By Hubert Baniecki, Research Software Engineer at MI2DataLab

There are various adversarial attacks on machine learning models; hence, ways of defending, e.g. by using Explainable AI methods. Nowadays, attacks on model explanations come to light, so does the defense to such adversary. Here, we introduce fundamental concepts related to the domain. A further reference list is available at https://github.com/hbaniecki/adversarial-explainable-ai.
When considering an explanation as a function of model and data, there is a possibility to change one of these variables to achieve a different result.
Attack on explanation via data change

The first concept is to manipulate model explanations via data change. Dombrowski et al. [2019] showcase that perturbed images produce arbitrarily made visual explanations (e.g. LRP, PA, IG). Looking at the above image, we may already deduce that a target explanation is needed for the attack.
To achieve the fooling, the authors propose to optimize a specific loss function
Loss ~ distance(manipulated explanation, target explanation) +
γ * distance(manipulated prediction, original prediction)
where the first term denotes an aim for the target. In contrast, the second term serves as a controlling parameter, not to change models’ outcome. The manipulation method requires calculating the gradient of models’ output with respect to the input; thus, neural networks are considered.
Several metrics are used to measure the success of an attack so that various explanations can be evaluated. These findings raise awareness about the explainability use and overall uncertainty of deep learning solutions. Finally, methods for the construction of more robust explanations are proposed to overcome the issue. All this without changing the model.
Attack on explanation via model change

Another idea is to fool explanations via model change. Heo et al. [2019] propose fine-tuning of a neural network to undermine its interpretability capabilities. The assumption is to alter models’ parameters without a drop in performance. The example shows how explanations may differ after the attack.
Similarly, to achieve the manipulation, an objective function is proposed
Objective ~ performance of the manipulated model +
λ*distance(manipulated explanations, target explanations)
where the first term controls the models’ performance change, while the second term denotes an aim for the target. There are multiple fooling types proposed to define the second term, depending on the strategy, objective.
Passive fooling makes explainability methods generate uninformative results, while active fooling intentionally makes these methods generate false explanations. Both of the strategies are evaluated with a novel Fooling Success Rate metric, which uses empirically defined thresholds for determining whether model explanations are successfully fooled or not.
Follow the references for compelling views on both of these approaches, but how about a defense to such adversary?
Defense from attacks on model explanations
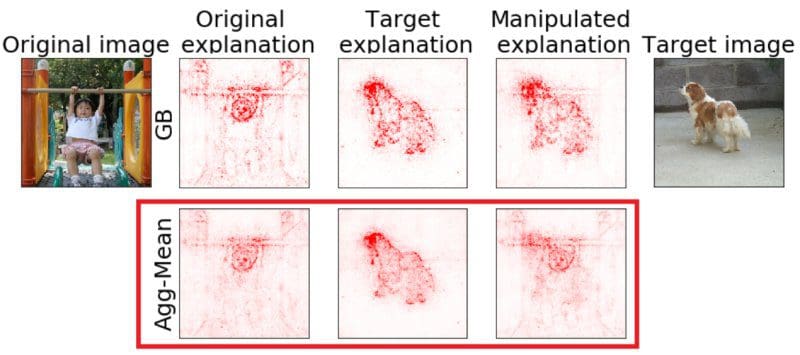
Rieger and Hansen [2020] present a defense strategy against the attack via data change of Dombrowski et al. [2019]. The main idea is to aggregate various model explanations, which produces robust results. The simple strategy doesn’t change the model and is computationally inexpensive.
Considered explainability methods for the aggregation are Layerwise Relevance Propagation, Saliency Mapping, and Guided Backprop. Each of these explanations is normalized before applying the mean
Agg-Mean = mean(LRP, SM, GB)
so that each input sums up to one. In this case, no weighted average is required, following the assumption that all individual explanation methods are equally important. Authors conduct experiments showing that the aggregation presents itself as the most robust against the attacks.
While Explainable AI becomes more and more popular, there should be a requirement to evaluate explainability performance, the same as we evaluate model performance. As shown in recent works, an estimation of models’ behavior may be a black-box itself.
For further reading on this topic consider a blog post:
Be careful! Some model explanations can be fooled. | ResponsibleML
Bio: Hubert Baniecki is a Research Software Engineer, developing R & Python tools for Explainable AI, and researching ML in the context of interpretability and human-model interaction.
Original. Reposted with permission.
Related:
- tensorflow + dalex = :) , or how to explain a TensorFlow model
- Production Machine Learning Monitoring: Outliers, Drift, Explainers & Statistical Performance
- Deep learning doesn’t need to be a black box