LinkedIn’s Pro-ML Architecture Summarizes Best Practices for Building Machine Learning at Scale
The reference architecture is powering mission critical machine learning workflows within LinkedIn.

I recently started a new newsletter focus on AI education. TheSequence is a no-BS (meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Building machine learning solutions at scale remains an active area of experimentation for most organizations. While many companies are starting their initial machine learning pilots, few have a robust strategy to scale machine learning workflows. This issue is particularly challenging if we consider that, in the current market, machine learning research and development frameworks have evolved disproportionately faster than the corresponding infrastructure runtimes required to scale machine learning programs. With so little guidance available about how to build machine learning solutions at scale, an invaluable source becomes the experience of internet giants such as Uber, LinkedIn, Google, Netflix or Microsoft whose scalability requirements are exceedingly more complex than the ones faced by most companies. At LinkedIn, the roadblocks for delivering machine learning solutions at scale were becoming so critical that the company decided to create a separate initiative called Productive Machine Learning(Pro-ML) to address this challenge.
A machine learning solution typically goes through a series of stages from model training to deployment. While structuring that lifecycle in machine learning solutions with a handful of models and small teams is relatively trivial but scaling it across dozens of data science teams and thousands of machine learning models is nothing short of a nightmare. In an organization like LinkedIn, machine learning are vulnerable to many well-known scaling challenges:
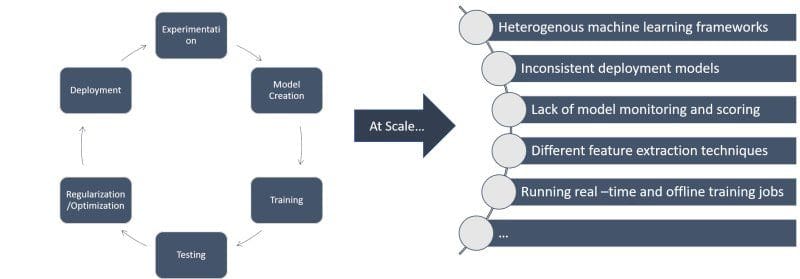
Introducing Pro-ML
The goal of the Pro-ML initiative at LinkedIn was to double the effectiveness of machine learning engineers while providing an open infrastructure to foment the adoption of machine learning technologies within the company. To achieve that, Pro-ML focused on providing a robust infrastructure that will enable a key set of stages in the lifecycle of machine learning solutions:
- Exploring and authoring
- Training
- Deploying
- Running
- Health assurance
- Feature marketplace

Exploring and Authoring
Data exploration and model authoring are essential aspects of the lifecycle of machine learning solution. As a data science organization grows, they face the challenge of different teams adopting different approaches for data exploration and relying on different frameworks for creating models. This wouldn’t be a problem except for the fact that data exploration infrastructures tend to be one of the most computationally expensive components of machine learning workflows.
To enable a consistent data exploration and model authoring experience, Pro-ML relied on a domain-specific-language(DSL) that abstracts the key representations of a machine learning model such as input features, transformation, algorithms, outputs and several others. Additionally, Pro-ML provides Jupyter Notebooks that hat allows step-by-step exploration of the data, selection of features, and drafting the DSL. The Pro-ML team also provided bindings to integrate their machine learning DSL with popular IDEs such as IntelliJ.
Providing an interoperable mechanism for representing machine learning models is a clever mechanism to ensure consistency across diverse data science stacks. Looking at the Pro-ML DSL, I wonder if something such as the Open Neural Network Exchange Format(ONNX) is a more natural fit but the approach makes sense nonetheless.
Feature Marketplace
Complementing the previous point, one of the key roles of data exploration processes in machine learning workflows is to identify the key features of the target datasets. At the scale of an organization like LinkedIn, machine learning solutions need to deal with tens of thousands of features that need to be produced, discovered, consumed, and monitored. To address this challenge, Pro-ML built a central catalog for model features called Frame.
The goal of Pro-ML’s Frame is to capture the metadata related to features of datasets both online and offline. Frame captures the data in a centralized database which is connected to Pro-ML’s model repository. Additionally, Frame provides a UI that allows data scientists to search for features based on various facets including the type of feature (numeric, categorical), statistical summary, and current usage in the overall ecosystem.
Training
In large organization such as LinkedIn, machine learning training workflows can be divided into two main groups: real time(online) and batch(offline). Machine learning models that are time-sensitive require regular training using near real time datasets. Other models are better off being trained in batches on larger time cycles like daily or weekly.
Pro-ML provides a training infrastructure that support both online and offline models. The infrastructure includes a training service that supports different model types as well as tools for capabilities such as hyperparameter tuning. Pro-ML’s training runtime relies on Hadoop for offline training and also leverages technologies such as Azkabanand Spark to execute training workflows.
Model Deployment
Model deployment is one of the most challenging aspects of large scale machine learning solutions. Effective model deployment typically requires to structure and package the different model artifacts in portable formats that can be executed across the infrastructure.
Pro-ML includes a deployment service that identifies the different artifacts of a machine learning models such as features, libraries or code dependencies and store them in a centralized repository for automatic validation. The deployment service enables capabilities such as orchestration, monitoring, and notification to ensure that the desired code and data artifacts are correctly deployed and working.
Running
Model serving and execution is another challenging aspect of machine learning workflows. Differently from traditional software applications, the performance of machine learning models can require different infrastructure configurations during its lifecycle and its performance can vary substantially depending on several aspects.
The current version of Pro-ML includes a model execution engine called Quasar that is responsible for executing machine learning models defined in the proprietary DSL discussed previously. Quasar integrates with the feature marketplace to regularly evaluate the performance of models and it leverages mainstream serving frameworks such as TensorFlow Serving or XGBoost to enable federated execution models.
Health Assurance
Machine learning models are notably hard to test and monitor. Pro-ML includes a health assurance layer that enable the testing and monitoring of machine learning workflows. The health assurance layer regularly validates that the performance of a deployed model is in-line with the behavior exhibited during training and, in the case that anomalies are detected, it provides tools to diagnose the source of the issue. Pro-ML’s health assurance layer includes tools for data replaying, bug diagnose or model retraining which help to ensure the correct behavior of machine learning models.
Pro-ML is currently powering hundreds of machine learning models across different LinkedIn products. While LinkedIn hasn’t open sourced many of the components behind Pro-ML, the patterns and lessons learned represent an invaluable resource for organizations embarking in their machine learning journey.
Original. Reposted with permission.
Related:
- A Deep Learning Dream: Accuracy and Interpretability in a Single Model
- What an Argentine Writer and a Hungarian Mathematician Can Teach Us About Machine Learning Overfitting
- Can Neural Networks Show Imagination? DeepMind Thinks They Can