these vectors to recommend books. Each book description is a sentence or sequence of words. I have tried two methods: average Word2vec and TF-IDF Word2Vec.
Average Word2Vec
Let’s take some random description example in our dataset.
Book title: The Four Pillars of Investing
Book Description:william bernstein american financial theorist neurologist research field modern portfolio theory research financial books individual investors wish manage equity field lives portland oregonOK, how do we convert the above description into vectors? As you know, Word2vec takes the word and gives a D-dimension vector. First, we need to split the sentences into words and find the vectors representation for each word in the sentence.
The above example has 23 words. Let’s denote the words as w1, w2, w3, w4 …w23. (w1 = william, w2 = bernstein, ..., w23 = oregon). Calculate Word2Vec for all the 23 words.
Then, sum all the vectors and divide the same by a total number of words in the description (n). It can be denoted as v1 and calculated as follows:

Here, vectors are in D-dimensional space, where D = 300.
N = number of words in description 1 (Total: 23)
v1 = vector representation of book description 1
This is how we calculate the average Word2vec. In the same way, the other book descriptions can be converted into vectors. I have implemented this in Python and code snippets are given below.
TF-IDF Word2Vec
TF-IDF is a term frequency-inverse document frequency. It helps to calculate the importance of a given word relative to other words in the document and in the corpus. It calculates in two quantities, TF and IDF. Combining two will give a TF-IDF score. A detailed explanation of how TF-IDF work is beyond the scope of this article as it is flooded with many articles on the internet. Please check here for more details on TF-IDF.
Let’s see how TF-IDF Word2Vec works,
Consider the same description example
Book Description:william bernstein american financial theorist neurologist research field modern portfolio theory research financial books individual investors wish manage equity field lives portland oregonAgain, the description has 23 words. Let’s denote the words as w1, w2, w3, w4 …w23. (w1 = william, w2 = bernstein …. …..w23 = oregon).
Steps to calculate the TF-IDF Word2Vec:
- Calculate the TF-IDF vector for each word in the above description. Let’s call the TF-IDF vectors as tf1, tf2, tf3, ..., tf23. Please note TF-IDF vector won’t give D-dimensional vectors
- Calculate the Word2Vec for each word in the description
- Multiply the TF-IDF score and Word2Vec vector representation of each word and total
- Then divide the total by sum of TF-IDF vectors. It can be called v1 and written as follow

v1 = vector representation of book description 1. This is the method for calculating TF-IDF Word2Vec. In the same way, we can convert the other descriptions into vectors. I have implemented this in Python and code snippets are given below.
Content-based recommendation system
A content-based recommendation system recommends books to a user by considering the similarity of books. This recommender system recommends a book based on the book description. It identifies the similarity between the books based on its description. It also considers the user's previous book history in order to recommend a similar book.
Example: If a user likes the novel “Tell Me Your Dreams” by Sidney Sheldon, then the recommender system recommends the user to read other Sidney Sheldon novels or it recommends a novel with the genre “non-fiction”. (Sidney Sheldon novels belong to the non-fiction genre).
We need to find similar books to a given book and then recommend those similar books to the user. How to find whether the given book is similar or dissimilar? A similarity measure was used to find the same. Cosine similarity was used in our recommender system to recommend the books. For more details on this similarity measure, please refer to this article.
As I mentioned above, we are using goodreads.com data and don’t have a user's reading history. Hence, I am not able to use a collaborative recommendation engine.
Data
I scraped book details from goodreads.com pertaining to business, non-fiction, and cooking genres.
Code
Output

The data consist of 2382 records. It has two genres, 1) Business (1185 records) 2) Non-Fiction (1197 records). Also, it consists of Book title, description, author name, rating, and book image link.
Text Preprocessing
Cleaning the book description and storing the cleaned description in a new variable called ‘cleaned’:
Recommendation Engine
Building two recommendation engine using Average Word2Vec and TF-IDF Word2Vec word embeddings.
Average Word2Vec
Splitting the descriptions into words and storing in a list called ‘corpus’ for training our word2vec model:
Training our corpus with Google pre-trained Word2Vec model:
Creating a function called vectors for generating average Word2Vec embeddings and storing them as a list called ‘word_embeddings’. The code follows the steps which I have written in the above average word2vec explanation.
Top 5 Recommendation using Average Word2Vec
Let’s get a recommendation based on the book “The Da Vinci Code” by Dan Brown:
The model recommends other Dan Brown books based on the similarity existing in the book description.
Let’s get a recommendation based on the book “The Murder of Roger Ackroyd” by Agatha Christie:
This book belongs to "mystery thriller" and it recommends similar kinds of novels.
Building TF-IDF Word2Vec Model
The code explains the same steps which I mentioned above the process of creating the TF-IDF Word2Vec model. I am using the same corpus, with the only change being in the word embeddings.
Building the TF-IDF model
Building TF-IDF Word2Vec Embeddings
Top 5 Recommendation using TF-IDF Word2Vec
Let’s get a recommendation based on the book “The Da Vinci Code” by Dan Brown:
We can see the model recommends Sherlock Holmes novels and the output is different from the average word2vec method above.
Let’s get a recommendation based on the book “The Murder of Roger Ackroyd” by Agatha Christie:
Again it recommends different books than the average word2vec method above. However, it still recommends similar novels to those written by Agatha Christie.
It seems that TF-IDF Word2Vec gives more powerful recommendations than average Word2vec. This article only explores how to use average Word2Vec and TF-IDF Word2Vec to build a recommendation engine, without comparing the results between these two models. The data that I have used is very minimum and the results would definitely change if we used a larger dataset. Also, we could use FastText (from Facebook) and Glove (from Stanford) pre-trained word Embeddings instead of Google's Word2vec to see if the difference.
Real-world recommendation systems are more robust and advanced than those presented herein. A/B testing can be used to evaluate recommendation engines, and business domain plays a major role in their evaluation and selection.
In my next article, I will show how to use BERT embeddings to build the same type of recommendation engine. You can find the entire code and data in my GitHub repo.
Thanks for reading. Keep learning and stay tuned for more!
Bio: Dhilip Subramanian is a Mechanical Engineer and has completed his Master's in Analytics. He has 9 years of experience with specialization in various domains related to data including IT, marketing, banking, power, and manufacturing. He is passionate about NLP and machine learning. He is a contributor to the SAS community and loves to write technical articles on various aspects of data science on the Medium platform.
Original. Reposted with permission.
Related:
- Recommender Systems in a Nutshell
- Building a Content-Based Book Recommendation Engine
- Word Embedding Fairness Evaluation