MLOps Is Changing How Machine Learning Models Are Developed
Delivering machine learning solutions is so much more than the model. Three key concepts covering version control, testing, and pipelines are the foundation for machine learning operations (MLOps) that help data science teams ship models quicker and with more confidence.
By Henrik Skogstrom, Head of Growth at Valohai.

Photo by Kelly Sikkema on Unsplash.
MLOps refers to machine learning operations. It is a practice that aims to make machine learning in production efficient and seamless. While the term MLOps is relatively nascent, it draws comparisons to DevOps in that it’s not a single piece of technology but rather a shared understanding of how to do things the right way.
The shared principles MLOps introduces encourage data scientists to think of machine learning not as individual scientific experiments but as a continuous process to develop, launch, and maintain machine learning capabilities for real-world use. Machine learning should be collaborative, reproducible, continuous, and tested.
The practical implementation of MLOps involves both adopting certain best practices and setting up an infrastructure that supports these best practices. Let’s look at three ways that MLOps changes how machine learning is developed: its implications for version control, how to build in safeguards, and the need to focus on the machine learning pipeline.
1. Version Control is Not Just for Code
When it comes to utilizing machine learning within an organization, version control should be a top priority. However, this concept does not apply just to the code that drives the models.
Machine learning version control should cover the code, underlying data, and parameters used when training the algorithm. This process is vital to ensure scalability and reproducibility.
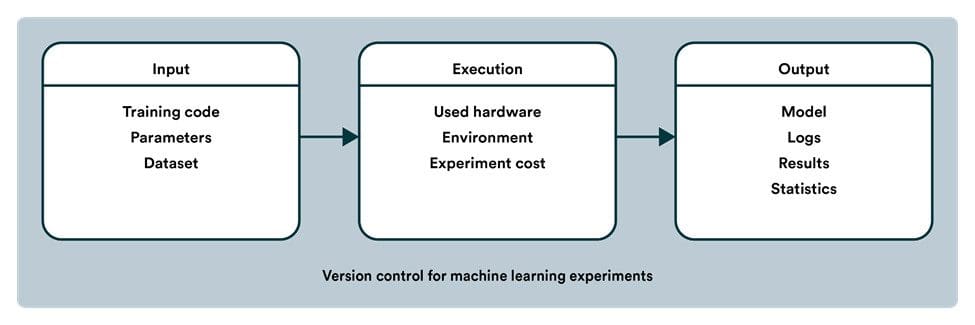
Version control for ML is not limited to just code like with traditional software. The reproducibility checklist serves as a good starting point to what your MLOps setup should be able to document.
First, let's discuss version control within the code since most data scientists are comfortable with it. Whether it is the implementation code used for system integration or the modeling code that allows you to develop machine learning algorithms, there should be clear documentation of any changes made. This area is most often well covered by the use of Git, for example.
Version control should also be applied to the data used to train the models. Scenarios and users are constantly changing and adapting, so it makes sense that your data will not always look the same either.
This constant change means that we always have to retrain models and validate that they are still accurate with new data. As a result, proper version control is needed to maintain reproducibility.
Not only does the data we use to build models evolve, but so does the metadata. Metadata refers to information collected about the underlying data and the model training – it tells us how your model training process went. Was the data used as expected? What kind of accuracy did the model reach?
The metadata can change even when the underlying data has not. Metadata needs to be tightly versioned because you’ll want to have a benchmark for subsequent times you train models.
Lastly, there must be proper version control for the model itself. As a data scientist, your goal is to continuously improve machine learning models’ accuracy and reliability, so the evolving algorithm needs to have its own versioning. This is often referred to as a model registry.
The MLOps practice encourages version control for all components mentioned above as a standard practice, and most MLOps platforms make this easy to implement. With proper version control, you ensure reproducibility at all times, which is crucial for governance and knowledge sharing.
2. Build Safeguards into the Code
When it comes to building safeguards into the machine learning process, they should be in the code – not in your head!
Strive to avoid manual or inconsistent processes at all costs. All procedures for collecting data, data testing, and model deployment should be written into the code – rather than process documentation – so that you can be confident that every iteration of a model will adhere to the required standards.
For example, the way that you train a machine learning model matters – a lot. As a result, any small variation in how a model is trained can lead to problems and inconsistencies in the predictions it makes. This risk is why it is essential to build these safeguards directly into the code.
Data testing is often done in an ad-hoc way, but it should be programmatic.
There should be code written into the machine learning pipeline that safeguards how the training data should look (pre-train tests) and how the trained model should perform (post-train tests). This includes having parameters for what the expected predictions should be – this will give you peace of mind that the production models are following all of the rules you set forth.
The great thing about implementing an MLOps platform is that all of these steps are self-documenting and reusable – at least to the level that code is self-documenting. The safeguards can be easily repurposed for other machine learning use-cases, and the same standards, e.g., model accuracy, can be applied.
3. The Pipeline is the Product – Not the Model
The third MLOps concept that should be recognized is that the machine learning pipeline is the product – not the model itself. This realization is often characterized by a maturity model where an organization moves from a manual process to an automated pipeline.
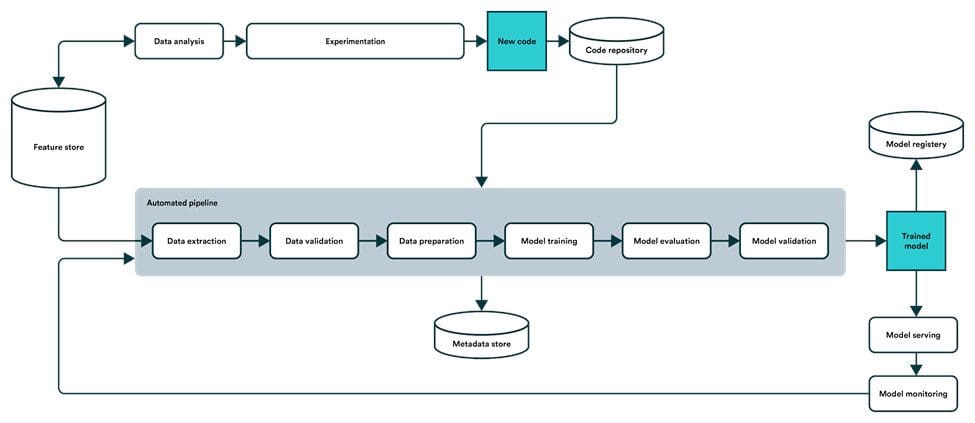
The end-goal for a machine learning pipeline is to enable a self-healing ML system.
The machine learning model is important to overcome business challenges and satisfy the organization’s immediate needs. However, it is necessary to acknowledge the model is only temporary, unlike the system that produces it.
The underlying data that supports the model will change rapidly, and the model will drift. This means that eventually, the model will have to be retrained and adjusted to provide accurate outcomes in a new environment.
As a result, the pipeline that produces accurate and effective machine learning models should be the product that data scientists focus on creating. So, what exactly is a machine learning pipeline?
Without MLOps and an established machine learning pipeline, updated the models will be time-consuming and difficult. Rather than completing these tasks ad-hoc and only addressing issues as they arise, a pipeline eliminates this problem. It lays out a clear framework and governance for model updates and changes.
The machine learning pipeline includes collecting and preprocessing data, training a machine learning model, moving it into production, and continuously monitoring it to re-trigger training when accuracy falters. A well-built pipeline helps you scale this process throughout your organization so that you can maximize the use of production models and ensure these capabilities always perform up-to-par.
A developed machine learning pipeline also allows you to exercise control over how models are implemented and used within the business. It also improves communication across departments and will enable others to review the pipeline – rather than manual workflows – to determine if changes need to be made. Similarly, it reduces production bottlenecks and allows you to make the most out of your data science capabilities.
To summarize, there are three essential MLOps concepts that everyone should understand.
- Version control is necessary throughout the entire machine learning process. This includes not just code but data, parameters and metadata as well.
- Safeguards should be set up to work automatically – don’t risk your machine learning models’ outcomes by relying on manual or inconsistent processes.
- Lastly, the pipeline is the product rather than the machine learning model. A developed pipeline is the only way to support production ML long-term.
Bio: Henrik Skogström spearheads the Valohai MLOps platform’s adoption and writes extensively about the best practices around machine learning in production. Before Valohai, Henrik worked as a product manager at Quest Analytics to improve healthcare accessibility in the US. Launched in 2017, Valohai is a pioneer in MLOps and has helped companies such as Twitter, LEGO Group, and JFrog get their models to production quicker.
Related: