 Roadmap to Natural Language Processing (NLP)
Roadmap to Natural Language Processing (NLP)
 Roadmap to Natural Language Processing (NLP)
Roadmap to Natural Language Processing (NLP)Check out this introduction to some of the most common techniques and models used in Natural Language Processing (NLP).

Introduction
Due to the development of Big Data during the last decade. organizations are now faced with analysing large amounts of data coming from a wide variety of sources on a daily basis.
Natural Language Processing (NLP) is the area of research in Artificial Intelligence focused on processing and using Text and Speech data to create smart machines and create insights.
One of nowadays most interesting NLP application is creating machines able to discuss with humans about complex topics. IBM Project Debater represents so far one of the most successful approaches in this area.
Preprocessing Techniques
Some of the most common techniques which are applied in order to prepare text data for inference are:
- Tokenization: is used to segment the input text into its constituents words (tokens). In this way, it becomes easier to then convert our data into a numerical format.
- Stop Words Removal: is applied in order to remove from our text all the prepositions (eg. “an”, “the”, etc…) which can just be considered as a source of noise in our data (since they do not carry additional informative information in our data).
- Stemming: is finally used in order to get rid of all the affixes in our data (eg. prefixes or suffixes). In this way, it can in fact become much easier for our algorithm to not consider as distinguished words which have actually similar meaning (eg. insight ~ insightful).
All of these preprocessing techniques can be easily applied to different types of texts using standard Python NLP libraries such as NLTK and Spacy.
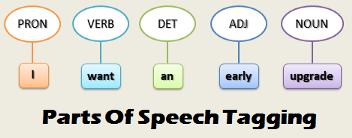
Additionally, in order to extrapolate the language syntax and structure of our text, we can make use of techniques such as Parts of Speech (POS) Tagging and Shallow Parsing (Figure 1). Using these techniques, in fact, we explicitly tag each word with its lexical category (which is based on the phrase syntactic context).
Modelling Techniques
Bag of Words
Bag of Words is a technique used in Natural Language Processing and Computer Vision in order to create new features for training classifiers (Figure 2). This technique is implemented by constructing a histogram counting all the words in our document (not taking into account the word order and syntax rules).
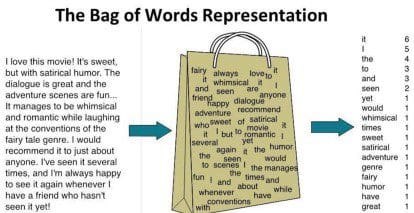
One of the main problems which can limit the efficacy of this technique is the presence of prepositions, pronouns, articles, etc… in our text. In fact, these can all be considered as words which are likely to appear frequently in our text even without necessarily being really informative in finding out what are the main characteristics and topics in our document.
In order to solve this type of problem, a technique called “Term Frequency-Inverse Document Frequency” (TFIDF) is commonly used. TFIDF aims to rescale the words count frequency in our text by considering how frequently each of the words in our text appears overall in a large sample of texts. Using this technique, we will then reward words (scaling up their frequency value) which appear quite commonly in our text but rarely in other texts, while punishing words (scaling down their frequency value) which appear frequently in both our text and other texts (such as prepositions, pronouns, etc…).
Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is a type of Topic Modelling technique. Topic Modelling is a field of research focused on finding out ways to cluster documents in order to discover latent distinguishing markers which can characterize them based on their content (Figure 3). Therefore, Topic Modelling can also be considered in this ambit as a dimensionality reduction technique since it allows us to reduce our initial data to a limited set of clusters.
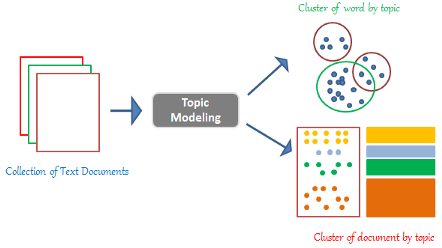
Latent Dirichlet Allocation (LDA) is an unsupervised learning technique used to find out latent topics which can characterize different documents and cluster together similar ones. This algorithm takes as input the number N of topics which are believed exists and then groups the different documents into N clusters of documents which are closely related to each other.
What characterises LDA from other clustering techniques such as K-Means Clustering is that LDA is a soft-clustering technique (each document is assigned to a cluster based on a probability distribution). For example, a document can be assigned to a Cluster A because the algorithm determines that it is 80% likely that this document belongs to this class, while still taking into account that some characteristics embedded into this document (the remaining 20%) are more likely to belong instead to a second Cluster B.
Word Embeddings
Word Embeddings are one of the most common ways to encode words as vectors of numbers which can then fed in into our Machine Learning models for inference. Word Embeddings aim to reliably transform our words into a vector space so that similar words are represented by similar vectors.
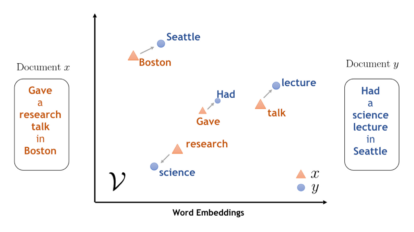
Nowadays, there are three main techniques used in order to create Word Embeddings: Word2Vec, GloVe and fastText. All these three techniques, use a shallow neural network in order to create the desired word embedding.
In case you can be interested in finding out more about how Word Embeddings works, this article is a great place where to start.
Sentiment Analysis
Sentiment Analysis is an NLP technique commonly used in order to understand if some form of text expresses positive, negative or neutral sentiment about a topic. This can be particularly useful to do when for example trying to find out what is the general public opinion (through online reviews, tweets, etc…) about a topic, product or a company.
In sentiment analysis, sentiments in texts are usually represented as a value between -1 (negative sentiment) and 1 (positive sentiment) referred to as polarity.
Sentiment Analysis can be considered as an Unsupervised Learning technique since we are not usually provided with handcrafted labels for our data. In order to overcome this obstacle, we make use of prelabeled lexicons (a book of words) which had been created to quantify the sentiment of a large number of words in different contexts. Some examples of widely used lexicons in sentiment analysis are TextBlob and VADER.
Transformers
Transformers represent the current state of the art NLP models in order to analyse text data. Some examples of widely known Transformers models are BERT and GTP2.
Before the creation of Transformers, Recurrent Neural Networks (RNNs) represented the most efficient way to analyse sequentially text data for prediction but this approach found quite difficult to reliably make use of long term dependencies (eg. our network might find difficult to understand if a word fed in several iterations ago might result to be useful for the current iteration).
Transformers successfully managed to overcome this limitation thanks to a mechanism called Attention (which is used in order to determine which parts of the text to focus on and give more weight). Additionally, Transformers made easier to process text data in parallel rather than sequentially (therefore improving execution speed).
Transformers can nowadays be easily implemented in Python thanks to Hugging Face library.
Text Prediction Demonstration
Text prediction is one of the tasks which can be easily implemented using Transformers such as GPT2. In this example, we will give as input a quote from “The Shadow of the Wind” by Carlos Ruiz Zafón and our transformer will then generate other 50 characters which should logically follow our input data.
A book is a mirror that offers us only what we already carry inside us. It is a way of knowing ourselves, and it takes a whole life of self awareness as we become aware of ourselves. This is a real lesson from the book My Life.As can be seen from our example output shown above, our GPT2 model performed quite well in creating a resealable continuation for our input string.
An example notebook which you can run in order to generate your own text is available at this link.
I hope you enjoyed this article, thank you for reading!
Contacts
If you want to keep updated with my latest articles and projects follow me on Medium and subscribe to my mailing list. These are some of my contacts details:
Bibliography
[1] Extract Custom Keywords using NLTK POS tagger in python, Thinkinfi, Anindya Naskar. Accessed at: https://www.thinkinfi.com/2018/10/extract-custom-entity-using-nltk-pos.html
[2] Comparison of word bag model BoW and word set model SoW, ProgrammerSought. Accessed at: http://www.programmersought.com/article/4304366575/;jsessionid=0187F8E68A22612555B437068028C012
[3] Topic Modeling: Art of Storytelling in NLP,
TechnovativeThinker. Accessed at: https://medium.com/@MageshDominator/topic-modeling-art-of-storytelling-in-nlp-4dc83e96a987
[4] Word Mover’s Embedding: Universal Text Embedding from Word2Vec, IBM Research Blog. Accessed at: https://www.ibm.com/blogs/research/2018/11/word-movers-embedding/
Bio: Pier Paolo Ippolito is a Data Scientist and MSc in Artificial Intelligence graduate from the University of Southampton. He has a strong interest in AI advancements and machine learning applications (such as finance and medicine). Connect with him on Linkedin.
Original. Reposted with permission.
Related:
- Accelerated Natural Language Processing: A Free Course From Amazon
- An Introduction to NLP and 5 Tips for Raising Your Game
- Getting Started with PyTorch