Dealing with Imbalanced Data in Machine Learning
This article presents tools & techniques for handling data when it's imbalanced.
As an ML engineer or data scientist, sometimes you inevitably find yourself in a situation where you have hundreds of records for one class label and thousands of records for another class label.
Upon training your model you obtain an accuracy above 90%. You then realize that the model is predicting everything as if it’s in the class with the majority of records. Excellent examples of this are fraud detection problems and churn prediction problems, where the majority of the records are in the negative class. What do you do in such a scenario? That will be the focus of this post.
Collect More Data
The most straightforward and obvious thing to do is to collect more data, especially data points on the minority class. This will obviously improve the performance of the model. However, this is not always possible. Apart from the cost one would have to incur, sometimes it's not feasible to collect more data. For example, in the case of churn prediction and fraud detection, you can’t just wait for more incidences to occur so that you can collect more data.
Consider Metrics Other than Accuracy
Accuracy is not a good way to measure the performance of a model where the class labels are imbalanced. In this case, it's prudent to consider other metrics such as precision, recall, Area Under the Curve (AUC) — just to mention a few.
Precision measures the ratio of the true positives among all the samples that were predicted as true positives and false positives. For example, out of the number of people our model predicted would churn, how many actually churned?

Recall measures the ratio of the true positives from the sum of the true positives and the false negatives. For example, the percentage of people who churned that our model predicted would churn.

The AUC is obtained from the Receiver Operating Characteristics (ROC) curve. The curve is obtained by plotting the true positive rate against the false positive rate. The false positive rate is obtained by dividing the false positives by the sum of the false positives and the true negatives.
AUC closer to one is better, since it indicates that the model is able to find the true positives.
Emphasize the Minority Class
Another way to deal with imbalanced data is to have your model focus on the minority class. This can be done by computing the class weights. The model will focus on the class with a higher weight. Eventually, the model will be able to learn equally from both classes. The weights can be computed with the help of scikit-learn.
from sklearn.utils.class_weight import compute_class_weight
weights = compute_class_weight(‘balanced’, y.unique(), y)
array([ 0.51722354, 15.01501502])You can then pass these weights when training the model. For example, in the case of logistic regression:
class_weights = {
0:0.51722354,
1:15.01501502
}lr = LogisticRegression(C=3.0, fit_intercept=True, warm_start = True, class_weight=class_weights)Alternatively, you can pass the class weights as balanced and the weights will be automatically adjusted.
lr = LogisticRegression(C=3.0, fit_intercept=True, warm_start = True, class_weight=’balanced’)Here’s the ROC curve before the weights are adjusted.
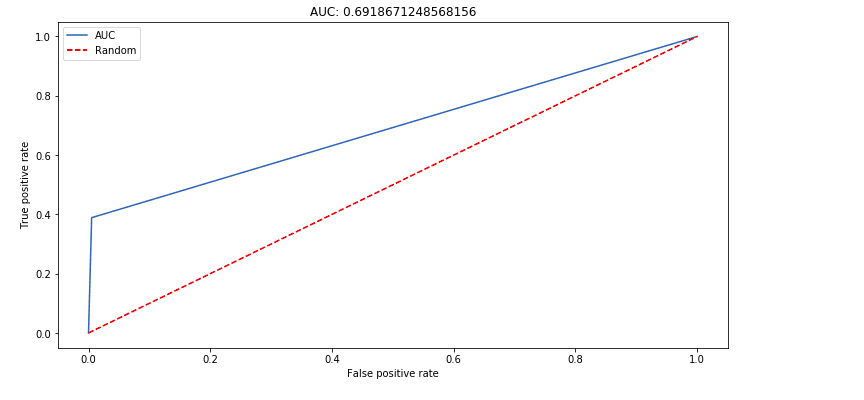
And here’s the ROC curve after the weights have been adjusted. Note the AUC moved from 0.69 to 0.87.
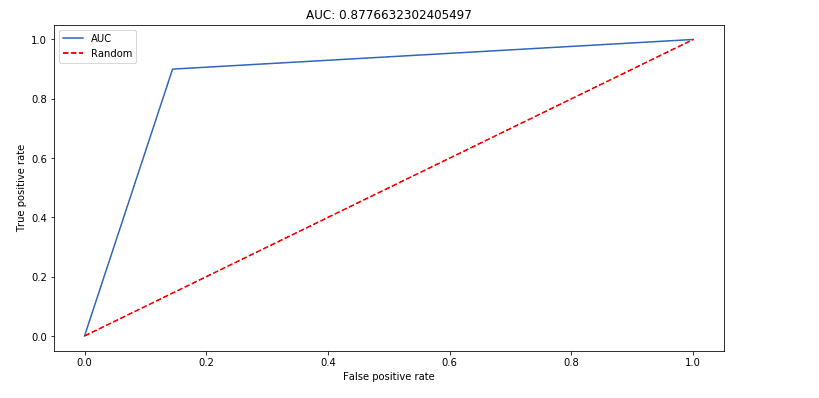
Try Different Algorithms
As you focus on the right metrics for imbalanced data, you can also try out different algorithms. Generally, tree-based algorithms perform better on imbalanced data. Furthermore, some algorithms such as LightGBM have hyperparameters that can be tuned to indicate that the data is not balanced.
Generate Synthetic Data
You can also generate synthetic data to increase the number of records in the minority class — usually known as oversampling. This is usually done on the training set after doing the train test split. In Python, this can be done using the Imblearn package. One of the strategies that can be implemented from the package is known as the Synthetic Minority Over-sampling Technique (SMOTE). The technique is based on k-nearest neighbors.
When using SMOTE:
- The first parameter is a
floatthat indicates the ratio of the number of samples in the minority class to the number of samples in the majority class, once resampling has been done. - The number of neighbors to be used to generate the synthetic samples can be specified via the
k_neighborsparameter.
from imblearn.over_sampling import SMOTEsmote = SMOTE(0.8)X_resampled,y_resampled = smote.fit_resample(X.values,y.values)pd.Series(y_resampled).value_counts()0 9667
1 7733
dtype: int64You can then fit your resampled data to your model.
model = LogisticRegression()model.fit(X_resampled,y_resampled)predictions = model.predict(X_test)
Undersample the Majority Class
You can also experiment on reducing the number of samples in the majority class. One such strategy that can be implemented is the NearMiss method. You can also specify the ratio just like in SMOTE, as well as the number of neighbors via n_neighbors.
from imblearn.under_sampling import NearMissunderSample = NearMiss(0.3,random_state=1545)pd.Series(y_resampled).value_counts()0 1110 1 333 dtype: int64
Final Thoughts
Other techniques that can be used include using building an ensemble of weak learners to create a strong classifier. Metrics such as precision-recall curve and area under curve (PR, AUC) are also worth trying when the positive class is the most important.
As always, you should experiment with different techniques and settle on the ones that give you the best results for your specific problems. Hopefully, this piece has given some insights on how to get started.
Bio: Derrick Mwiti is a data scientist who has a great passion for sharing knowledge. He is an avid contributor to the data science community via blogs such as Heartbeat, Towards Data Science, Datacamp, Neptune AI, KDnuggets just to mention a few. His content has been viewed over a million times on the internet. Derrick is also an author and online instructor. He also trains and works with various institutions to implement data science solutions as well as to upskill their staff. Derrick’s studied Mathematics and Computer Science from the Multimedia University, he also is an alumnus of the Meltwater Entrepreneurial School of Technology. If the world of Data Science, Machine Learning, and Deep Learning interest you, you might want to check his Complete Data Science & Machine Learning Bootcamp in Python course.
Original. Reposted with permission.
Related:
- How to fix an Unbalanced Dataset
- The 5 Most Useful Techniques to Handle Imbalanced Datasets
- Pro Tips: How to deal with Class Imbalance and Missing Labels