Explaining the Explainable AI: A 2-Stage Approach
Understanding how to build AI models is one thing. Understanding why AI models provide the results they provide is another. Even more so, explaining any type of understanding of AI models to humans is yet another challenging layer that must be addressed if we are to develop a complete approach to Explainable AI.
By Amit Dhurandhar, Research Scientist at IBM.
Everything should be made as simple as possible, but not simpler.
- Albert Einstein
(Brief) Background
As artificial intelligence (AI) models, especially those using deep learning, have gained prominence over the last eight or so years [8], they are now significantly impacting society, ranging from loan decisions to self-driving cars. Inherently though, a majority of these models are opaque, and hence following their recommendations blindly in human critical applications can raise issues such as fairness, safety, reliability, along with many others. This has led to the emergence of a subfield in AI called explainable AI (XAI) [7]. XAI is primarily concerned with understanding or interpreting the decisions made by these opaque or black-box models so that one can appropriate trust, and in some cases, have even better performance through human-machine collaboration [5].
While there are multiple views on what XAI is [12] and how explainability can be formalized [4, 6], it is still unclear as to what XAI truly is and why it is hard to formalize mathematically. The reason for this lack of clarity is that not only must the model and/or data be considered but also the final consumer of the explanation. Most XAI methods [11, 9, 3], given this intermingled view, try to meet all these requirements at the same time. For example, many methods try to identify a sparse set of features that replicate the decision of the model. The sparsity is a proxy for the consumer's mental model. An important question asks whether we can disentangle the steps that XAI methods are trying to accomplish? This may help us better understand the truly challenging parts as well as the simpler parts of XAI, not to mention it may motivate different types of methods.
Two-Stages of XAI
We conjecture that the XAI process can be broadly disentangled into two parts, as depicted in Figure 1. The first part is uncovering what is truly happening in the model that we want to understand, while the second part is about conveying that information to the user in a consumable way. The first part is relatively easy to formalize as it mainly deals with analyzing how well a simple proxy model might generalize either locally or globally with respect to (w.r.t.) data that is generated using the black-box model. Rather than having generalization guarantees w.r.t. the underlying distribution, we now want them w.r.t. the (conditional) output distribution of the model. Once we have some way of figuring out what is truly important, a second step is to communicate this information. This second part is much less clear as we do not have an objective way of characterizing an individual's mind. This part, we believe, is what makes explainability as a whole so challenging to formalize. A mainstay for a lot of XAI research over the last year or so has been to conduct user studies to evaluate new XAI methods.
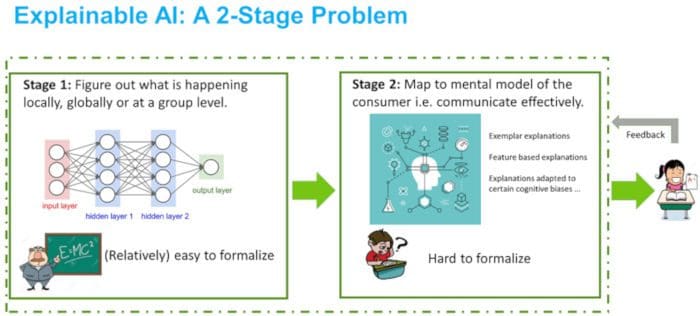
Figure 1: For conceptual clarity, explainable AI (XAI) can be thought of as a 2-stage problem where in the first stage, one has to figure out how the model is making decisions followed by (effectively) communicating it. Stage 1 is (relatively) easy to formalize, while Stage 2 is not as it requires making "reasonable" assumptions about the humans mental model. Of course, the explanation system could try to figure the second stage out by adapting to human feedback.
This tries to address the second stage requirements. A further possibility to structure the second part could be to design canonical use cases or scenarios followed by correlating them with the most important metrics amongst the many that have been proposed in XAI literature [2]. Data scientists and researchers can then build methods to optimize these metrics. This, to a certain degree, would be analogous to the optimization literature, at least in spirit, where canonical problems are defined to cover different scenarios [1].
There are works [12] that model XAI as primarily a communication problem. However, we believe that it can truly be split into two aspects: i) model understanding and ii) human consumability. The methods mentioned before, and many more, indirectly convey an intermingled view, as shown in Figure 2.
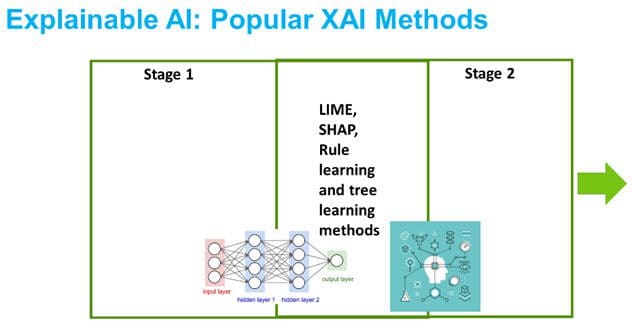
Figure 2: An intermingled view that XAI methods (indirectly) convey and try to solve.
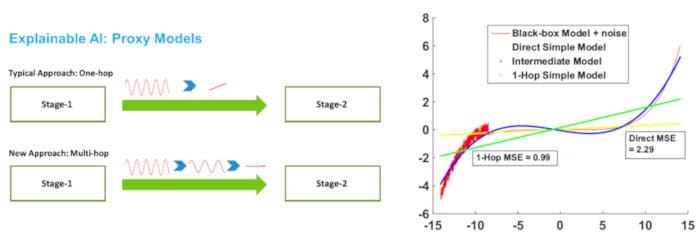
Figure 3: A multihop approach for XAI can lead to many more methods and potentially give better results. In the figure on the right, we see a black-box model (fifth-degree polynomial) with uniform random noise added to the first 20% of its predictions (red curve). A (robust) linear model* is directly fit to the black-box (yellow line), which has an MSE (the desired target loss) of 2.29. For the multihop approach, we first fit a polynomial of degree three to the black-box model+noise (blue curve). We then fit a linear model to this degree three polynomial (green line) and find that its MSE relative to the black-box model is less than half of the direct fitting.
* The robustfit method in Matlab was used, which uses bisquare loss.
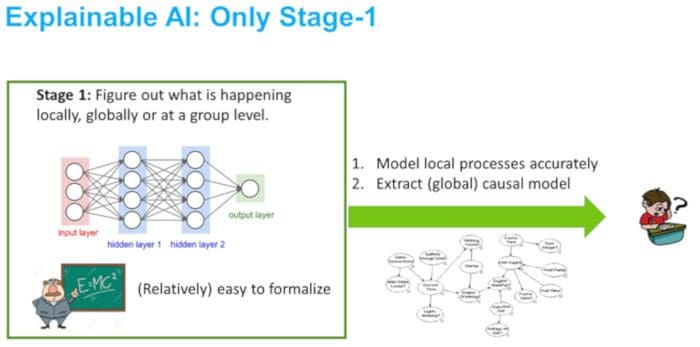
Figure 4: Building a highly accurate local model or extracting a global causal model still just corresponds to solving Stage 1 in the most general sense.
New Approaches
With this 2-stage view in mind, we can now consider more approaches than those that have been explored in XAI literature. For example, for Stage 1, to the best of our knowledge, all approaches try to obtain explanations directly from the black-box model stemming from this intermingled view, which restricts the power of proxy models/techniques that can be applied. However, given that Stage 1 does not have to communicate directly with the user, we have some leeway w.r.t. the complexity of models we might build. In other words, there is no reason why we have to jump directly from a black-box model to an interpretable model. We could, in fact, build a sequence of models of possibly decreasing complexity where only the final model needs to be consumable. Being able to build such a sequence might improve how well the final interpretable model might replicate the behavior of the black-box model w.r.t. some target measure/loss (viz. lower MSE or higher accuracy), while having the same level of complexity as any direct fitting procedure. For instance, consider the example in Figure 3, where in the figure on the right, we see that fitting a linear model to an intermediate less complex model leads to a more robust predictor than direct fitting. Such improvements would typically be possible because the target (or evaluation) loss is many times different than the (training) loss of the model that is consumable. One could easily envision extending this idea where multiple intermediate models could be used to smooth out the landscape before training the intended interpretable model. Trivially, one could use a copy of the original black-box or some other complicated model to perfectly model the black-box as an intermediate model. However, the utility of this strategy is hard to imagine.
Does causality imply explainability?
There is a lot of recent hype around causality in general [10] and causal explanations. However, we argue that knowledge of the causal mechanisms still corresponds to solving only Stage 1 in its most general form. The reasoning is simple. The causal graph for many complicated systems might be too large to parse and understand in its entirety. Moreover, the individual nodes (viz. latent features) in a causal graph may not even be interpretable or actionable in any way. This is depicted in Figure 4. Barring the serendipitous situation where we have a small causal graph with all nodes being interpretable, Stage 2 would still be necessary for XAI.
Concluding Remarks
The above exposition may be obvious to some folks. However, it wasn't to me, which is why I thought of calling these aspects out explicitly. I hope this perspective helps at least some of you demystify the subjectivity surrounding this topic, as it did for me.
Acknowledgments
I would like to thank Ronny Luss and Karthikeyan Shanmugam for their detailed feedback.
References
[1] S. Boyd and L. Vandenberghe. Convex Optimization. Cambridge University Press, March 2004.
[2] D. V. Carvalho, E. M. Pereira, and J. S. Cardoso. Machine learning interpretability: A survey on methods and metrics. Electronics, 8(8):832,2019.
[3] A. Dhurandhar, P.-Y. Chen, R. Luss, C.-C. Tu, P. Ting, K. Shanmugam, and P. Das. Explanations based on the missing: Towards contrastive explanations with pertinent negatives. In Advances in Neural Information Processing Systems, 2018.
[4] A. Dhurandhar, V. Iyengar, R. Luss, and K. Shanmugam. TIP: Typifying the Interpretability of Procedures. arXiv preprint arXiv:1706.02952, 2017.
[5] A. Dhurandhar, K. Shanmugam, R. Luss, and P. Olsen. Improving simple models with confidence profiles. In Advances of Neural Inf. Processing Systems, 2018.
[6] F. Doshi-Velez and B. Kim. Towards A Rigorous Science of Interpretable Machine Learning. Inhttps://arxiv.org/abs/1702.08608v2, 2017.
[7] D. Gunning. Explainable artificial intelligence (xai). In Defense Advanced Research Projects Agency, 2017.
[8] A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In F. Pereira, C. J. C. Burges, L. Bottou, and K. Q. Weinberger. In Advances in Neural Information Processing Systems 25, 2012.
[9] S. Lundberg and S.-I. Lee. Unified framework for interpretable methods. In Advances of Neural Inf. Proc. Systems, 2017.
[10] J. Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2000.
[11] M. Ribeiro, S. Singh, and C. Guestrin. ”Why Should I Trust You?” Ex-plaining the Predictions of Any Classifier. In ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2016.
[12] K. R. Varshney, P. Khanduri, P. Sharma, S. Zhang, and P. K. Varshney. Why interpretability in machine learning? an answer using distributed detection and data fusion theory. ICML Workshop on Human Interpretability in Machine Learning, 2018.
Related: