Microsoft Explores Three Key Mysteries of Ensemble Learning
A new paper studies three key puzzling characteristics of deep learning ensembles and some potential explanations.

I recently started a new newsletter focus on AI education andalready has over 50,000 subscribers. TheSequence is a no-BS( meaning no hype, no news etc) AI-focused newsletter that takes 5 minutes to read. The goal is to keep you up to date with machine learning projects, research papers and concepts. Please give it a try by subscribing below:

Ensemble learning is one of the oldest and less-understood techniques used to improve the performance of deep learning models. The theory behind ensemble learning is very simple: the performance of a group of independently-trained neural networks should outperform the best in the group in the long term. Furthermore, we also know that the performance of an ensemble of models can be transferred to a single model using a technique known as knowledge distillation. The world of ensemble learning is super exciting, except, that we don’t quite understand it. Recently, Microsoft Research published a groundbreaking paper that tries that shade some light into the magic of ensembles by understanding three fundamental mysteries of the space.
Microsoft Research works tries to understand the following two theoretical questions about ensemble learning:
- 1) How does ensemble improve the test-time performance in deep learning when we simply average over a few independently trained neural networks?
- 2) How can such superior test-time performance of ensemble be later “distilled” into a single neural network of the same architecture, simply by training the single model to match the output of the ensemble over the same training data set?
The answer to those theoretical questions runs into what Microsoft Research, somewhat theatrically, likes to call the three mysteries of ensemble learning:
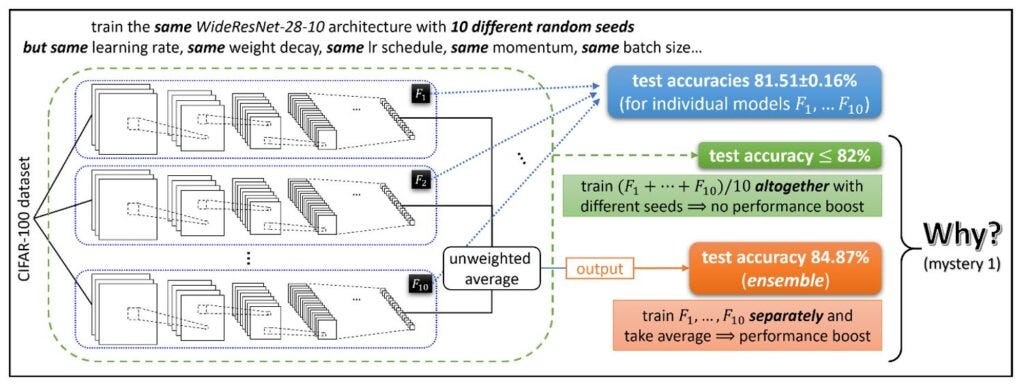
Mystery 1: Ensemble
The first mystery of ensemble learning is related to the performance boost. Given a set of neural networks N1, N2…NM, an ensemble that simply takes an average of the outputs is likely to produce a significant performance boost. However that performance doesn’t materialize when training (N1 + N2 +…Nm)/M. Puzzling….
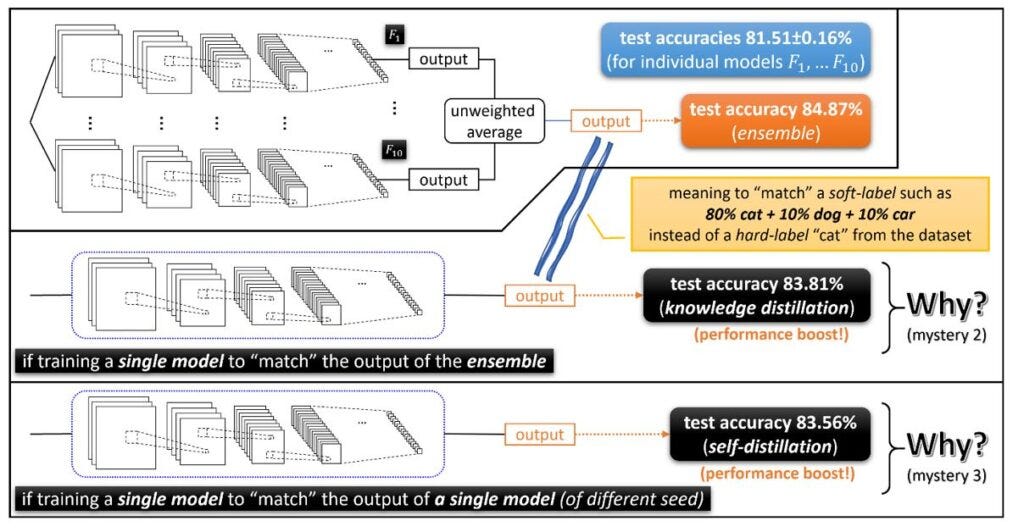
Mystery 2: Knowledge Distillation
Ensemble models are high performance but ridiculously expensive and slow to run. Knowledge distillation is a technique in which a single model can be trained to match the performance of the ensemble. The success of knowledge distillation methods leads to more the second mystery of ensembles. Why does matching the outputs of the ensemble produces better test accuracy compared to matching the true labels?
Mystery 3: Self-Distillation
The third mystery of ensemble is very related to the second one but even more puzzling. Knowledge distillation shows that a smaller model can match the performance of a larger ensemble. A parallel phenomenon known as self-distillation is even more puzzling. Self-distillation is based on performing knowledge distillation against individual models which also increases the performance! Basically, self-distillation is based on training the same model using itself as a teacher. Why does that approach produces a performance boost remains a mystery.
Some Answers
Microsoft Research conducted all sorts of experiments to understand some of the aforementioned mysteries of ensemble learning. The initial work produced some interesting results.
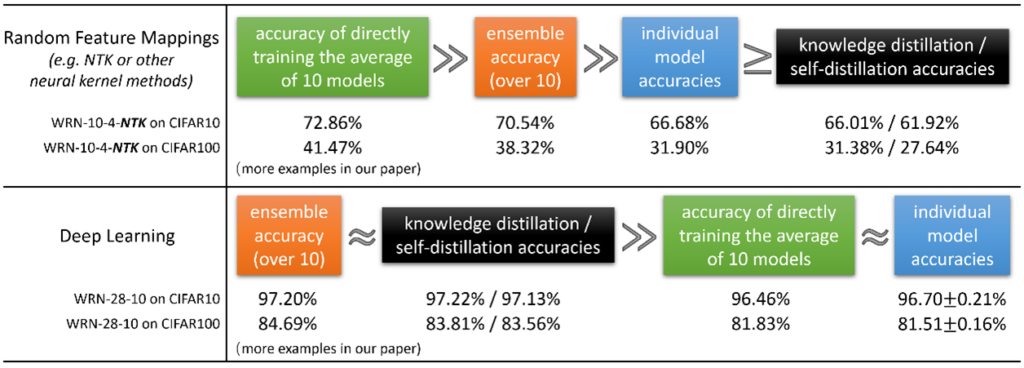
1) Deep Learning Ensembles vs. Feature Mapping
The best-known form of ensemble learning is what is called random feature mappings in which models are trained in random number of features. That type of technique works well in linear models and is very well understood so that it can be used as a baseline to analyze the performance of deep learning ensembles. The initial results of Microsoft Research experiments showed that deep learning ensembles behaved very similarly to feature mappings. However, knowledge distillation doesn’t quite work the same.
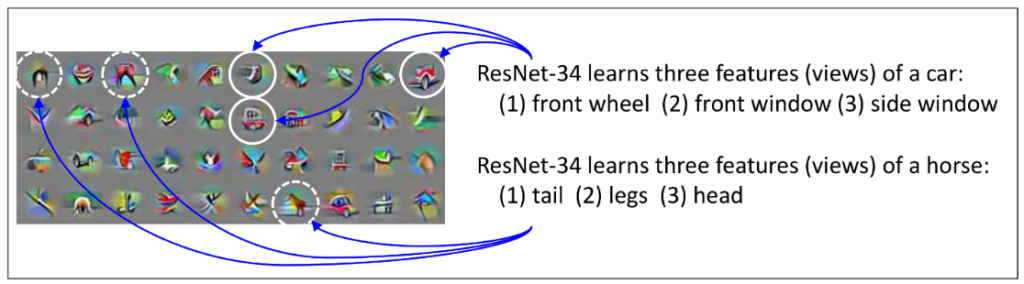
2) Multi-views Datasets are Necessary for Ensembles to work
One of the most revealing results of the Microsoft Research study is based on the nature of the data. A multi-view dataset is based on a structure where each class of the data has multiple view features. For instance, a car image can be classified as a car by looking at the headlights, the wheels, or the windows. Microsoft Research shows that datasets with multi-view structures are likely to boost the performance of ensemble models whereas datasets without that structure does not have the same impact.
The Microsoft Research paper is one of the most advanced work in deep learning ensembles in the last few year. The paper covers many other findings but this summary should give you a very concrete idea of the main contributions.
Original. Reposted with permission.
Related:
- XGBoost: What it is, and when to use it
- Microsoft Uses Transformer Networks to Answer Questions About Images With Minimum Training
- Implementing the AdaBoost Algorithm From Scratch