IBM Uses Continual Learning to Avoid The Amnesia Problem in Neural Networks
Using continual learning might avoid the famous catastrophic forgetting problem in neural networks.

I recently started a new newsletter focus on AI education andalready has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

I often joke that neural networks suffers from a continuous amnesia problem in the sense that they every time they are retrained they lost the knowledge accumulated in previous iterations. Building neural networks that can learn incrementally without forgetting is one of the existential challenges facing the current generation of deep learning solutions. Over a year ago, researchers from IBM published a paper proposing a method for continual learning proposing that allow the implementation of neural networks that can build incremental knowledge.
Neural networks have achieved impressive milestones in the last few years from beating Go to multi-player games. However, neural network architectures remain constrained to very specific domains and unable to transition its knowledge into new areas. Furthermore, current neural network models are only effective if trained over large stationary distributions of data and struggle when training over changing non-stationary distributions of data. In other words, neural networks can effectively solve many tasks when trained from scratch and continually sample from all tasks many times until training has converged. Meanwhile, they struggle when training incrementally if there is a time dependence to the data received. Paradoxically, most real world AI scenarios are based on incremental, and not stationary, knowledge. Throughout the history of artificial intelligence(AI), there have been several theories and proposed models to deal with the continual learning challenge.
Catastrophic Forgetting and the Stability-Plasticity Dilemma
The limitation of neural networks of being unable to build knowledge incrementally over large periods of time if very well described in the “catastrophic forgetting” thesis. Originally coined by Michael McCloskey and Neal J.Cohen in a 1989 paper, the thesis details a phenomenon where neural networks tend to quickly unlearn old knowledge without repetition to reinforce the training. Specifically, catastrophic forgetting occurs when a network trained sequentially on multiple tasks because the weights in the network that are important for task A are changed to meet the objectives of task B.
In what can be considered the simplest manifestation of catastrophic forgetting, McCloskey and Cohen trained a standard backpropagation neural network on a single training set consisting of 17 single-digit ones problems (i.e., 1 + 1 through 9 + 1, and 1 + 2 through 1 + 9) until the network could represent and respond properly to all of them. The error between the actual output and the desired output steadily declined across training sessions, which reflected that the network learned to represent the target outputs better across trials. Next they trained the network on a single training set consisting of 17 single-digit twos problems (i.e., 2 + 1 through 2 + 9, and 1 + 2 through 9 + 2) until the network could represent, respond properly to all of them. They noted that their procedure was similar to how a child would learn their addition facts. Following each learning trial on the twos facts, the network was tested for its knowledge on both the ones and twos addition facts. Like the ones facts, the twos facts were readily learned by the network. However, McCloskey and Cohen noted the network was no longer able to properly answer the ones addition problems even after one learning trial of the twos addition problems. The output pattern produced in response to the ones facts often resembled an output pattern for an incorrect number more closely than the output pattern for an incorrect number. Furthermore, the problems 2+1 and 2+1, which were included in both training sets, even showed dramatic disruption during the first learning trials of the twos facts.
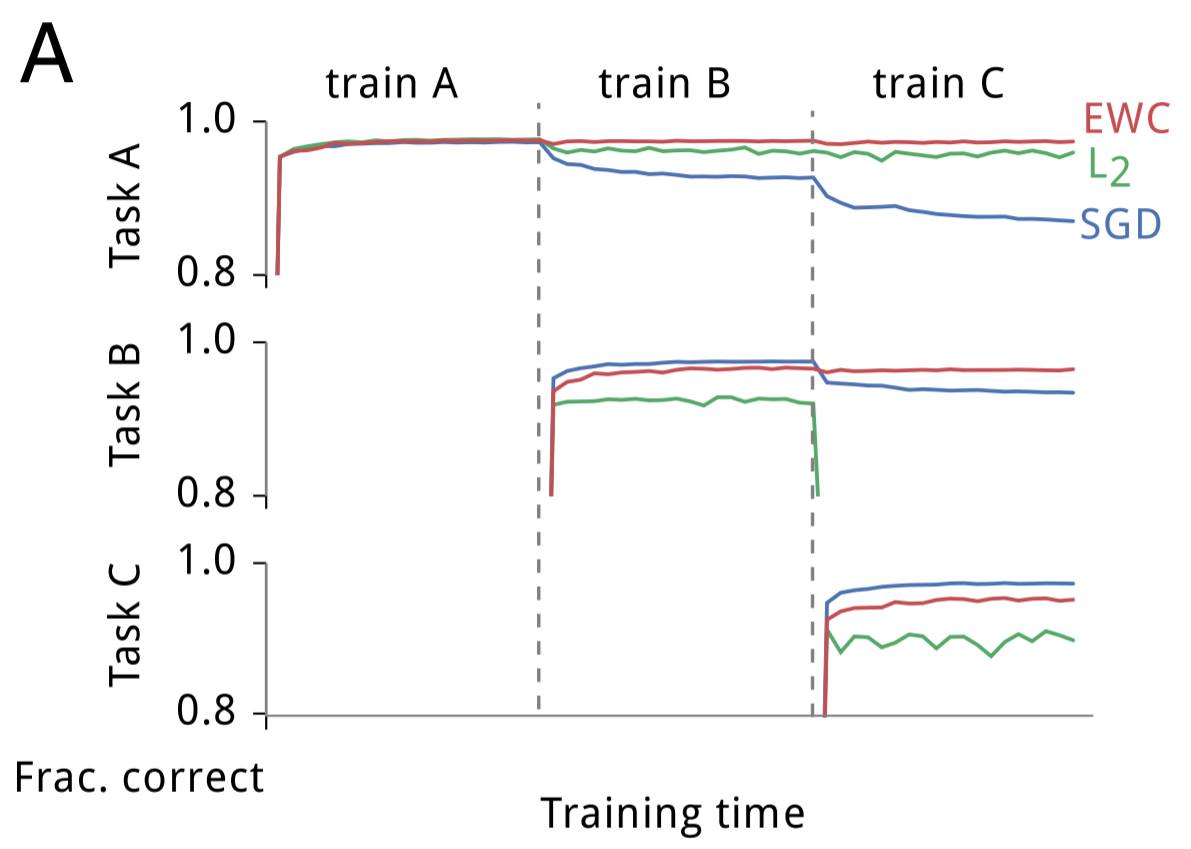
The catastrophic forgetting phenomenon is a special case of another challenge in neural network training known as the “stability-plasticity dilemma”. This dilemma describes the friction between incremental, parallel learning and plasticity. Too much plasticity will result in previously encoded data being constantly forgotten, whereas too much stability will impede the efficient coding of this data at the level of the connections between neurons. In other words, incremental learning in neural networks requires the right balance between forgetting and stability. Reducing “forgetting” may improve network “stability” but it is not really addressing the greater problem if it comes at the cost of “plasticity,” as it so often does.
In their research, the IBM team tackled the challenge of continuous learning in neural networks by presenting a novel variation of the catastrophic failure and the stability-plasticity dilemma.
The Transfer-Inference Trade Off
The core of IBM’s approach to enable continuous learning is an alternative to the dilemmas outlines in the previous section known as the Transfer-Inference-Trade- Off. From some perspectives, the stability-plasticity dilemma is solely concerned with how new learning disrupts old learning. The Transfer-Inference Trade Off takes a novel approach by focusing on weight sharing in both forward and backward directions. More specifically, the Transfer-Inference Trade manifest itself when deciding on the degree to which different examples should be learned using the same weights. If two examples are learned using different weights, there is low potential for both interference and transfer between examples while learning either example. This is optimal if the two examples are unrelated, but is sub-optimal if the two examples are related as it eliminates the opportunity for transfer learning. In contrast, if two examples are learned using the same weights, there is high potential for both transfer and interference. This is optimal if the examples are related, but can lead to high interference if they are not related.
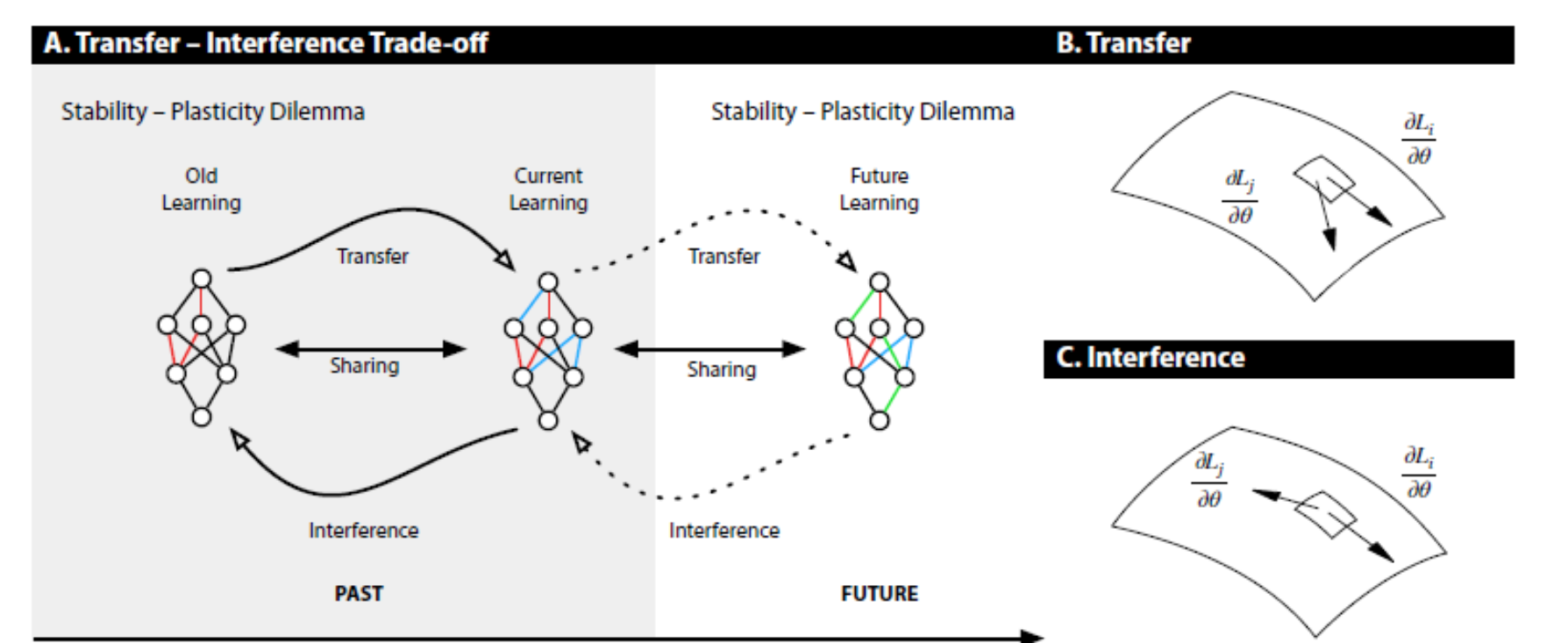
The symmetric knowledge view presented by the Transfer-Inference Trade Off is crucial to solve the continual learning problem. In general, if a neural network is trained to share its weights across examples based on interactions between the gradients of examples it has seen so far, this should effectively make it easier to perform continual learning going forward. This will happen to the extent that what the model learns about balancing weight sharing generalizes. This view also frames the continual learning problem as a meta-learning exercise as the goal should be to modify the learning of a model to affect the dynamics of transfer and interference in a general sense. To the extent that a meta-learning model is able to generalize into the future, this should make it easier for our model to perform continual learning in non-stationary data.
Following the Transfer-Inference Trade Off thesis, IBM created a new method for continual learning that combines two of the hottest areas of research in the deep learning world.
MER
Meta-Experience-Replay(MER) is a new framework that combines meta-learning and experience replay to achieve continual learning. The first iteration of MER relied on a state-of-the-art meta-learning model created by OpenAI called Reptile. Conceptually, meta-learning is the area of deep learning that focuses on processes that “learn how to learn”. A meta-learning algorithm typically takes in a distribution of tasks, where each task is a learning problem, and it produces a quick learner — a learner that can generalize from a small number of examples.
MER combines meta-learning with popular experience-replay techniques which are the gold standard for handing non-stationary data in deep learning systems. The central feature of experience replay is keeping a memory of examples seen that is interleaved with the training of the current example with the goal of making training more stable.
At a high level, the combination of meta-learning and experience replay offers a unique take to solve the continual learning problem based on the Transfer-Inference Trade Off. The goal of the meta-learning portion will be to produce a learning method that maximizes transfer while minimizes inference. The experience replay portion of it helps to balance learning across both the previously seen examples as well as new ones.

The IBM team tested MER across different non-stationary datasets including games such as Catcher and Flappy Bird. In the case of Flappy Brid, MER was trained to navigate through pipes while making the pipe gap the bird needs to get through smaller and smaller gaps as the game progresses. This environment results particularly challenging to achieve continual reinforcement learning give the sudden changes to the dynamics of gameplay that really tests the agent’s ability to detect changes in the environment without supervision. In the experiments MER outperform standard neural network models as clearly shown in the following figure:

The main contribution of the IBM paper was to frame continual learning as a trade off between transfer and inference. That perspective allowed the combination of meta-learning and experience replay techniques to provide a unique experience to general purpose, continual learning problems. IBM complemented the research paper with an open source implementation of the MER algorithm available in GitHub.
Original. Reposted with permission.
Related:
- Microsoft Explores Three Key Mysteries of Ensemble Learning
- Deep Learning Pioneer Geoff Hinton on his Latest Research and the Future of AI
- Microsoft Uses Transformer Networks to Answer Questions About Images With Minimum Training